您是否曾经不得不加载一个非常消耗内存的数据集,以至于您希望有一个方法处理它呢?随着我们能够利用越来越多的数据,大型数据集正日益成为我们生活的一部分。
我们必须记住,在某些情况下,即使是最先进的配置也没有足够的内存空间来处理数据。这就是为什么我们需要找到其他方法来有效地完成这项任务的原因。在这篇文章中,我们将向您展示如何在多个核心上实时生成数据集,并立即将其提供给您的深度学习模型。
本教程中使用的框架是Python的高级包Keras提供的框架,它可以在TensorFlow或Theano的GPU安装上使用。

以前的情况
在阅读本文之前,您的Keras脚本可能如下所示:
import numpy as np
from keras.models import Sequential# Load entire datasetX, y = np.load('some_training_set_with_labels.npy')# Design modelmodel = Sequential()[...] # Your architecturemodel.compile()# Train model on your datasetmodel.fit(x=X, y=y)
本文主要介绍如何更改一次加载整个数据集的行。事实上,这个任务可能会导致问题,因为所有的训练样本可能无法同时装入内存。
为了做到这一点,让我们一步一步地研究如何构建适合这种情况的数据生成器。顺便说一下,下面的代码是一个很好的框架,可以用于您自己的项目。
Notations
在开始之前,让我们先了解一些在处理大型机器学习数据集时特别有用的组织技巧。
让ID作为一个Python字符串来识别给定的数据集的样本。跟踪样品及其标签的一个好方法是采用以下框架:
- 创建一个名为partition的字典,在其中收集:
- 在partition['train']中,训练id列表
- 在partition['validation']中,验证id的列表
- 创建一个名为labels的字典,其中对于数据集的每个ID,关联的标签由labels[ID]给出
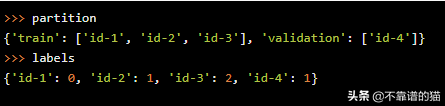
例如,假设我们的训练集包含id-1、id-2和id-3,它们的标签分别为0、1和2,验证集包含id-4和标签1。在这种情况下,Python变量partition和labels看起来像这样
此外,为了模块化,我们将在单独的文件中编写Keras代码和自定义类,您的文件夹看起来像这样

其中data/被假定为包含机器学习数据集的文件夹。
最后,值得注意的是,本教程中的Python代码旨在实现通用和最小化,以便您可以轻松地将其用于您自己的机器学习数据集。
数据生成器
现在,让我们详细了解如何设置Python类DataGenerator,它将用于为您的Keras模型提供实时数据。
首先,让我们编写类的初始化函数。我们让后者继承keras.utils.Sequence的属性,这样我们就可以利用诸如多处理器之类的良好功能。
def __init__(self, list_IDs, labels, batch_size=32, dim=(32,32,32), n_channels=1, n_classes=10, shuffle=True): 'Initialization' self.dim = dim self.batch_size = batch_size self.labels = labels self.list_IDs = list_IDs self.n_channels = n_channels self.n_classes = n_classes self.shuffle = shuffle self.on_epoch_end()
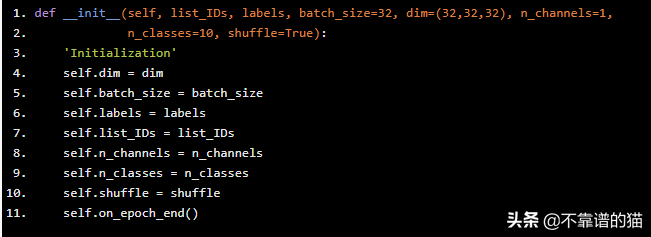
我们将关于数据的相关信息作为参数,例如维度大小(例如,长度为32的volume dim=(32,32,32)),通道数,类数,批大小,或决定我们是否要在生成时shuffle 我们的数据。我们还存储重要信息,例如标签和我们希望在每次传递时生成的ID列表。
在这里,on_epoch_end方法在开始时触发一次,在每个epoch结束时也触发一次。如果shuffle参数设置为True,我们将在每次传递时获得一个新的探测顺序(否则只保留一个线性探测方案)。
def on_epoch_end(self): 'Updates indexes after each epoch' self.indexes = np.arange(len(self.list_IDs)) if self.shuffle == True: np.random.shuffle(self.indexes)
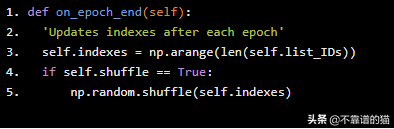
对提供给分类器的示例的顺序进行Shuffling是很有帮助的,这样在不同epochs之间的批处理看起来就不一样了。这样做最终将使我们的模型更加健壮。
生成过程的另一个核心方法是完成最关键工作的方法:生成批量数据。负责此任务的私有方法称为__data_generation,并将目标batch的id列表作为参数。
def __data_generation(self, list_IDs_temp):
'Generates data containing batch_size samples' # X : (n_samples, *dim, n_channels) # Initialization X = np.empty((self.batch_size, *self.dim, self.n_channels)) y = np.empty((self.batch_size), dtype=int) # Generate data for i, ID in enumerate(list_IDs_temp): # Store sample X[i,] = np.load('data/' + ID + '.npy') # Store class y[i] = self.labels[ID] return X, keras.utils.to_categorical(y, num_classes=self.n_classes)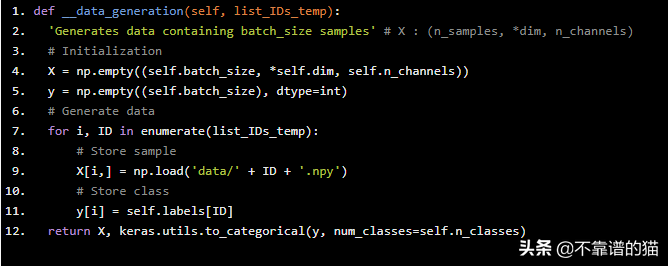
在数据生成期间,此代码从每个示例的对应文件ID.npy中读取该示例的NumPy数组。由于我们的Python代码是多核友好的,请注意,您可以执行更复杂的操作(例如从源文件计算),而不必担心数据生成会成为训练过程中的瓶颈。
另外,请注意我们使用了Keras的keras.utils.to_categorica函数,用于将存储在y中的数字标签转换为二进制形式(例如,在6个类问题中,第三个标签对应于[0,0,1 0,0 0]),适用于分类。
现在是我们一起构建所有这些组件的部分。每个调用都请求一个批处理索引在0到批次总数之间,其中后者在__len__方法中指定。
def __len__(self): 'Denotes the number of batches per epoch' return int(np.floor(len(self.list_IDs) / self.batch_size))

一个常见的做法是将这个值设置为⌊# samplesbatch size⌋
这样模型每个epoch最多只能看到一次训练样本。
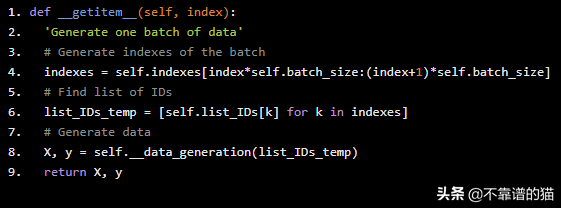
现在,当调用与给定索引对应的batch时,生成器执行__getitem__方法来生成它。
def __getitem__(self, index): 'Generate one batch of data' # Generate indexes of the batch indexes = self.indexes[index*self.batch_size:(index+1)*self.batch_size] # Find list of IDs list_IDs_temp = [self.list_IDs[k] for k in indexes] # Generate data X, y = self.__data_generation(list_IDs_temp) return X, y
与我们在本节中描述的步骤相对应的完整Python代码如下所示。
import numpy as np
import kerasclass DataGenerator(keras.utils.Sequence): 'Generates data for Keras' def __init__(self, list_IDs, labels, batch_size=32, dim=(32,32,32), n_channels=1, n_classes=10, shuffle=True): 'Initialization' self.dim = dim self.batch_size = batch_size self.labels = labels self.list_IDs = list_IDs self.n_channels = n_channels self.n_classes = n_classes self.shuffle = shuffle self.on_epoch_end() def __len__(self): 'Denotes the number of batches per epoch' return int(np.floor(len(self.list_IDs) / self.batch_size)) def __getitem__(self, index): 'Generate one batch of data' # Generate indexes of the batch indexes = self.indexes[index*self.batch_size:(index+1)*self.batch_size] # Find list of IDs list_IDs_temp = [self.list_IDs[k] for k in indexes] # Generate data X, y = self.__data_generation(list_IDs_temp) return X, y def on_epoch_end(self): 'Updates indexes after each epoch' self.indexes = np.arange(len(self.list_IDs)) if self.shuffle == True: np.random.shuffle(self.indexes) def __data_generation(self, list_IDs_temp): 'Generates data containing batch_size samples' # X : (n_samples, *dim, n_channels) # Initialization X = np.empty((self.batch_size, *self.dim, self.n_channels)) y = np.empty((self.batch_size), dtype=int) # Generate data for i, ID in enumerate(list_IDs_temp): # Store sample X[i,] = np.load('data/' + ID + '.npy') # Store class y[i] = self.labels[ID] return X, keras.utils.to_categorical(y, num_classes=self.n_classes)
Keras脚本
现在,我们必须相应地修改我们的Keras脚本,以便它接受我们刚刚创建的生成器。
import numpy as np
from keras.models import Sequentialfrom my_classes import DataGenerator# Parametersparams = {'dim': (32,32,32), 'batch_size': 64, 'n_classes': 6, 'n_channels': 1, 'shuffle': True}# Datasetspartition = # IDslabels = # Labels# Generatorstraining_generator = DataGenerator(partition['train'], labels, **params)validation_generator = DataGenerator(partition['validation'], labels, **params)# Design modelmodel = Sequential()[...] # Architecturemodel.compile()# Train model on datasetmodel.fit_generator(generator=training_generator, validation_data=validation_generator, use_multiprocessing=True, workers=6)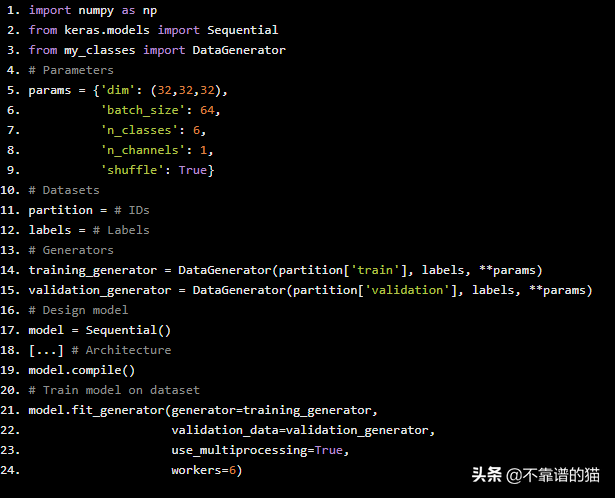
正如您所看到的,我们从模型中调用了fit_generator方法,而不是fit,我们只需要将训练生成器作为参数之一。其余的由Keras负责!
注意,我们的实现支持使用fit_generator的多处理器参数,其中在n_workers中指定的线程数是并行生成批的线程数。足够多的worker确保CPU计算得到有效管理,即瓶颈实际上是神经网络对GPU的正向和反向操作(而不是数据生成)。