
随着数字化进程的加快,文档、图像等载体的结构化分析和内容提取成为关乎企业数字化转型成败的关键一环,自动、精准、快速的信息处理对于生产力的提升至关重要。以商业文档为例,不仅包含了公司内外部事务的处理细节和知识沉淀,还有大量行业相关的实体和数字信息。人工提取这些信息既耗时费力且精度低,而且可复用性也不高,因此,文档智能技术(Document Intelligence)应运而生。
文档智能技术深层次地结合了人工智能和人类智能,在金融、医疗、保险、能源、物流等多个行业都有不同类型的应用。例如:在金融领域,它可以实现财报分析和智能决策分析,为企业战略的制定和投资决策提供科学、系统的数据支撑;在医疗领域,它可以实现病例的数字化,提高诊断的精准度,并通过分析医学文献和病例的关联性,定位潜在的治疗方案。
什么是文档智能?
文档智能主要是指对于网页、数字文档或扫描文档所包含的文本以及丰富的排版格式等信息,通过人工智能技术进行理解、分类、提取以及信息归纳的过程。
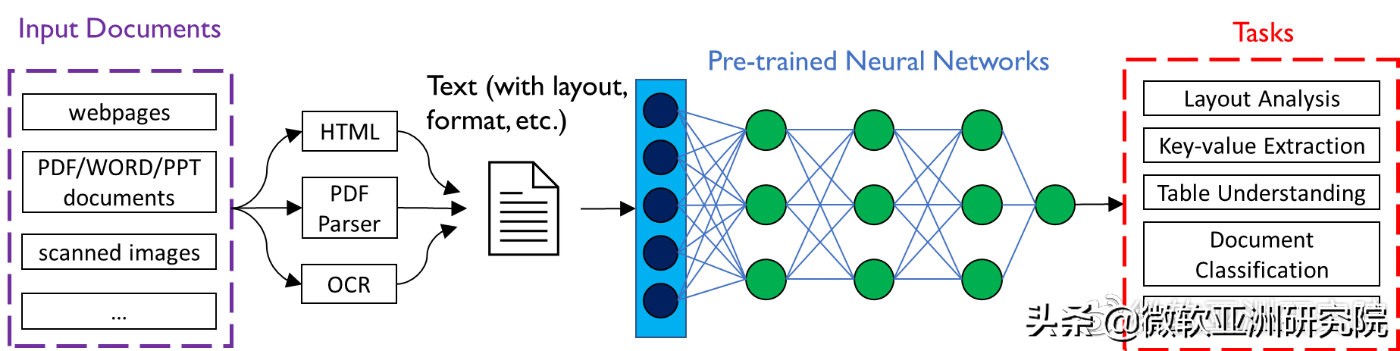
文档智能技术
在过去的30年中,文档智能的发展大致经历了三个阶段。90年代初期,研究人员大多使用基于启发式规则的方法进行文档的理解与分析,通过人工观察文档的布局信息,总结归纳一些处理规则,对固定布局信息的文档进行处理。然而,传统基于规则的方法往往需要较大的人力成本,而且这些人工总结的规则可扩展性不强,因此研究人员开始采用基于统计学习的方法。随着机器学习技术的发展和进步,基于大规模标注数据驱动的机器学习模型成为了文档智能的主流方法,它通过人工设计的特征模板,利用有监督学习的方式在标注数据中学习不同特征的权重,以此来理解、分析文档的内容和布局。
基于深度学习特别是预训练技术的文档智能模型,近几年受到越来越多的重视,大型科技公司纷纷推出相应的文档智能服务,包括微软、亚马逊、谷歌、IBM、阿里巴巴、百度等在内的很多公司在这个领域持续发力,对于许多传统行业的数字化转型提供了有力的支撑。
随着各类实际业务和产品的出现,文档智能领域的基准数据集也百花齐放,这些基准数据集通常包含了基于自然语言文本或图像的标注信息,涵盖了文档布局分析、表格识别、信息抽取等重要的文档智能任务,它们的出现也推动了文档智能技术的进一步发展。

文档智能相关的基准数据集
传统的文档理解和分析技术往往基于人工定制的规则或少量标注数据进行学习,这些方法虽然能够带来一定程度的性能提升,但由于定制规则和可学习的样本数量不足,其通用性往往不尽如人意,而且针对不同类别文档的分析迁移成本较高。随着深度学习预训练技术的发展,以及大量无标注电子文档的积累,文档分析与识别技术进入了一个全新的时代。
微软亚洲研究院提出的 LayoutLM 便是一个全新的文档理解模型,通过引入预训练技术,同时利用文本布局的局部不变性特征,可有效地将未标注文档的信息迁移到下游任务中。LayoutLM 的论文(论文链接:https://arxiv.org/abs/1912.13318)已被KDD 2020 接收,并将在下周举行的 KDD 大会上进行分享。同时,为了解决文档理解领域现有的数据集标注规模小、标注粒度大、多模态信息缺失等缺陷,微软亚洲研究院的研究员们还提出了大规模表格识别数据集 TableBank和大规模文档布局标注数据集 DocBank(论文链接:https://arxiv.org/abs/2006.01038),利用弱监督的方法,构建了高质量的文档布局细粒度标注。
LayoutLM:在预训练阶段实现文本和布局信息对齐
大量的研究成果表明,大规模预训练语言模型通过自监督任务,可在预训练阶段有效捕捉文本中蕴含的语义信息,经过下游任务微调后能有效的提升模型效果。然而,现有的预训练语言模型主要针对文本单一模态进行,忽视了文档本身与文本天然对齐的视觉结构信息。为了解决这一问题,研究员们提出了一种通用文档预训练模型LayoutLM[1][2],选择了文档结构信息(Document Layout Information)和视觉信息(Visual Information)进行建模,让模型在预训练阶段进行多模态对齐。
在实际使用的过程中,LayoutLM 仅需要极少的标注数据即可达到行业领先的水平。研究员们在三个不同类型的下游任务中进行了验证:表单理解(Form Understanding)、票据理解(Receipt Understanding),以及文档图像分类(Document Image Classification)。实验结果表明,在预训练中引入的结构和视觉信息,能够有效地迁移到下游任务中,最终在三个下游任务中都取得了显著的准确率提升。
文档结构和视觉信息不可忽视
很多情况下,文档中文字的位置关系蕴含着丰富的语义信息。以下图的表单为例,表单通常是以键值对(key-value pair)的形式展示的(例如 “DATE: 11/28/84”)。一般情况下,键值对的排布是以左右或者上下的形式,并且有特殊的类型关系。类似地,在表格文档中,表格中的文字通常是网格状排列,并且表头一般出现在第一列或第一行。通过预训练,这些与文本天然对齐的位置信息可以为下游的信息抽取任务提供更丰富的语义信息。

表单示例
对于富文本文档,除了文字本身的位置关系之外,文字格式所呈现的视觉信息同样可以帮助下游任务。对文本级(token-level)任务来说,文字大小、是否倾斜、是否加粗,以及字体等富文本格式都能够体现相应的语义。例如,表单键值对的键位(key)通常会以加粗的形式给出;而在一般文档中,文章的标题通常会放大加粗呈现,特殊概念名词会以斜体呈现,等等。对文档级(document-level)任务来说,整体的文档图像能提供全局的结构信息。例如个人简历的整体文档结构与科学文献的文档结构是有明显的视觉差异的。这些模态对齐的富文本格式所展现的视觉特征,可以通过视觉模型抽取,再结合到预训练阶段,从而有效地帮助下游任务。
将视觉信息与文档结构融入到通用预训练方案
建模上述信息需要寻找这些信息的有效表示方式。然而现实中的文档格式丰富多样,除了格式明确的电子文档外,还有大量扫描式报表和票据等图片式文档。对于计算机生成的电子文档,可以使用对应的工具获取文本和对应的位置以及格式信息;对于扫描图片文档,则可以使用 OCR 技术进行处理,从而获得相应的信息。两种不同的手段几乎可以使用现存的所有文档数据进行预训练,保证了预训练数据的规模。

基于文档结构和视觉信息的 LayoutLM 模型结构
利用上述信息,微软亚洲研究院的研究员们在现有的预训练模型基础上添加了二维位置嵌入(2-D Position Embedding)和图嵌入(Image Embedding)两种新的 Embedding 层,可以有效地结合文档结构和视觉信息:
1) 二维位置嵌入 2-D Position Embedding:根据 OCR 获得的文本边界框 (Bounding Box),能获取文本在文档中的具体位置。在将对应坐标转化为虚拟坐标之后,则可以计算该坐标对应在 x、y、w、h 四个 Embedding 子层的表示,最终的 2-D Position Embedding 为四个子层的 Embedding 之和。
2) 图嵌入 Image Embedding:将每个文本相应的边界框 (Bounding Box) 当作 Faster R-CNN 中的候选框(Proposal),从而提取对应的局部特征。其特别之处在于,由于 [CLS] 符号用于表示整个输入文本的语义,所以同样使用整张文档图像作为该位置的 Image Embedding,从而保持模态对齐。
在预训练阶段,研究员们针对 LayoutLM 的特点提出了两个自监督预训练任务:
1) 掩码视觉语言模型(Masked Visual-Language Model,MVLM):大量实验已经证明 MLM 能够在预训练阶段有效地进行自监督学习。研究员们在此基础上进行了修改:在遮盖当前词之后,保留对应的 2-D Position Embedding 暗示,让模型预测对应的词。在这种方法下,模型根据已有的上下文和对应的视觉暗示预测被掩码的词,从而让模型更好地学习文本位置和文本语义的模态对齐关系。
2) 多标签文档分类(Multi-label Document Classification,MDC):MLM 能够有效的表示词级别的信息,但是对于文档级的表示,还需要将文档级的预训练任务引入更高层的语义信息。在预训练阶段研究员们使用的 IIT-CDIP 数据集为每个文档提供了多标签的文档类型标注,并引入 MDC 多标签文档分类任务。该任务使得模型可以利用这些监督信号,聚合相应的文档类别并捕捉文档类型信息,从而获得更有效的高层语义表示。
实验结果:LayoutLM 的表单、票据理解和文档图像分类水平显著提升
预训练过程使用了 IIT-CDIP 数据集,这是一个大规模的扫描图像公开数据集,经过处理后的文档数量达到约11,000,000。研究员们随机采样了1,000,000个进行测试实验,最终使用全量数据进行完全预训练。通过千万文档量级的预训练并在下游任务微调,LayoutLM 在测试的三个不同类型的下游任务中都取得了 SOTA 的成绩,具体如下:
1) 表单理解(Form Understanding):表单理解任务上,使用了 FUNSD 作为测试数据集,该数据集中的199个标注文档包含了31,485个词和9,707个语义实体。在该数据集上,需要对数据集中的表单进行键值对(key-value)抽取。通过引入位置信息的训练,LayoutLM 模型在该任务上取得了显著的提升,将表单理解的 F1 值从70.72 提高至79.2。
2) 票据理解(Receipt Understanding):票据理解任务中,选择了 SROIE 测评比赛作为测试。SROIE 票据理解包含1000张已标注的票据,每张票据都标注了店铺名、店铺地址、总价、消费时间四个语义实体。通过在该数据集上微调,LayoutLM 模型在 SROIE 测评中的 F1 值高出第一名(2019)1.2个百分点,达到95.24%。
3) 文档图像分类(Document Image Classification):对于文档图像分类任务,则选择了 RVL-CDIP 数据集进行测试。RVL-CDIP 数据集包含有16类总记40万个文档,每一类都包含25,000个文档数据。LayoutLM 模型在该数据集上微调之后,将分类准确率提高了1.35个百分点,达到了94.42%。
DocBank数据集:50万文档页面,以弱监督方法获取高质量标注
在许多文档理解应用中,文档布局分析是一项重要任务,因为它可以将半结构化信息转换为结构化表示形式,同时从文档中提取关键信息。由于文档的布局和格式不同,因此这一直是一个具有挑战性的问题。目前,最先进的计算机视觉和自然语言处理模型通常采用“预训练-微调”范式来解决这个问题,首先在预先训练的模型上初始化,然后对特定的下游任务进行微调,从而获得十分可观的结果。
但是,模型的预训练过程不仅需要大规模的无标记数据进行自我监督学习,还需要高质量的标记数据进行特定任务的微调以实现良好的性能。对于文档布局分析任务,目前已经有一些基于图像的文档布局数据集,但其中大多数是为计算机视觉方法而构建的,很难应用于自然语言处理方法。此外,基于图像的标注主要包括页面图像和大型语义结构的边界框,精准度远不如细粒度的文本级标注。然而,人工标注细粒度的 Token 级别文本的人力成本和时间成本非常高昂。因此,利用弱监督方法,以较少的人力物力来获得带标签的细粒度文档标注,同时使数据易于应用在任何自然语言处理和计算机视觉方法上至关重要。
为此,微软亚洲研究院的研究员们构建了 DocBank 数据集[3][4],这是一个文档基准数据集,其中包含了50万文档页面以及用于文档布局分析的细粒度 Token 级标注。与常规的人工标注数据集不同,微软亚洲研究院的方法以简单有效的方式利用弱监督的方法获得了高质量标注。DocBank 数据集是文档布局标注数据集 TableBank[5][6] 的扩展,基于互联网上大量的数字化文档进行开发而来。例如当下很多研究论文的 PDF 文件,都是由 LaTeX 工具编译而成。LaTeX 系统的命令中包含了标记作为构造块的显式语义结构信息,例如摘要、作者、标题、公式、图形、页脚、列表、段落、参考、节标题、表格和文章标题。为了区分不同的语义结构,研究员们修改了 LaTeX 源代码,为不同语义结构的文本指定不同的颜色,从而能清楚地划分不同的文本区域,并标识为对应的语义结构。
从自然语言处理的角度来看,DocBank 数据集的优势是可用于任何序列标注模型,同时还可以轻松转换为基于图像的标注,以支持计算机视觉中的物体检测模型。通过这种方式,可以使用 DocBank 公平地比较来自不同模态的模型,并且进一步研究多模态方法,提高文档布局分析的准确性。
为了验证 DocBank 的有效性,研究员们使用了 BERT、RoBERTa 和 LayoutLM 三个基线模型进行实验。实验结果表明,对于文档布局分析任务,LayoutLM 模型明显优于 DocBank 上的 BERT 和 RoBERTa 模型。微软亚洲研究院希望 DocBank 可以驱动更多文档布局分析模型,同时促进更多的自定义网络结构在这个领域取得实质性进展。

DocBank 数据集的数据样例
四步构建 DocBank 数据集

DocBank 的处理步骤
研究员们使用 Token 级标注构建 DocBank 数据集,以支持自然语言处理和计算机视觉模型的研究。DocBank 的构建包括四个步骤:文档获取、语义结构检测、Token 级别文本标注、后处理。DocBank 数据集总共包括50万个文档页面,其中训练集包括40万个文档页面,验证集和测试集分别包括5万个文档页面(点击阅读原文,访问DocBank 数据集网站了解更多具体信息)。
文档获取
研究员们在 arXiv.com 上获取了大量科研论文的 PDF 文件,以及对应的 LaTeX 源文件,因为需要通过修改源代码来检测语义结构。这些论文包含物理、数学、计算机科学以及许多其他领域,非常有利于 DocBank 数据集的多样性覆盖,同时也可以使其训练出的模型更加鲁棒。目前这项工作聚焦在英文文档上,未来将会扩展到其他语言。
语义结构检测
DocBank 是 TableBank 数据集的扩展,其中除了表格之外还包括其他语义单元,用于文档布局分析。在 DocBank 数据集中标注了以下语义结构:摘要、作者、标题、公式、图形、页脚、列表、段落、参考文献、节标题、表格和文章标题。
之前的 TableBank 研究使用了 “fcolorbox” 命令标记表格。但是,对于 DocBank 数据集,目标结构主要由文本组成,因此无法很好地应用 “fcolorbox” 命令。所以此次使用 “color” 命令来改变这些语义结构的字体颜色,通过特定于结构的颜色来区分它们。有两种类型的命令可以表示语义结构。
一类是 LaTeX 命令的简单单词,后接反斜杠。例如,LaTeX 文档中的节标题通常采用以下格式:
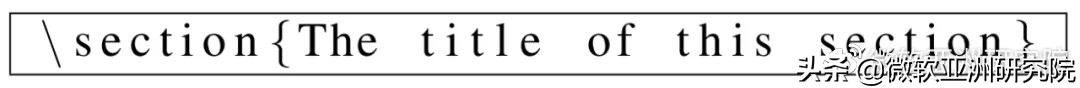
另一类命令通常会启动一个环境。例如,LaTeX 文档中的列表声明如下所示:

begin{itemize} 命令启动一个环境,而 end{itemize} 命令结束该环境。实际命令名称是 “begin” 命令和 “end” 命令的参数。将 “color” 命令插入到语义结构的代码中(如下所示),然后重新编译 LaTeX 文档。同时,为所有语义结构定义特定的颜色,使它们更好地被区分。不同的结构命令要求将 “color” 命令放置在不同的位置才能生效。最后,重新编译 LaTeX 文档来获取更新的 PDF 页面,其中每个目标结构的字体颜色已修改为特定于结构的颜色。

Token 级别文本标注
研究员们使用 PDFPlumber(基于 PDFMiner 构建的 PDF 解析器)来提取文本行和非文本元素,以及它们的边界框。通过划分空格将文本行分词,由于只能从解析器中获得字符的边界框,因此 Token 的边界框定义是组成 Token 的单词中最左上角坐标和最右下角坐标的集合。对于没有任何文本的元素(例如 PDF 文件中的图形和线条),则在 PDFMiner 中使用其类名和两个“#”符号将其组成一个特殊标记。表示图形和线条的类名分别是 “LTFigure” 和 “LTLine”。
PDFPlumber 可以从 PDF 文件中以 RGB 值的形式,提取字符和非文本元素的颜色。通常,每个 Token 由具有相同颜色的字符组成。如果不是的话,则使用第一个字符的颜色作为 Token 的颜色。根据上述的颜色到结构的映射,可以确定 Token 级别的文本标签。此外,语义结构可以同时包含文本和非文本元素。例如,表格由单词和组成表格的线条构成。在这项工作中,为了使模型在元素被切分之后能够尽可能地获取表格的布局,单词和线条都被标注为“表格”类。
后处理
在某些情况下,一些 Token 天然具有多种颜色,并且无法通过 “ color” 命令进行转换,例如 PDF 文件中的超链接和引用,这些不变的颜色将导致标记的标注错误。因此,为了更正这些 Token 的标签,还需要对 DocBank 数据集进行一些后处理步骤。
通常,相同语义结构的 Token 将按阅读顺序组织在一起。因此,一般在相同的语义结构中连续的标记都具有相同的标签。当语义结构交替时,边界处相邻 Token 的标签将不一致。研究员们会根据文档中的阅读顺序检查所有标签。当单个 Token 的标签与其上文和下文的标签不同,但上文和下文的标签相同时,会将此 Token 的标签校正为与上下文标记相同。通过手动检查,研究员们发现这些后处理步骤大大改善了DocBank 数据集的质量。
实验数据统计
DocBank 数据集具有12种语义单元,DocBank 中训练集、验证集和测试集的统计信息,显示了每个语义单元的数量(定义为包含该语义单元的文档页面数量),以及占总文档页面数量的百分比。由于这些文档页面是随机抽取并进行划分的,因此语义单元在不同集合中的分布几乎是一致的。
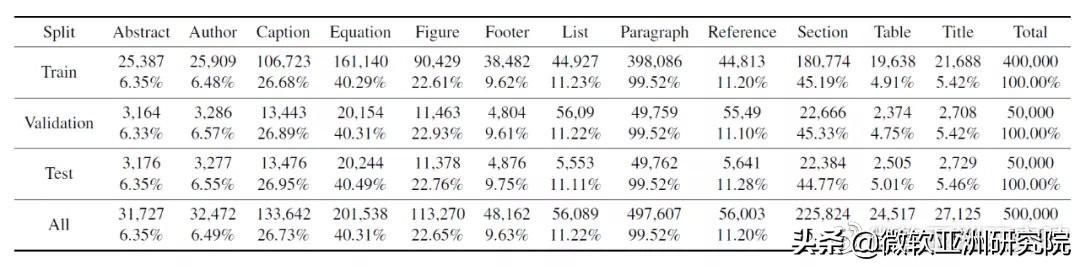
DocBank 中训练、验证和测试集的语义结构统计信息
年份统计信息中展示了不同年份文档页面的分布,可以看到论文的数量是逐年增加的。为了保持这种自然分布,研究员们随机抽取了不同年份的文档样本以构建 DocBank,而没有平衡不同年份的数量。

DocBank 中训练、验证和测试集的年份统计信息
DocBank 与现有的文档布局分析数据集(包括 Article Regions、GROTOAP2、PubLayNet 和 TableBank)的比较显示,DocBank 在数据集的规模和语义结构的种类上都超过了现有的数据集。而且,表格中所有数据集都是基于图像的,只有DocBank 同时支持基于文本和基于图像的模型。由于 DocBank 是基于公开论文自动构建的,因此具有可扩展性,可以随着时间继续扩大数据规模。

DocBank 与现有的文档布局分析数据集的比较
评价指标
由于模型的输入是序列化的二维文档,所以典型的 BIO 标签评估并不适合这个任务。每个语义单元的 Token 可以在输入序列中不连续地分布。针对基于文本的文档布局分析方法,研究员们提出了一个新的指标,其定义如下:

实验结果
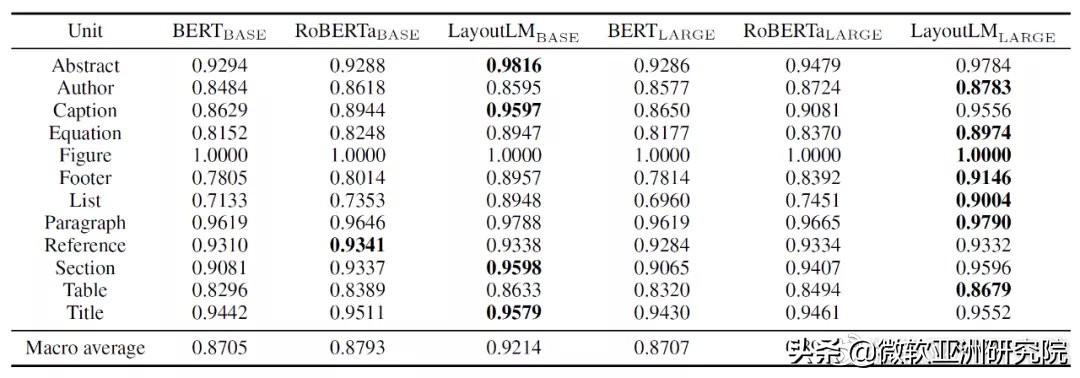
LayoutLM、BERT、RoBERTa 模型在 DocBank 测试集的准确性
在 DocBank 的测试集上评估了六个模型后,研究员们发现 LayoutLM 在摘要、作者、表格标题、方程式、图形、页脚、列表、段落、节标题、表格、文章标题标签上得分最高。在其他标签上 LayoutLM 与其他模型的差距也较小。这表明在文档布局分析任务中,LayoutLM 结构明显优于 BERT 和 RoBERTa 结构。

测试集上预训练 BERT 模型和预训练 LayoutLM 模型的样例输出
研究员们又选取了测试集的一些样本,将预训练 BERT 和预训练 LayoutLM 的输出进行了可视化。可以观察到,序列标记方法在 DocBank 数据集上表现良好,它可以识别不同的语义单元。对于预训练的 BERT 模型,某些 Token 没有被正确标记,这表明仅使用文本信息仍不足以完成文档布局分析任务,还应考虑视觉信息。
与预训练的 BERT 模型相比,预训练的 LayoutLM 模型集成了文本和布局信息,因此它在基准数据集上实现了更好的性能。这是因为二维的位置嵌入可以在统一的框架中对语义结构的空间距离和边界进行建模,从而提高了检测精度。
结束语
信息处理是产业化的基础和前提,如今对处理能力、处理速度和处理精度也都有着越来越高的要求。以商业领域为例,电子商业文档就涵盖了采购单据、行业报告、商务邮件、销售合同、雇佣协议、商业发票、个人简历等大量繁杂的信息。机器人流程自动化(Robotic Process Automation,RPA) 行业正是在这一背景下应运而生,利用人工智能技术帮助大量人工从繁杂的电子文档处理任务中解脱出来,并通过一系列配套的自动化工具提升生产力,RPA的关键核心之一就是文档智能技术。
传统的人工智能技术往往需要利用大量的人工标注数据来构建自动化机器学习模型,然而标注数据的过程费时费力,通常成为产业化的瓶颈。LayoutLM 文档理解预训练技术的优势在于,利用基于深度神经网络的自学习技术,通过大规模无标注数据学习基础模型,之后再通过迁移学习技术仅需少量标注数据即可达到人工处理文档的水平。目前,LayoutLM 技术已经成功应用于微软的核心产品和服务中。
为了推动文档智能技术的发展,LayoutLM 的相关模型代码和论文也已经开源(https://aka.ms/layoutlm),并受到了学术界和工业界的广泛关注和好评,据媒体报道在金融智能分析领域已经有机构开始采用 LayoutLM 模型[7]进行流程自动化的集成和部署,同时也有相关机构采用 LayoutLM 模型[8]进行文档视觉问答(Document VQA)方面的研究工作。相信随着传统行业数字化转型的逐步深入,文档智能研究工作将被更多的个人和企业关注,进一步推动相关技术和行业的发展。
附录
[1]LayoutLM 论文:https://arxiv.org/abs/1912.13318
[2]LayoutLM 代码&模型:https://aka.ms/layoutlm
[3] DocBank 论文:https://arxiv.org/abs/2006.01038
[4] DocBank 数据集&模型:https://github.com/doc-analysis/DocBank
[5] TableBank 论文:https://arxiv.org/abs/1903.01949
[6] TableBank 数据集&模型:https://github.com/doc-analysis/TableBank
[7] “Injecting Artificial Intelligence into Financial Analysis”:https://medium.com/reimagine-banking/injecting-artificial-intelligence-into-financial-analysis-54718fbd5949
[8] “Document Visual Question Answering”:https://medium.com/@anishagunjal7/document-visual-question-answering-e6090f3bddee













