你在刷抖音的时候,有没有发现,抖音从来不会给你推送相同内容的视频?你可能会想,这有啥难的,给每个人都存一个记录,以后推送的时候避开就好了呀。nononono!可没有这么简单啊!
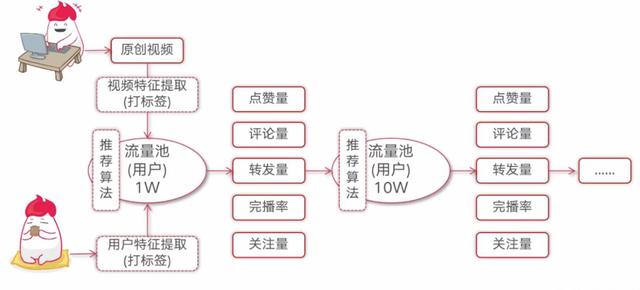
海量用户的重复内容过滤
这是一个非常严肃的问题。在互联网领域,重复推送是一件非常影响用户体验的行为。一旦出现重复内容,会大大增加用户跳出的几率。
搞数据库的同学会说:这还不简单?反正有用户日志,我们给每个人都存一个访问日志表,推送之前exists一下就好了。
怎么说呢,如果用户量只有你们公司几百号人,这个方案是没问题的。但是抖音、快手动辄几亿人,每天都刷,这得存多少份log??每一个用户的log有多大?每一个推送都要从这个大log里exists一下,得耗多少时间?
等你exists一下,用户早就跑了好么?所以在抖音、快手动辄几亿日活,每人每天最少看几百个短视频的情况,如何快速推送不重复的内容是非常困难的事情。
高速过滤的秘密武器
需求:几亿个用户,每个用户有1~几万(甚至更多)个已看记录,快速判断下一个推送给用户的视频是否已经看过。
解决方案1-表级处理:每个用户一张表,存视频id,推荐之后,展示之前,过滤一下。这个表太多,表里的数据也太多,过滤效率太慢了。信息得进一步压缩,速度要再快点才行。
解决方案2-图计算:把每个用户与每个视频发生的关系都存到图数据库。推荐的时候直接通过关系过滤掉。这个虽然不用建N张表,只是存用户和视频的关系就行了。但是用过图数据库的人就知道,节点太多了,计算效果也是非常的慢。不行,信息还得进一步压缩。还能咋压缩啊?
解决方案3-位图:把所有用户当天是否登录的信息映射到一张位图中,这样我们就能迅速通过某个位是0还是1快速判定这个用户当天是否登录过系统。
假如说我们同样使用位图,把每个用户是否看过这个视频映射到位图中,是不是就可以通过某个位是0还是1快速判定这个用户是否看过这个视频呢?哆啦A梦告诉我们:可以!而且有更完善的方法--布隆过滤器!

布隆过滤器:1970年由布隆提出的一种方法,由随机映射函数和二进制向量组成,可以快速检索一个元素是否在一个集合中。

如布隆过滤器的描述,其实就是随机映射函数(hash散列)+二进制向量(位图)组成的。我们把任意需要存储的内容,经过hash散列映射成为一个随机数字,然后存在这张超大的位图中,将对应的位上的值由0改成1就可以了。这样我们就能知道这个这个事情是否发生过。
上图中,用户A看了视频B,hash后的值是5,那么第5位的值就变成1了。如果我们想判断用户A是否看了视频B,只要看看第5位是不是1就可以了。
但是hash有个问题,当数据量超大的时候,就有可能会重复(碰撞)。幸好布隆早就想到了,他是这么解决的:

多hash几次就好了,这样就能就大大降低了重复(碰撞)的问题。总不可能连续好几次hash都是一样的结果吧?
视频推荐过滤器
原理有了,那么就可以开始设计了。
这里我们可以看到,有两个实体:用户和视频。简单组合一下,就有三种方法:
1、给每个用户建一个看过视频的布隆过滤器,推荐系统推送的内容使用布隆过滤器过滤一下,把不在列表里的让客户可见即可;
2、给每个视频建一个观看列表的布隆过滤器,推荐系统给用户推送的时候使用布隆过滤器过滤一下,不在列表里的才能推送即可;
3、建一个大的布隆过滤器,把每个用户的观看记录都放在这个过滤器中,推荐系统给用户推送的时候到大布隆过滤器中过滤一下,不在列表里的才能推送。
以上三种方法都可以,我也不太清楚抖音用的是那种方法,我猜是第一种,因为视频总比用户多,而一个大布隆过滤器的话,又太大了。
布隆过滤器的优化
不过即便是每个用户一个布隆过滤器,数据量还是太大了。任何事情都会引发量变引起质变的问题。所以布隆过滤器误判的问题仍然是存在的。比如:
用户A看视频B,3次hash散列结果是2、5、6;用户A看视频D,3次hash散列结果是5、7、8;用户A看视频F,3次hash散列结果是1、9、3;
这时候,位图中的1、2、3、5、7、8、9都被打上1了。
而我们需要询问布隆过滤器用户A是否看过视频H的时候就出现了:
用户A看视频H,3次hash散列结果是3、8、9,
布隆过滤器里3、8、9的结果内容里已经被打上1了,也就是说布隆过滤器告诉我
们,这个视频已经被看过了(实际上并没有看)。那我们怎么解决这个问题呢?
简单的两招:
1、增加位图的位数(或者减少原始数据量);
2、适当增加hash次数;
布隆大大早就给我们算好了,最佳的原始数据和位图位数比是1:20,经过8次hash,误判率会在千分之一左右。如果把hash次数提高,误判率会更低。

不过,我们的应用是要知道这个用户没看过的,那就不用咋优化了。因为布隆过滤器告诉我们看过,可能是误判,但是如果告诉我们没看过,那就肯定是没看过。