

> Photo by Jaime Spaniol on Unsplash
CNN,Mobile-Net,KNN,Random Forest和MLP。 哪种算法最好?
一切始于我年轻的表弟,他在自己的世界里迷路,在绘画本上涂鸦。 我问他在做什么。 他回答说他正在养猫。 看起来根本不像猫。 他要求我和他一起玩游戏,我会认出他在画什么。 一段时间以来,这很有趣,但是很快,我就感到无聊。 我不想不和他玩耍来伤害他的感情,所以我用自己的计算机视觉和Python技巧来制作一个Doodle分类器。 现在的问题是,我将如何实施它? 有数百种方法可以对Doodle进行分类,而我必须选择一种最准确的涂鸦,即花费最少的时间进行训练,占用更少的内存,需要更少的处理能力并且不需要TB的数据即可提供有意义的信息 结果。
上网浏览后,我发现了可以以最佳方式完成此任务的前5种算法,但是我访问的每个网站都讲述了一个不同的故事。 有些人说CNN是最好的,而另一些人说移动网络是最好的。 我想-好吧,让我们测试一下所有这些。 我在Kaggle竞赛中找到了一个包含大量带有标签的涂鸦的出色数据集,可以免费下载。
图像分类是一个巨大的话题,因为有很多算法可用于各种应用。 图像分类是如此之大和千变万化,以至于每天都在创建新的算法,并且它的新应用也在不断涌现。 因此,即使它们有数百种变体,我也很难手动选择一些算法。 因此,本文将研究哪种算法最适合涂鸦分类。
我还将测试这些算法在其他情况下(例如手写字符分类,车牌识别等)的可靠性。
· 研究中使用的机器学习技术简介
· 评估指标
· 选择用于研究的参数的详细信息
· 结果
· 局限性和结论
涂鸦分类的算法有数千种,在这里我列出了一些我将探索的著名算法-
我们可以将随机森林算法用于分类和回归。 就像决策树一样,只是它使用数百个决策树得出结论。 决策树根据相似的特征将数据分为各种类别。 对于每个数据点,它检查是否具有特定功能,大多数常见数据属于同一类。 在随机森林算法中,我们采用许多决策树,并随机给它们提供较少的特征以供检查,例如,如果我们有100个特征,则可能给每棵树10个随机特征。 一些树将分配不正确的类,但是许多树将是正确的! 我们以多数为准,并创建我们的分类模型。
K最近邻(KNN)既可以用作分类算法,也可以用作回归算法。 在KNN中,数据点分为几类,以预测新样本点的分类。 为了实现此任务,它使用距离公式来计算各个数据点之间的距离,然后基于该距离,然后为每个类别定义区域边界。 任何新的数据点都将属于这些区域之一,并将被分配给该类。
多层感知(MLP)是前馈人工神经网络的一种形式。 MLP有许多层,但在其隐藏层中只有一个逻辑函数,而在输出层中只有一个softmax函数。 该算法以单个大向量作为输入,并对输入层和隐藏层执行矩阵运算,然后结果通过逻辑函数,其输出通过另一个隐层。 重复此过程,直到网络到达输出层为止,在此使用softmax函数生成单个输出。
卷积神经网络(CNN)是最容易实现的深度学习计算机视觉算法之一。首先,它获取给定尺寸的输入图像,并为其创建多个滤镜/特征检测器(最初是给定尺寸的随机生成的矩阵),滤镜的目的是识别图像中的某些图案,然后在滤镜上移动在矩阵和图像之间进行图像和矩阵相乘。该滤镜在整个图像中滑动以收集更多特征,然后我们使用激活函数(主要是整流的线性单位函数)来增加非线性或仅保留重要特征,然后使用max-pooling函数将给定值中的所有值相加矩阵大小(例如,如果我们选择4的矩阵,则它将所有4个值相加以创建1个值),从而减小输出的大小以使其更快。最后一步是展平最终矩阵,该矩阵作为输入传递到基本ANN(人工神经网络)并获得类预测。
Mobile-Net体系结构使用深度方向可分离卷积,其中包括深度方向卷积和点方向卷积。 深度方向卷积是通道方向Dk * Dk空间卷积,假设我们在图像中有3个通道(R,G,B),那么我们将具有3 * Dk * Dk空间卷积。 在逐点卷积中,我们的内核大小为1 * 1 * M,其中M是在深度卷积中的通道数,在这种情况下为3。因此,我们有一个大小为1 * 1 * 3的内核。 我们通过3 * Dk * Dk输出迭代这个内核以获得Dk * Dk * 1输出。 我们可以创建N 1 * 1 * 3个内核,每个内核输出一个Dk * Dk * 1图像,以获得形状为Dk * Dk * N的最终图像。 最后一步是将深度方向卷积添加到点方向卷积。 这种类型的体系结构减少了训练时间,因为我们需要调整的参数较少,而对精度的影响较小。

> Sample of doodles used for research
以上是用于本研究的Doodle样本。
我在Kaggle quickdraw数据集上训练了机器学习模型,该数据集包含5000万张不同类型的Doodle图像。 我将庞大的数据集分为两部分:用于训练的35000张图像和用于测试的15000张图像。 然后,我针对随机选择的5种不同类型的Doodle计算每种算法的训练时间。 在测试集上,我计算了每种算法的平均平均精度,准确性和召回率。
评估指标
训练时间
平均平均精度
准确性
召回
Shashwat Tiwari 16MCA0068的更多有关评估指标的信息
n_estimators —森林中决策树的数量。 [10,50,100]
max_features-拆分['auto','sqrt']时要考虑的功能
max_depth —树中的最大级别数[2,4,6,8,10]
n_jobs-并行运行的进程数,通常设置为-1以一次执行最大进程。
准则—这是一种计算损失并因此更新模型以使损失越来越小的方法。 ['熵','cross_validation']
我使用"自动"作为max_feature; 8作为max_depth; -1作为n_jobs,"熵"作为我的标准,因为它们通常会产生最佳效果。
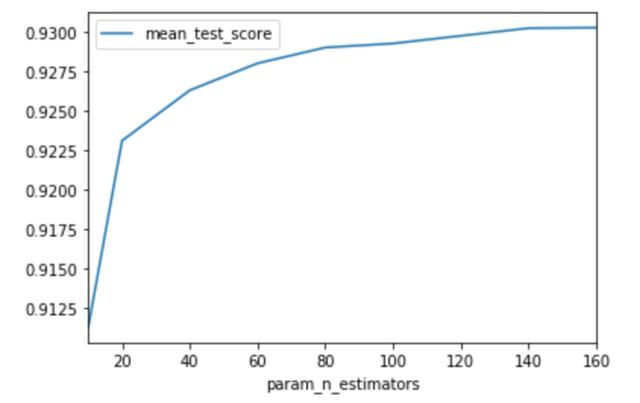
> the Graph to find an optimum number of trees
但是,为了找出最佳的树数,我使用了GridSearchCV。 它尝试所有给定的参数组合并创建一个表以显示结果。 从图中可以看出,在80棵树之后测试分数没有显着增加。 因此,我决定在80棵树上训练我的分类器。
n_neighbors —要比较的最近数据点数[2,5,8]
n_jobs-并行运行的进程数,通常设置为-1以一次执行最大进程
我没有更改此模型的任何默认参数,因为它们会提供最佳结果。
但是,为了找到n_neighbors的最佳数量,我使用了GridSearchCV,这是我得到的图形:

> The graph to find an optimum number of N-neighbors
根据该图,测试分数在5 n_neighbors之后下降,这意味着5是最佳邻居数。
alpha-最常用的学习速率,它告诉网络调整梯度的速度。 [0.01,0.0001,0.00001]
hidden_layer_sizes —它是一个值的元组,由每层的隐藏节点数组成。 [(50,50),(100,100,100),(750,750)]
激活—一种功能,可以为图像中的重要特征提供价值,并删除不相关的信息。 ['relu','tanh','logistic']。
求解器(也称为优化器),该参数告诉网络使用哪种技术来训练网络中的权重。 ['sgd','adam']。
batch_size —这是一次要处理的图像数。 [200,100,200]。
我将激活选择为" relu",将求解器选择为" adam",因为这些参数可提供最佳结果。
但是,为了选择隐藏层和alpha的数量,我使用了GridSearchCV。

> Table to find an optimum number of N-neighbors
从表中可以看出,当alpha为0.001,hidden_layer_sizes为(784,784)时,可获得最佳结果。 因此,我决定使用那些参数。
learning_rate-告诉网络调整梯度的速度。 [0.01,0.0001,0.00001]
hidden_layer_sizes —它是一个值的元组,由每层的隐藏节点数组成。 [(50,50),(100,100,100),(750,750)]
激活—一种功能,可以为图像中的重要特征提供价值,并删除不相关的信息。 ['relu','tanh','logistic']。
求解器(也称为优化器),该参数告诉网络使用哪种技术来训练网络中的权重。 ['sgd','adam']。
batch_size —这是一次要处理的图像数。 [200,100,200]
时期-程序应运行的次数或应训练模型的次数。 [10,20,200]
我将激活函数选择为" relu",将求解器选择为" adam",因为这些参数通常会产生最佳效果。 在网络中,我添加了3个卷积层,2个maxpool层,3个辍学层,最后添加了一个softmax激活函数。 我在这里没有使用GridSearchCV,因为可以尝试很多可能的组合,但是结果不会有太大差异。
Input_shape-是由图像尺寸组成的元组。 [(32,32,1),(128,128,3)]。
Alpha-网络的宽度。 [<1,> 1,1]
激活—一种功能,可以为图像中的重要特征提供价值,并删除不相关的信息。 ['relu','tanh','logistic']。
优化器—也称为求解器,此参数告诉网络使用哪种技术来训练网络中的权重。 ['sgd','adam']。
batch_size —这是一次要处理的图像数。 [200,100,200]。 时期-程序应运行的次数或应训练模型的次数。 [10,20,200]
classes-要分类的类数。 [2,4,10]
损失-告诉网络使用哪种方法来计算损失,即预测值与实际值之差。 ['categorical_crossentropy','RMSE']
首先,我将28 * 28图像的大小调整为140 * 140图像,因为移动网络最少需要32 * 32图像,所以我使用的最终input_shape值为(140,140,1),其中1是图像通道(在 这种情况下,黑色和白色)。 我将alpha设置为1,因为它通常会产生最佳效果。 激活功能被设置为默认值,即" relu"。 我使用了" Adadelta"优化器,因为它可以提供最佳效果。 batch_size设置为128以更快地训练模型。 我已经使用20个纪元来提高准确性。 由于我们有5个类别可以分类,因此将类别设置为5。

> Final Results (Fingers crossed)
以上是所使用的所有机器学习技术的性能。 指标包括准确性,召回率,准确性和培训时间。 令我震惊的是,Mobile Net的训练时间为46分钟,因为它被认为是轻巧的模型。 我不确定为什么会这样,如果您知道为什么,请告诉我。
· 在这项研究中,只使用了28 * 28大小的黑白涂鸦,而在现实世界中,不同的颜色可能会表现出不同的意思或表示不同的事物,并且图像大小可能会有所不同。 因此,在这些情况下,算法的行为可能会有所不同。
· 在所有讨论的算法中,都有许多可以更改和使用的超参数,它们可能会给出不同的结果。
· 训练这些算法的训练集仅限于35000张图像,添加更多图像可以提高这些算法的性能。
结果表明,移动网络实现了最高的准确性,准确性和查全率,因此就这三个参数而言,它是最佳算法。 但是,移动网络的培训时间也是最高的。 如果将其与CNN进行比较,我们可以看到CNN花费更少的时间进行训练,从而提供了相似的准确性,准确性和召回率。 因此,根据这项研究,我可以得出结论,CNN是最好的算法。
在进行了这项研究之后,我得出结论,像移动网络和CNN这样的算法可用于硬文字识别,车牌检测以及世界各地的银行。 诸如移动网络和CNN之类的算法实现了超过97%的准确度,这优于95%的平均人类绩效。 因此,这些算法可以在现实生活中使用,从而使困难或耗时的过程自动化。
私信译者获得本文代码
(本文翻译自Shubh Patni的文章《Ultimate Showdown of machine Learning Algorithms》,参考:https://towardsdatascience.com/ultimate-showdown-of-machine-learning-algorithms-af68fbb90b06)













