训练万亿参数级别的大模型,需要多大规模的算力?在今日凌晨进行的Nvidia GTC 2024主旨演讲中,英伟达创始人兼首席执行官黄仁勋在现场做了一道数学题。以AI target=_blank class=infotextkey>OpenAI最先进的1.8万亿参数大模型为例,该模型需要几万亿的Token进行训练。万亿参数与数万亿的Token相乘,就是训练OpenAI最先进大模型所需的计算规模。黄仁勋现场估算的计算规模为3×1025,如果用一颗petaflop(每秒钟进行1千万亿次运算)量级的GPU进行运算,需要1000年的时间才能完成。
另外需要注意的是,在Transformer发明后,大模型的规模正在以惊人的速度扩展,平均每6个月就会翻倍,这意味着万亿级别参数并不是大模型的上限。
在这种趋势下,黄仁勋相信,生成式AI的迭代和发展,需要更大的GPU、更快的GPU互连技术、更强大的超级计算机内部连接技术,以及更庞大的超级计算机巨型系统。
本次GTC 2024发布的Blackwell GPU,被黄仁勋描述为“非常非常大的GPU”,在物理意义上,它确实是当前面积最大的GPU,由两颗Blackwell裸片拼接而成,采用台积电4nm工艺,拥有2080亿晶体管, AI性能达到20 petaflops。相比英伟达Hopper,Blackwell GPU的AI性能提升5倍,片上存储提升4倍。

黄仁勋展示Blackwell GPU(左)和Hopper GPU(右)
除了更大的GPU,Blackwell架构还包含多项计算加速和安全防护技术。
Blackwell采用的第二代Transformer引擎,可以对AI运算的浮点数精度进行动态缩放,目前覆盖了FP6和FP4。在这两种精度下,Blackwell相较Hopper的算力分别实现了2.5倍和5倍的提升。
在大量GPU共同工作时,需要保证GPU之间的信息能够进行同步和共享,这就需要GPU之间的高速连接。为此,英伟达将NVLink技术更新至第五代,为每块GPU提供了1.8TB/s的双向吞吐量,确保GPU之间的高速通信。
在大规模部署AI的过程中,由于组件众多,持续运行的能力变得至关重要。为保证运行周期能够延续更久,Blackwell架构包含了可靠性引擎RAS,该引擎通过AI对可靠性、安全性等相关问题进行预测和预先诊断,在稳固运行的同时进一步降低运营成本。“这就像每个芯片都配备了高级测试仪一样。”黄仁勋比喻道。
同时,英伟达也在Blackwell架构中增加了机密计算功能来强化AI的安全性。在医疗、金融服务等高度重视数据隐私的行业中保护AI模型和客户数据,“我们现在有能力对数据进行加密,使它们被计算时处在一个可信的引擎环境中。”黄仁勋表示。
考虑到在高速计算中数据的转移效率,Blackwell架构设置了解压缩引擎。据了解,该高线速压缩引擎将数据移入和移出计算机的速度提升了20倍,有效减少计算机运算时的算力闲置。

英伟达Blackwell架构所使用的六种技术
基于以上技术,英伟达Blackwell相比前代产品Hopper,能以更少的芯片、更低的功耗完成对OpenAI 1.8万亿参数大模型的一次训练。据黄仁勋测算,如果用Hopper进行训练,需要约8000颗GPU,耗时约90天,产生约15兆瓦的功耗。而用Blackwell进行训练,仅需2000颗GPU,耗时同样为90天,产生约4兆瓦的功耗。
另一个值得关注的点,是Blackwell架构的拓展性。从一颗GPU到超级芯片、系统再到超级计算机——基于英伟达网络、全栈 AI 软件和存储技术,计算集群中的超级芯片数量可扩展至数万个。
与Hopper架构类似,Blackwell支持通过NVLink技术与CPU互联构建超级芯片。将2颗Blackwell GPU与1颗Grace CPU通过NVlink连接,就构成了GB200超级芯片。与英伟达H100 Tensor Core GPU 相比,GB200在大语言模型推理工作负载方面的性能提升了约30倍。
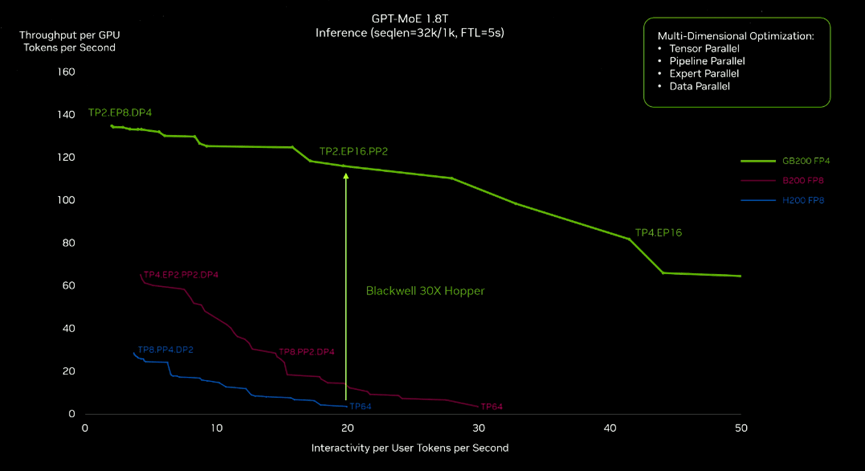
GB200的性能是H100的30倍
若进一步拓展,36块GB200加速卡——包含72颗Blackwell GPU和36颗Grace CPU,将构成DGX GB200系统。
若将8个或以上DGX GB200通过英伟达Quantum InfiniBand 网络连接,就组成了DGX SuperPOD人工智能超级计算机(包含至少576块Blackwell GPU和288颗Grace CPU),在FP4精度下可提供11.5 exaflops(每秒进行1018次运算)的 AI 计算性能和 240 TB 的快速显存。

英伟达超级AI计算机DGX SuperPOD
有意思的是,英伟达与OpenAI结缘,就始于第一代DGX人工智能超级计算机,黄仁勋表示,至今还记得将DGX-1拎在手里递给OpenAI团队的重量。
“2016年,我们发明了一种全新类型的计算机,并称之为DGX-1。我将第一台DGX-1亲手交给一家初创公司,它位于旧金山,名为OpenAI。”黄仁勋说。彼时,DGX-1由8块GPU连接在一起,拥有170teraflops的算力。而今年2月,英伟达揭晓的基于DGX Super POD架构的AI超级计算机EOS,由10752块英伟达H100 GPU连接在一起,提供总共18.4 exaflops的FP8 AI效能。
除了基于GPU的架构迭代和集群拓展应对算力挑战,英伟达还在尝试从芯片制造环节入手,提升芯片制造效率并助力芯片微缩工艺的发展。黄仁勋在主旨演讲中表示,英伟达推出了计算光刻软件库cuLitho,为了更好地制造芯片,需要将光刻技术推向极限,台积电已经宣布将cuLitho投入生产。据悉,EDA厂商新思科技正在将cuLitho集成到软件、制造工艺和系统中,台积电也将cuLitho投入到生产中,以推动半导体微缩工艺的发展。记者了解到,cuLitho计算光刻平台能够帮助设备和制造厂商调整、优化光刻过程中的参数,以实现更高的制造精度。Synopsys 总裁兼首席执行官 Sassine Ghazi 表示,与台积电、英伟达围绕计算光刻的合作,对于实现埃米级微缩至关重要。
作者丨张心怡 王信豪
编辑丨赵晨
美编丨马利亚
监制丨连晓东