兴坤 发自 凹非寺
量子位 报道 | 公众号 QbitAI
谷歌新推出了弱监督看图说话模型SimVLM,能够轻松实现零样本学习(zero-shot)任务迁移。
从文字描述图像到回答图片相关问题,模型无需微调也能样样精通。

对于一般的视觉语言预训练(VLP)模型,训练数据集中要求包含大量精准标签。而模型的任务迁移,则需要针对特定任务重新进行数据集的标签标注。
总结下来,就是标注数据集不仅耗时耗力,还不能多任务通用。
能不能开发出一种又简单又万能的VLP模型呢?
谷歌新开发的这款模型使用了弱监督学习进行模型训练,通过利用大量的弱对齐图像-文本对进行建模,简化了VLP的训练流程,大大降低了训练的复杂性。
SimVLM使用前缀语言建模的单一目标进行端到端训练,并直接将原始图像作为输入。这些设置允许模型对大规模的弱标记数据集进行利用,从而能够更好地实现零样本学习泛化效果。
SimVLM模型的预训练过程采用了前缀语言建模(PrefixLM)的单一目标,接受序列的前缀作为输入,通过模型解码器来预测其延续的内容。
对于数据集中的图像-文本对,图像序列可视作其文本描述的前缀。
这种方法可以简化训练过程,最大限度地提高模型在适应不同任务设置方面的灵活性和通用性。
模型的主干网络,则使用了在语言和视觉任务上均表现突出的Transformer架构。
对输入的原始图像数据提取上下文patch,这里采用了ResNet卷积网络。
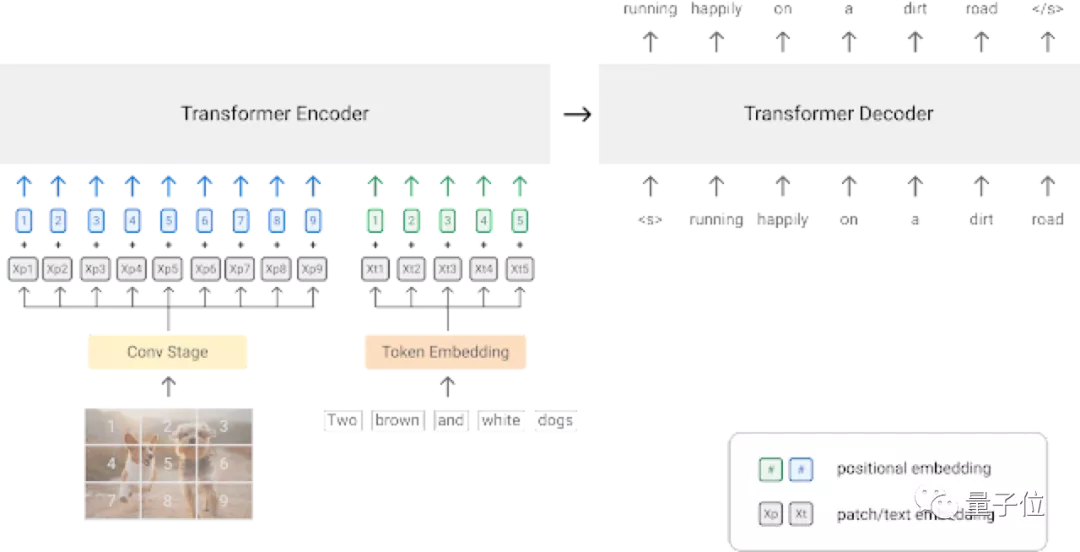
如上图所示:视觉模态中,图片被分割成多个patch,然后压缩为一维序列。文本模态语句则被映射到了一个表征向量中。
本模型使用了包含大约1.8B噪声的图像-文本对ALIGN训练集进行预训练,以此来实现更好的零样本学习泛化能力。
为了补偿训练集中的噪声影响,训练模型另外还使用了共800G的Colossal Clean Crawled Corpus (C4)数据集。
模型的预训练完成后,需要在多模式任务中对模型进行微调,以测试性能。
这里用到的多模式任务有:VQA、NLVR2、SNLI-VE、COCO Caption、NoCaps和Multi30K En-De。
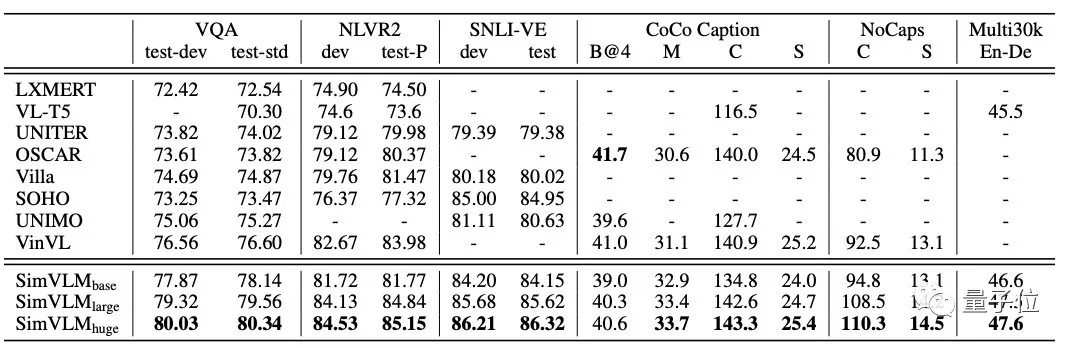
将SimVLM模型与现有的功能完善的模型进行比较,测试结果如上表所示,参与评估的SimVLM模型还包括了三种不同规模:8600万参数、3.07亿参数和6.32亿参数。
跨模式任务的测试结果中,SimVLM模型的性能表现最好(数据越大越好),除了CoCo Caption的B@4指标,在其他任务上都取得了新的SOTA结果,充分证明了该模型的先进性。
SimVLM模型在跨模式任务测试中可以取得不错的性能表现,那么它能否顺利执行零样本跨模态转移呢?
预训练的SimVLM模型仅对文本数据进行微调或完全不进行微调,通过图像字幕、多语言字幕、开放式VQA和视觉文本生成等任务,对模型进行测试。
测试结果如下图所示:

给定图像和文本提示,预训练模型无需微调即可预测图像的内容。

除此之外,未进行过微调的模型在德语字幕生成、数据集外的答案生成、基于图像内容的文字描述、开放式视觉问题回答等应用上均有不错的表现。
为了量化SimVLM的零样本学习性能,这里采用了预训练的固化模型在COCO Caption和NoCaps上进行解码,然后与监督标准基线(Sup.)进行比较。
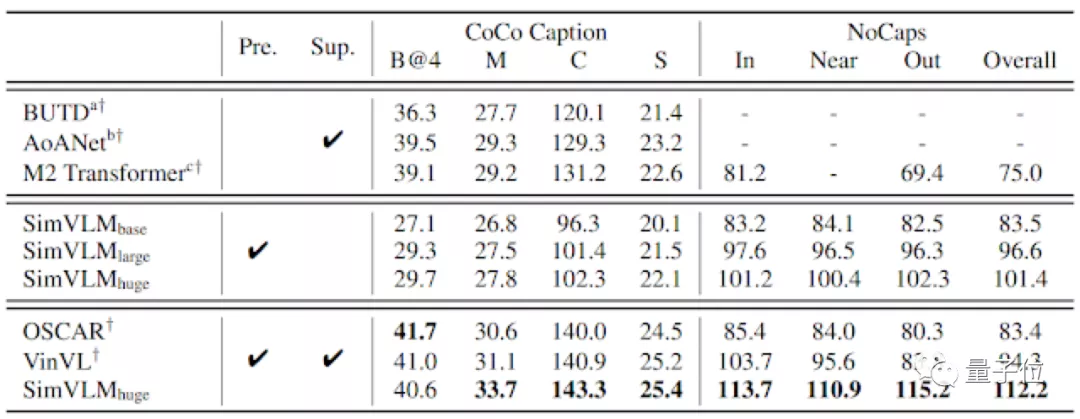
从结果对比上来看,即使没有监督微调,SimVLM也可以达到有监督的训练质量水平。
本研究的第一作者是谷歌学生研究员王子瑞,现就读于卡内基梅隆大学,曾以第一作者身份在ICLR、EMNLP、CVPR等顶会上发表了多篇论文。

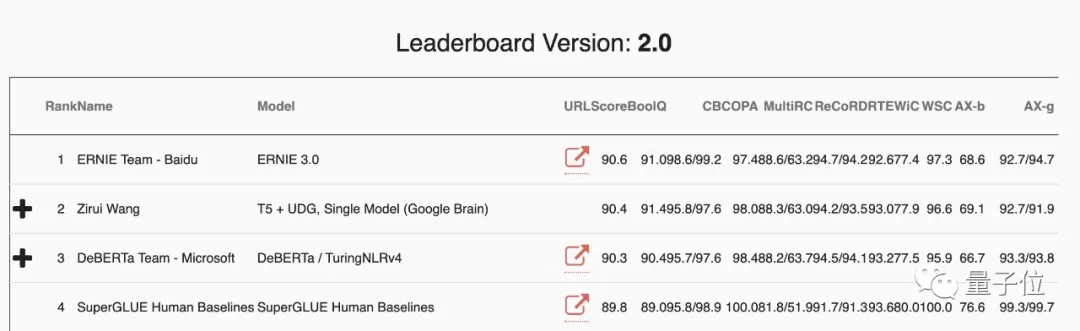
截止到2020年12月20日,他在SuperGLUE数据集上获得了第一个超过人类得分的SOTA性能(分数超过90),目前则被百度团队赶超,位居第二。
这一次开发的SimVLM也在6个视觉语言基准测试中达到了单模型SOTA性能,并实现了基于文本引导的零样本学习泛化能力。
参考链接:
https://arxiv.org/abs/2108.10904
https://ai.googleblog.com/2021/10/simvlm-simple-visual-language-model-pre.html
http://www.cs.cmu.edu/~ziruiw/
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态