
DA技术首先应用基于自组织特征映射的聚类技术:利用自组织特征映射神经网络对源域和目标域的样本进行聚类,然后用两级聚类映射方法来识别样本分布相似性最高的目标-源簇。使用自动编码策略将来自一组相似目标簇的样本按照源域进行转换,构建训练集和测试集,最后基于人工神经网络分类器进行分类。
在遥感应用中的主要挑战:目标域样本与源域样本的概率分布不同。然而,目标域分布必须使用仅来自源域的大量标记样本来建模。
a.调整源分类器的参数,对来自目标域的未标记样本进行分类——存在噪声、离群点和固有特性从源域传播的问题。
b.将目标域特征合并到分类器的训练集中
· 土地覆盖分类领域自适应技术的发展趋势
a.第一类强调样本从两个域直接转化为一个可以抵消分布差异的全同子空间。
b.第二类是迁移学习,它使用来自源领域的样本从目标领域中选择信息量最大或最多样化的样本。
a. 两级聚类映射:
在第一级,分别计算第t个目标簇和第s个源簇的特征的差异。然后,将第t个目标簇与第j个特征差异最小的源簇配对。除此之外,还对所有成对的目标-源簇对计算了一个置信度度量。在第二阶段,采用半自动阈值选择算法,分离出最相似配对的源-目标簇和不相似的源-目标簇,只保留最相似配对的目标-源簇;同时将剩余的配对排除为不相似簇。
具体为自动编码器将来自最相似配对的目标簇的样本按照相应的源簇转换。对于不相似的目标簇,选取离簇中心最近的r个样本作为标记代表(包含了最终训练集中目标区域分布特征的信息),利用迁移学习过程进行标记。
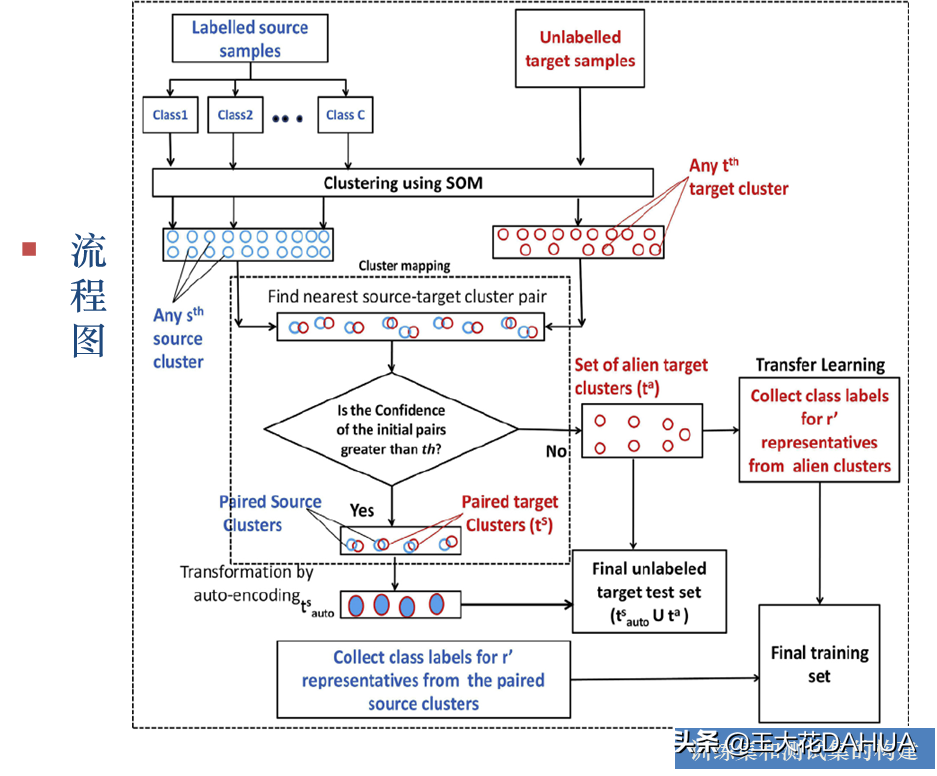
二级聚类映射流程图
b. 自组织特征映射(Self-organizing feature mApping-SOM )
自组织神经网络:输入层模拟感知外界输入信息的视网膜,输出层模拟做出响应的大脑皮层。
主要用于完成的任务基本还是"分类"和"聚类",前者有监督,后者无监督。聚类的时候也可以看成将目标样本分类,只是没有任何先验知识,目的是将相似的样本聚合在一起,而不相似的样本分离。
网络的输出神经元之间相互竞争以求被激活,结果在每一时刻只有一个输出神经元被激活。这个被激活的神经元称为竞争获胜神经元,而其它神经元的状态被抑制

自组织特征映射结构
自组织特征映射步骤
(1)向量归一化
(2)寻找获胜神经元 :当网络得到一个输入向量X时,输出层的所有神经元对应的权重向量均与其进行相似性比较,并将最相似的权重向量判为获胜神经元
(3)网络输出与权值调整 :以获胜神经元为中心设定一个邻域半径R,该半径圈定的范围称为优胜邻域,优胜邻域内的所有神经元均按其离开获胜神经元的距离远近不同程度地调整权值。
优胜邻域开始定得很大,但其大小随着训练次数的增加不断收缩,最终收缩到半径为零。
c. 基于ANNs的分类器
多层感知器(MLP)
MLP是一个具有一个或多个隐层的前馈神经网络, 通过最小化期望类标签和预测类标签之间的平方和误差,调整连续层神经元之间节点连接的权重。主要用到径向基函数(RBF),椭圆基函数(EBF),RBF的拓展。

分类流程图
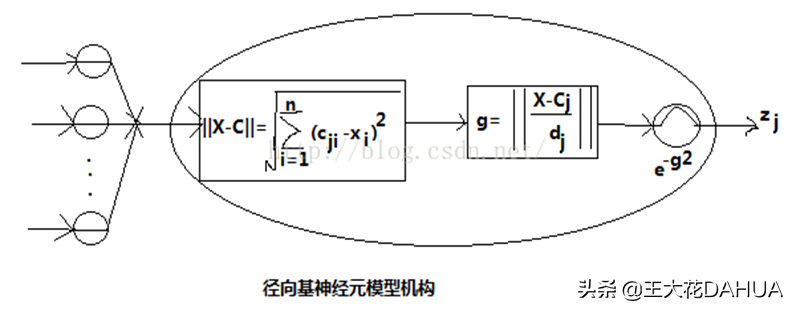
d. 径向基函数神经网络
优点:逼近能力,分类能力和学习速度好,学习收敛速度快、能够逼近任意非线性函数,克服局部极小值问题。(原因在于其参数初始化具有一定的方法,并非随机初始化。)
基本思想:用RBF作为隐单元的"基"构成隐藏层空间,隐藏层对输入矢量进行变换,这样就可以将输入矢量直接(不通过权连接)映射到隐空间(将低维的模式输入数据变换到高维空间内,使得在低维空间内的线性不可分问题在高维空间内线性可分)。隐含层空间到输出空间的映射是线性的,即网络输出是隐单元输出的线性加权和,此处的权即为网络可调参数。
如有错误欢迎指出!
图片来源于网络,侵权请联系删除!





















