Llama 3发布刚几天,微软就出手截胡了?

今天发布的Phi-3系列小模型技术报告,引起AI圈热议。

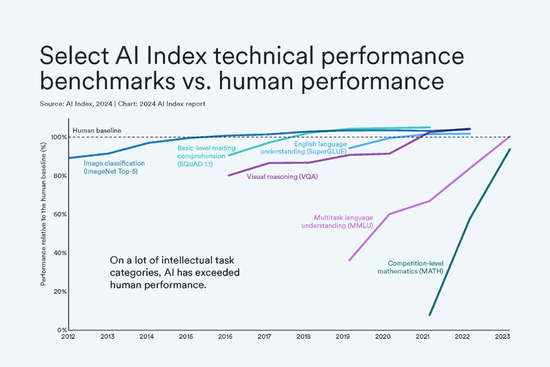
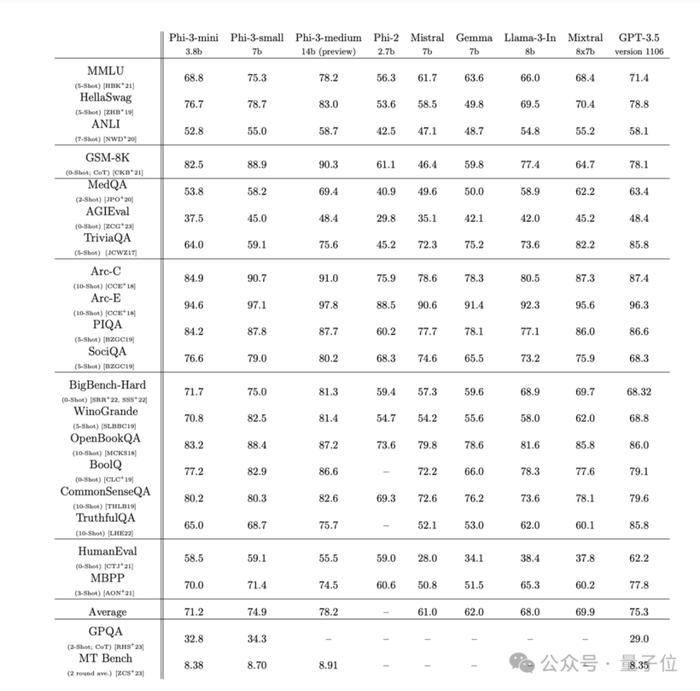
其中仅3.8B参数的Phi-3-mini在多项基准测试中超过了Llama 3 8B。
为了方便开源社区使用,还特意设计成了与Llama系列兼容的结构。
微软这次打出“手机就能直接跑的小模型”的旗号,4bit量化后的phi-3-mini在iphone 14 pro和iPhone 15使用的苹果A16芯片上跑到每秒12 token。

这意味着,现在手机上能本地运行的最佳开源模型,已经做到ChatGPT水平。

在技术报告中还玩了一把花活,让phi-3-mini自己解释为什么构建小到手机能跑的模型很令人惊叹。

除了mini杯之外,小杯中杯也一并发布:
Phi-3-small,7B参数,为支持多语言换用了TikToken分词器,并额外增加10%多语种数据。
Phi-3-medium,14B参数,在更多数据上训练,多数测试中已超越GPT-3.5和Mixtral 8x7b MoE。
作者阵容一看也不简单,一眼扫过去MSRA和MSR雷蒙德团队都投入了不少人。

那么,Phi-3系列到底有什么独特之处呢?
根据技术报告中披露,其核心秘诀就在于数据。
去年团队就发现,单纯堆砌参数量并不是提升模型性能的唯一路径。
反而是精心设计训练数据,尤其是利用大语言模型本身去生成合成数据,配合严格过滤的高质量数据,反而能让中小模型的能力大幅跃升。
也就是训练阶段只接触教科书级别的高质量数据,Textbooks are all you need。

Phi-3也延续了这一思路,这次他们更是下了血本:
投喂了多达3.3万亿token的训练数据(medium中杯是4.8万亿);
大幅强化了数据的“教育水平”过滤;
更多样化的合成数据,涵盖逻辑推理、知识问答等多种技能;
独特的指令微调和RLHF训练,大幅提升对话和安全性。
举个例子,比如某一天足球比赛的结果可能对于大模型是良好的训练数据,但微软团队删除了这些加强知识的数据,留下更多能提高模型推理能力的数据。
这样一来,对比Llama-2系列,就可以用更小的参数获得更高的MMLU测试分数了。

不过小模型毕竟是小模型,也不可避免存在一些弱点。
微软透露,模型本身参数中没能力存储太多事实和知识,这一点也可以从TriviaQA测试分数低看出来。
缓解办法就是联网接入搜索引擎增强。

总之,微软研究院团队是铁了心了要在小模型+数据工程这条路上走下去,未来还打算继续增强小模型的多语言能力、安全性等指标。
对于开源小模型超过ChatGPT这回事,不少网友都认为压力现在给到OpenAI这边,需要赶快推出GPT-3.5的继任者了。

参考链接: [1]https://arxiv.org/abs/2404.14219