
传统的数据开放共享方式,很多是将原始数据以明文的方式直接输出,这样在数据安全和隐私保护方面存在显著风险,不符合日益完善的法律法规要求,也越来越不能满足当今数据体量、规模日益庞大而复杂的应用需求。另外,也存在加工为标签类的数据再进行输出的方式,但通常存在信息漏损,使用这类数据进行建模,效果大打折扣。

经过实践,TalkingData 借助机器学习技术探索出一套新的方案,通过对原始数据进行分布式的隐含表征提取计算(一种数据变换方式),再将变换后的数据用于开放共享,既可以满足数据输出的安全性要求,又提升了大数据输出的处理速度。该数据输出方式主要基于机器学习的分布式 embedding 算法(嵌入算法)。Embedding 算法是一系列算法的统称,该类算法能够对原始数据进行变换,并挖掘其中的潜在关联。Embedding 算法处理后的数据由于信息漏损较少,相对标签数据有更好的建模效果,被广泛用于推荐系统、自然语言处理等领域。
TalkingData 将该类算法应用到数据安全输出领域,使得原始数据在经过变换后,能够以不具备可识别性的方式输出,而数据获取方无法从中提取到与个人身份相关的敏感信息,也就实现了对隐私数据的匿名化保护。
基于保护用户隐私、保障数据输出安全性以及提升大数据输出处理速度的考量,构建了 TalkingData System 平台(以下简称 TDS)。TDS 平台的底层基于 Spark 和 Hadoop 生态搭载了 embedding 算法,对原始数据进行计算和处理,再将结果通过前端平台页面输出给企业用户,目前已经在金融、零售、互联网、广告等行业中得到应用。
借助 TDS 平台,企业可以将内部来自垂直领域的第一方数据,比如用户群体的活跃、消费、人口属性标签等,与 TalkingData 的第三方数据进行融合,丰富企业的自有模型特征维度。理论上,不需要业务解释或识别的预测模型均可使用本方法输出的数据。
1.1 算法方案详解
本算法具有通用性,可以应用于任何能变换为标准格式的原始数据输出。下面通过一个示例详解说明处理过程:
1.TDS 平台的使用方上传了一批设备 ID(设备标识),通过 ID 匹配,得到对应的 TDID(即 TalkingData 自有的加密标识符)。
2. 使用 TDID 作为索引,提取原始数据。假设有 M 个 TDID,TDID 可以看作每一台智能移动设备的虚拟唯一编号,则提取后的原始数据共有 M 行,每行对应一个设备的属性信息。假设属性个数为 N,每个设备的每个属性值为 1 或 0,代表一个设备具有或不具有某个属性。将该原始数据变换为 M*N 的稀疏矩阵,每行对应一个设备,每列对应一个属性。例如第三行第五列为 0,则表示第三个设备不具有第五列对应的属性。
稀疏矩阵相对普通矩阵来比,能够极大的节省存储空间。构造稀疏矩阵的方法可以理解为以下步骤:
(1)创建一个 M*N 的矩阵,将其中的值全部填充为零。
(2)逐行扫描,如果一个设备具有某个属性,就将该处的值替换为 1,直到扫描完成。
(3)记录哪些行和哪些列的数据为 1,存储这些信息。存储下来的这些信息,实际上就是一个系数矩阵。
3. 通过嵌入模型对标准格式的原始数据进行表征学习。实际上就是对输入的原始矩阵进行分解。嵌入模型可以使用的算法很多,此处以奇异值分解 SVD(Singular Value Decomposition)算法为例进行介绍。
提到 SVD,就不得不提到与其相关的概念——PCA(Principal Components Analysis),即主成分分析,又被称为特征值分解。关于 PCA 方法,大家的普遍联想是降维 。简单来说,PCA 所做的就是在原始空间中顺序地找一组相互正交的坐标轴,第一个轴是使得方差最大的,第二个轴是在与第一个轴正交的平面中使得方差最大的,第三个轴是在与第 1、2 个轴正交的平面中方差最大的。这样,假设在 N 维空间中,我们可以找到 N 个这样的坐标轴,我们取前 r 个去近似这个空间,这样就从一个 N 维的空间压缩到 r 维的空间了,而我们选择的 r 值对空间的压缩要能使数据的损失最小。
PCA 从原始数据中挑选特征明显的、比较重要的信息保留下来,这样一来问题就在于如何用比原来少的维度去尽可能刻画原来的数据。同时,PCA 也有很多的局限,比如说变换的矩阵必须是方阵,而 SVD 算法能够避免这一局限。
SVD 算法,能够将一个矩阵分解为三个子矩阵(三个子矩阵相乘可以还原得到原始矩阵)。我们将这三个矩阵称为 U、Sigma 及 V,其中 Sigma 矩阵为奇异值矩阵,只有对角线处有值,其余均为 0。
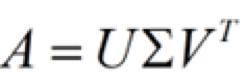
假设原始矩阵是 10,000 行 1,000 列,那么分解后即可得到如下三个子矩阵:
- U 矩阵为 10,000*10,000
- Sigma 矩阵为 10,000*1,000(除了对角线的元素都是 0,对角线上的元素称为奇异值)
- V(^)T 矩阵(V 的转置)为 1,000*1,000
实际应用过程中,我们只保留 U 矩阵的前 512 列,于是三个矩阵的维度就变成了:10,000*512,512*512,512*1,000。为什么是保留 512 列呢?原因是奇异值在矩阵Σ中是从大到小排列,而且奇异值的减小特别快,在很多情况下,前 10% 甚至 1% 的奇异值之和,就占了全部奇异值之和的 99% 以上了。根据我们的多次实验,512 列已经能够很好的保留奇异值的信息。
4. 矩阵分解得到三个子矩阵后,将 U 和 Sigma 相乘,得到输出矩阵。输出矩阵的维度为 10,000*512。可以看到,输出矩阵与输入矩阵有着相同的行数,每一行仍旧代表一个设备。但是输出矩阵的列数变为了 512,与原始矩阵中每一列是一个属性不同,此时的输出矩阵中每一列对应一个特征。该特征不具备可解释性和可识别性,这也就保证了输出数据不会泄露个人隐私。
5. 将输出矩阵直接输出,TDS 平台的使用方可以通过数据接口进行调用。因为平台使用方无法获得 V 矩阵,故而无法还原得到原始矩阵,也就无法还原出任何与个人相关的原始属性信息。
输出时,需要将所有的数据先整理成步骤 2 中的标准输入格式,然后拼接成一个输入矩阵。之后的步骤与上述示例中相同。
1.2 效果
对于 Embedding 算法在数据安全输出的实际表现,TalkingData 做了很多相关实验,也在多个实际项目中进行了验证。以下用两个真实案例进行说明:
案例一:性别标签预测效果提升
性别标签是基于设备信息通过机器学习模型预测打分得出的。在过往的建模过程中,算法人员往往会对原始信息进行一定的处理,比如将非结构性的数据处理为结构性的统计数值,或者将其他标签作为特征输入到模型中。但是,这些特征工程方法都会产生一定的信息漏损或者误差引入。
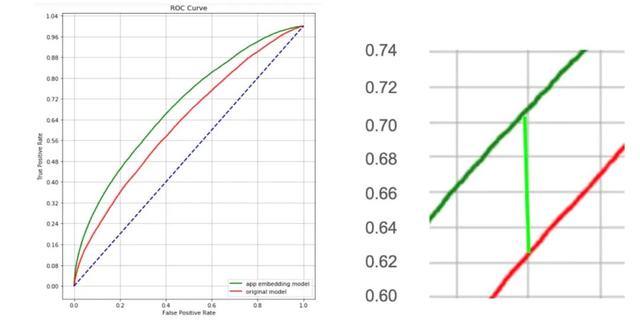
而 Embedding 处理后的数据相比人工的特征筛选,由于信息漏损较少,理论上会取得更好的建模效果。从以下两图可以看出,基于相同原始数据,使用 Embedding 模型的预测效果比原始性别预测模型提升 (0.71 - 0.63)/0.63 = 13.7%。
案例二:某金融企业的风控模型预测效果提升
在与很多企业的合作中,会将 TalkingData 的人口属性标签和应用兴趣标签作为第三方数据引入。在与某金融企业的合作中,TalkingData 将数据通过 TDS 输出给该企业并应用在风控模型中。
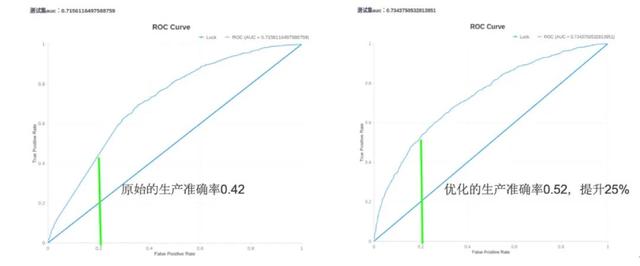
在相同的假阳率(False Positive Rate)下,企业原有算法的生产准确率为 0.42,而加入 Embedding 算法输出的数据后,经过优化的生产准确率达到 0.52,提升 25%。在风控领域中,25% 的提升能够帮助企业避免很大的经济损失。
1.3 关于其他 Embedding 方法的思考
Embedding 方法被广泛应用于自然语言处理领域,也就是使用数学语言表示一篇文本。虽然上文提到的 SVD 算法的有效性在实际模型计算中被验证了,但是在文本特征表示方面仍有缺陷。
首先,它是一个词袋模型(BOW,bag of words),不考虑词与词之间的顺序,而在实际文本中,词语的顺序也非常重要,而且每个词在句子中的重要性各不相同;其次,它假设词与词之间相互独立,但在大多数情况下词与词是相互影响的,这也是为什么我们在做“阅读理解”的时候经常要联系上下文的原因。
如今 Embedding 领域早已向深度学习的方向衍化,大致可以分为以下四种常见应用:
- 不依赖文本语法和语序的词袋模型:one-hot、tf-idf、textrank 等;
- 主题模型:LSA、pLSA、LDA;
- 基于词向量的固定表征:word2vec、fastText、glove
- 基于词向量的动态表征:elmo、GPT、bert
其中,Word2vec 是获得工业界广泛应用的算法之一。提到 Word2vec 就不得不引入“词向量”的概念。NLP 领域中,最细粒度的是词语,词语构成句子,句子再组成段落、篇章、文档。如何用数学语言表示每一个词语,成为研究词与词之间关系的关键。Word2vec 正是来源于这个思想,可以把它看作是简单化的神经网络模型,但是它的最终目的,不仅仅是用数值表示文本符号,还有模型训练完后的副产物——模型参数(这里特指神经网络的权重)。该模型参数将作为输入词语的某种向量化的表示,这个向量便称为——词向量。
举例子说明如何通过 Word2vec 寻找相近词:
结合 TalkingData 应用 Embedding 的实际场景,与词向量的最大区别就是被表示的特征之间没有上下文的联系。TalkingData 以分析移动设备行为数据为主,对大多数设备属性来说,打乱排列的顺序对于实际意义来说没有任何影响,但是一个句子里面的词语是不能被打乱顺序排列的,句式结构对于词向量表示来说是非常重要的。基于实际业务场景的考量,我们没有选择用 Word2vec 或更复杂的 Embedding 算法来转换原始数据。
虽然,我们保证了原始数据输出的安全性,但是伴随而来的是数据可解释性较弱的问题。由于 Embedding 算法将原始数据转化为了另一个空间的数值向量,因此无法人为理解或者赋予输出矩阵的每一列的实际含义。
假设建模人员构建一个“工资预测回归模型”,采集到的样本特征包括“性别、年龄、学历、工作城市、工作年限…”,分别对应数据集中的每一列,那么他们可以容易的计算得到每个特征的权重,并且能够比较哪个特征的权重较高,即特征重要性的排序,得到诸如“工作年限对工资高低的影响比性别更重要”这样的结论。
但是在使用 TDS 平台输出的数据构建模型的时候,我们没办法向上述模型一样分析比较每一列特征对模型的影响,只能得出增加 Embedding 特征对于模型效果是否有提升这样粒度较粗的结论。显然,如果建模人员对于模型的解释性有特别严苛的需求的话,TDS 平台暂时没有办法提供解决方案。
作者简介:
周婷,TalkingData 数据科学家,专注移动大数据的深度挖掘和基于 Spark 的机器学习平台开发,为 TalkingData 智能营销云和数据智能市场提供算法支持,主要负责精准营销预测、企业级用户画像等产品的算法研发,长期关注互联网广告、金融营销、反欺诈检测等领域。




















