明确目的
带着问题出发,明确我们的目的是探索不同岗位、城市、公司数据人薪资是怎样的,所以是一个探索性分析。
数据处理
1、查看并理解字段
拿到数据,大概看一下,总共有184条记录,量不大,那我们就直接用Excel来处理即可。样本量虽然有点少,但贵在真实、有效。
有8个字段:
- 序号:对一条记录的唯一编号
- 提交时间:用户提交问卷的时间,没有特别的含义
- 大佬是什么岗:岗位名称,如数据仓库、大数据开发等7个类别
- 大佬在什么厂:公司类型,如一线巨厂、三线小厂等4个类别
- 大佬的月薪多少:月薪,有1w以下,1~2w等6个区间可选
- 你还有啥想问、想说的:留言
- 递交地点:城市,可以理解为工作所在城市
2、缺失值处理
缺失值只在留言一列中存在,但这是正常现象,没必要做任何操作
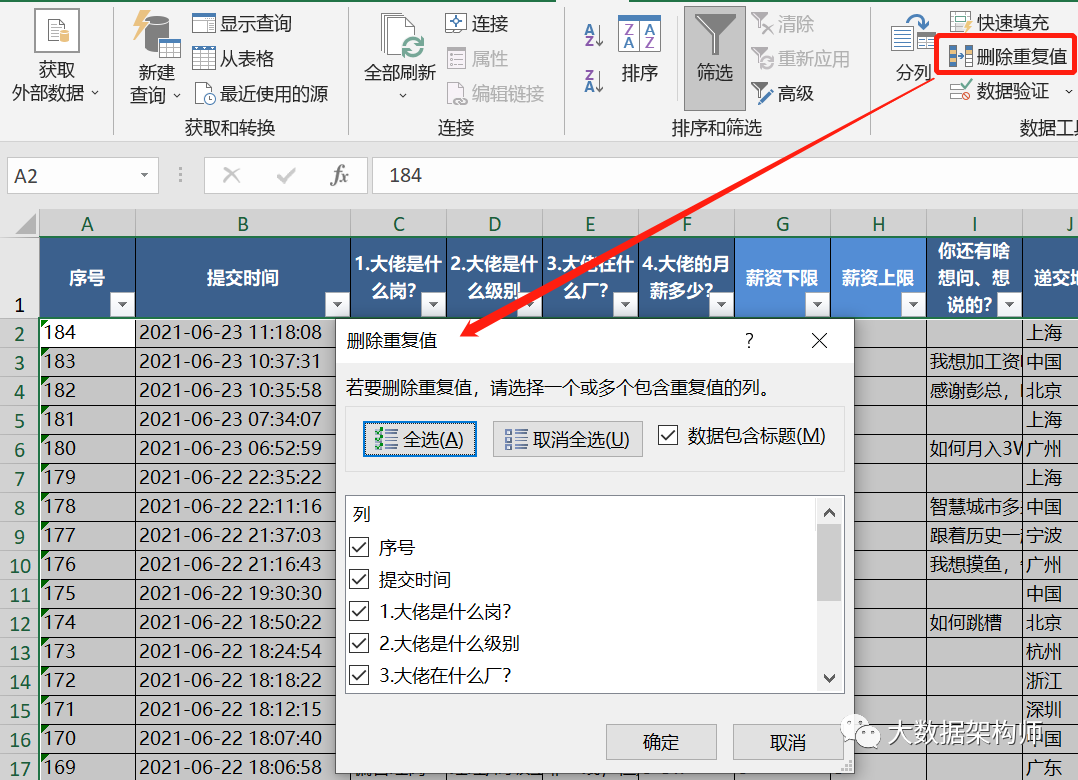
3、重复值处理
对于重复值,这里我们认为所有字段都重复的才为重复值,即可删除。通过【删除重复值】的功能来实现,这份数据里没有重复值。
4、异常值处理
关于异常值的处理,一个是对数值型数据的统计学意义上的异常来看,常用的方法是直接画出箱型图来观察。
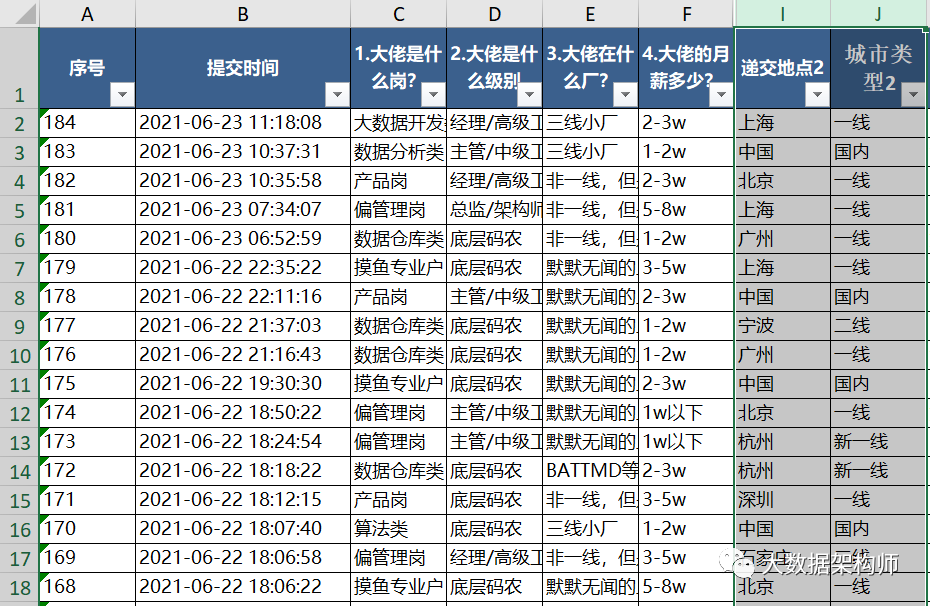
另一个则是根据业务经验来判断,这里我们可以对城市字段进行分组,方便后续的分析,同时在分组过程中,也发现了一些异常值,这是基于常识经验。
把城市分为一线、新一线、二线、三线、四线、五线,有50个值是没有归属的,情况也不一样。
有的是地点直接显示为国别,如中国、美国,有的是地点显示为省份,如广东、浙江。把省份用其省会城市代替,做一些处理。

最后得到规整的城市对应分组城市类型的数据。
由于数据源是从调查软件中导出,所以整个数据比较规范,在缺失值、重复值、异常值的处理上都比较方便,基本无需做多余的操作,直接拿来用都可以。
数据分析
初级段位:数据罗列
1、单一特征分布
查看这份调查问卷每个字段的情况

根据对单一特征的分析可以知道:
- 在这份样本中,有7个类别的岗位,其中数据仓库岗位的用户最多,占比24.46%,算法类岗位填写问卷的最少,只有3个,其余的如大数据开发、数据分析、产品类等岗位分布大致相同。
- 有近一半的人(42.93%)是在默默无闻的血汗工厂工作。
- 本次调查的人中有约95%的人月入过万,有超过2/3的人是月收入在1~2、2~3W的区间内。
- 在北上广深等一线城市工作的人超过一半(51.63%),其次是新一线城市。
- 底层码农占比44.57%
2、离散型数据分布
查看了单个字段的大致分布后,别忘了我们的目的:薪资!所以要看每个字段和薪资的情况

可以看出:
- 从岗位&薪资上来看,数据分析类岗位1~2w的薪资占比达到了70%,大数据开发岗位2~3w薪资占比60%,其余数据仓库、产品岗等2~3w较多。所以,想要工资高,选择赛道很重要!
- 从级别&薪资上来看,底层码农1~2w薪资水平占比较多(49%),主管/中级工程师同样也是1~2w占比较多,54%的人到了经理/高级工程师的级别后其薪资水平可达到2~3w,总监/架构师及以上的薪资在5~8w和8w以上的人数占比达到了61.5。所以,要想多加薪,升职要上心。
- 从公司性质&薪资上看,一线巨厂和非一线但是听过名字的大厂薪资2~3w的人较多,默默无闻的血汗工厂和三线小厂的薪资在1~2w的人较多。
- 从城市&薪资上看,可以看到,一线和新一线城市的薪资结构差不多,1~2、2~3w占据了大多数,2345线城市2~3w薪资的就不多了。所以,哪儿的工资多?大城市里找工作。
中级段位:多特征联合
4、交叉分析
薪资不单单和某一因素有关,不同的城市、岗位、级别,薪资水平肯定会不一样,因此要进行多个维度的交叉分析。

- 大厂里岗位分布比较均匀,三线小厂和默默无闻的血汗工厂数据仓库岗位尤其多,数据分析类岗位在各个厂都是1~2w人数居多,数据仓库岗在默默无闻的血汗工厂、三线小厂里主要是1~2w、2~3w居多,大胆猜测为彭老师人脉受众主要是做数据仓库的,比较成熟了,所以样本多薪资高。
- 不同城市里岗位的分布,一线城市大数据开发类、数据仓库岗位较多且薪资在1~2,2~3w,其他城市岗位分布比较散,当然也可能和样本有偏有关。
查看各岗位的城市分布及薪资情况

- 大数据开发岗在北京、深圳的薪资较高(5~8w及以上)
- 相比其他数据类岗位,偏管理岗在其他城市也有了分布,整体薪资较高,在一线城市反而也有1w左右的,猜测1线城市用工不愁?
- 数据仓库岗样本量多,分布也较广,在各个城市基本都是1~2w,2~3w较多
- 数据分析岗没有5w及以上的,主要是因为样本中没有级别总监及以上的,所以拉低了数据分析岗位的平均薪资
- 算法岗由于样本量太少(3个),城市薪资差异也较大
查看级别的城市分布同薪资情况

- 底层码农在深圳1~2w的居多,上海北京1~2w和2~3w的分庭抗礼
- 主管/中级工程师在一线城市2~3w的会多一些,其他二线城市主要是1~2w
- 经理/高级工程师在各个城市基本上都是2~3的居多
- 总监/架构师及以上基本在3~5w及以上,青岛、广州、上海有1~2w的
总结一下:
- 4个最多:数据仓库岗位人群最多,一线城市工作的人最多,默默无闻的血汗工厂工作的人最多,月入2~3w的人最多(与样本群体相关)。
- 薪资水平:以这份调查样本来说,数据人平均薪资在2.5w左右。
- 岗位选择:一线城市较其他城市提供的岗位有更多的选择性,除了数据分析岗薪资是1~2w,其他数据岗位薪资均在2~3w较多。
- 职业发展:在职业阶段初期,底层码农和主管/中工薪资结构差不多,再往上薪资水平就可提升一大截。
- 城市选择:大厂主要集中在一线城市,各个岗位分布较为平均且整体薪资较高。
高级段位:一些思考
让我们抛开这份样本来思考,从整个行业来看,数据人的薪资、岗位、职业、城市又有着怎样的趋势?可以带着3个问题来思考。
Q1:数据类岗位薪资最高的是?
数据类岗位应属于信息传输、软件和信息技术服务这类职业中,可以看到,除了管理层和金融服务外,它的工资排名第三,有90%的人能拿到17.28w的年薪,整个行业向好。

细分到数据类岗位,可以参考的是,数据分析岗年中位数薪资为14.6w,数据仓库18.1w,大数据开发21.4w,产品经理19.3w,算法工程师23.8w,要努力精进自己的技术。

Q2:是否职位越高,薪资越高?
从人社局公布的分岗位等级从业人员薪资分位值上可以看出,不管是技术类还是管理类,职位越高,薪资也会随着增长,但我们也发现,就算是高层管理岗有10%的人拿着5w年限左右的薪资,也有38万年薪就超过了90%的人,所以打铁还需自身硬,数据人,加油!

Q3:哪些城市的薪资最高?
通过统计各大城市的平均薪资和薪资中位数可以看到,北京、上海、南京、深圳、广州、杭州等一线、新一线城市平均薪资过万,当然平均值过于被极值影响了,从薪资中位数上看,只有北京、上海薪资中位数超过了6000,要高薪,还是要到大城市去。

数据展示
简单地用Excel做了一个可视化大屏,做了2个动态交互效果,一个是通过列表框控件的选择显示的圆环图,可以看到其分布占比。

另一个交互效果是数据透视表里切片器,通过将数据透视表联动,选择不同的岗位,可得到相应的图形。