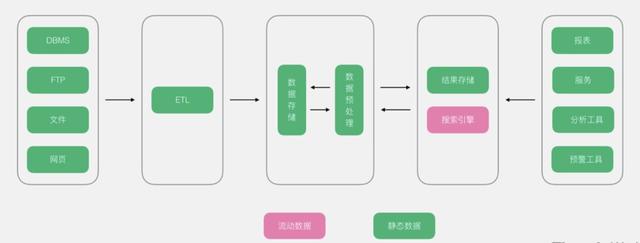
本文总结了几种常用的数据加载方法,基于R语言工具实现数据加载模块,让用户对数据挖掘工具设计有更直观的了解。在分析和设置过程中,主要实现了聚类分析、相关分析、决策树和随机森林算法。在评价模块中,用户可以对所建立的模型进行评价,希望对读者有所帮助。

1. 基于R语言的数据挖掘研究背景
目前,R语言已成为数据的通用语言。用于数据整理、统计、分析、预测和可视化,并提供了多种数据的统计分析和绘制方法。它不仅满足了人们对数据的各种需求,而且为人们参与统计分析搭建了一座桥梁。用户可以设计程序或下载和加载软件包来满足他们的需要,或者他们可以使用R语言的许多更复杂的数据挖掘扩展。
2. 使用R语言总结数据
在电子商务网站中,用户在加载数据后,如果对当前数据没有具体的了解,就无法进行数据挖掘。R语言可以为用户提供相关的统计方法,通过直观的图表来反映数据信息,帮助用户直观的了解自己的数据,为下一步的数据挖掘提供基础。
3.使用语言组织数据
在数据挖掘工具设计中,用户花在数据整理上的时间比花在建模上的时间要多。为了提高其性能,用户需要通过改进数据来实现这一目标。例如,您需要添加一些额外的数据、清理数据和处理丢失的数据。数据整理部分提供了帮助用户使用相关数据的方法。
用户加载的数据可能存在很多问题,如数据错误、部分数据丢失、离群数据值等。数据整理接口主要提供数据缩放、数据插值、数据转换和数据清理,以满足不同建模需求。
4. 建模
在建模过程中,为用户提供随机森林的聚类分类、关联分析、决策树和建模创建,以及一些默认参数,从而优化部分建模过程,帮助用户快速找到合适的模型。同时,用户可以根据自己的需要修改参数。
5. 建模评估
在不同的模型中选择最合适的模型时,需要对所建立的模型进行评价,这有助于更好地理解模型。模型的评估还可以确定在创建模型时数据中是否存在标量错误。
6.设计
为了在数据挖掘工具设计过程中实现对数据的理解,用户通常会在建模过程中进行聚类和关联分析,这些聚类和关联分析将从建模中分离出来,作为独立的标签存在。数据挖掘可以根据标签的顺序进行,也可以根据自己的需要进行。
以上是基于R语言工具实现数据加载模块的几种常用数据加载方法的总结,让用户对数据挖掘工具设计有更直观的了解。在分析和设置过程中,主要实现了聚类分析、相关分析、决策树和随机森林算法。在评价模块中,用户可以对所建立的模型进行评价。希望对读者有所帮助。
Smartbi Mining是一个专业的数据挖掘平台,通过深度数据建模,为企业提供预测能力。算法丰富,支持多种高效实用的机器学习算法,包含了分类、回归、聚类、预测、关联,5大类机器学习的成熟算法;功能完备,除提供主要算法和可视化建模功能外,Smartbi Mining还提供了必不可少的数据预处理功能;易学易用,一站式完成数据处理和建模。