原文出自:公众号 程序新视界
原文作者:https://mp.weixin.qq.com/s/GzvwZvVNHx4yjEUVibSNBA
前言
马上就要过春节了,本想着完成手头的任务就可以准备过年了。没想到Netty服务器又被攻击了,当收到服务器报警(CPU飙升报警)信息,就知道对方又下手了。
之前是交给下面的兄弟来解决,这次为了过个好年,决定亲自动手把这事给了结了。
Netty服务是公司比较边缘的服务,只有一台设备在使用,而且代码是之前技术Leader(已离职)写的,加上一直赶工期,所以就没抽出时间去彻底解决这事。
当初被攻击没排查代码,看到遭到疯狂请求、CPU跑满、日志打满,还以为是遭遇DDoS攻击了。
临时采取了几个措施:
但没多久,黑客又找上门来了,十天半月来一次攻击,好像知道服务IP和后台代码似的,阴魂不散。
这不,今天被逮到了,而且之前添加了日志打印,也拿到了攻击的报文内容,复现了攻击操作。
// 攻击者第一次尝试的报文
8000002872FE1D130000000000000002000186A00001977C0000000000000000000000000000000000000000
// 攻击者第二次尝试的报文
8000002872FE1D130000000000000002000186A00001977C00000000000000000000000000000000
上述报文,第一次的报文触发了攻击,第二次的报文没有影响(与正常业务报文格式无异)。
下面就带大家分析分析攻击的逻辑和代码中存在的漏洞。
要了解攻击的原理,我们需要有一定的Netty技术知识。关于Netty如何实现客户端和服务器端的代码这里就不展开了,可以看一下实现实例:https://github.com/secbr/netty-all/tree/main/netty-decoder
我们重点了解一下自定义解码器和io.netty.buffer.ByteBuf。其中自定义解码器用于对报文进行解析,而报文内容通过ByteBuf进行缓存传输。
上面的攻击报文格式表明,黑客已经“猜到”我们是基于16进制Btye格式进行内容传输的(黑客竟然也知道)。
要自定义解码器,继承MessageToMessageDecoder类并实现decode方法即可,下面展示一下示例代码:
public class MyDecoder extends MessageToMessageDecoder<ByteBuf> {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
}
}
其中解析报文的逻辑便是在decode方法内进行处理。其中ByteBuf in就是接收传入报文的容器,而List<Object> out用于输出解析之后的结果。
下面来看一下有bug的代码(已经过脱敏处理):
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
int readableBytes = in.readableBytes();
while (readableBytes > 3) {
in.skipBytes(2);
int pkgLength = in.readUnsignedShort();
in.readerIndex(in.readerIndex() - 4);
if (in.readableBytes() < pkgLength) {
return;
}
out.add(in.readBytes(pkgLength));
readableBytes = in.readableBytes();
}
}
上面的代码在跑正常业务时是没问题的,但当被攻击时,就进入了死循环。因此,导致虽然在业务处理时添加了关闭连接的操作也是无效的。
在分析上面代码之前,我们还得先详细分析一下ByteBuf的原理。
ByteBuf中会维护两个索引:一个索引(readIndex)用于读取,一个索引(writeIndex)用于写入。
当从ByteBuf读取时,readIndex会被递增已经被读取的字节数,当向ByteBuf中写入数据时,writeIndex也会被递增。

上面图以攻击的报文为例进行展示,攻击者用了44个字节的报文进行攻击。由于使用的是16进制,所以两个字符占用1个字节。
readIndex和writeIndex的起始位置的索引位置都为0,当执行ByteBuf中的readXXX或writeXXX方法时,会推进对应的索引。当执行setXXX或getXXX方法的操作时则不会。
了解了ByteBuf的基本处理原理之后,我们就来对照攻击者的报文和源代码来进行攻击过程的还原。
下面直接通过源代码一步步的分析,主要涉及ByteBuf类的方法。有效攻击的报文为上面提到的第一个报文。
// 攻击者第一次尝试的报文
8000002872FE1D130000000000000002000186A00001977C0000000000000000000000000000000000000000
下面来看代码:
int readableBytes = in.readableBytes();
这行代码通过readableBytes方法获取到当前ByteBuf中可以读到的字节数,上述攻击报文88个字符,所以这里得到44个字节。
当readableBytes大于3时便进行具体的解析处理:
in.skipBytes(2);
很明显,通过skipBytes方法跳过了两个字节。

int pkgLength = in.readUnsignedShort();
通过readUnsignedShort方法,获得了2个字节的内容,这两个字节对应的十六进制值为“0028”,对应十进制为“40”。这两个字节在报文中的含义是(部分或整个)报文的长度。
报文的长度往往有两种算法:第一,长度代表整个报文的长度(业务中使用的含义);第二,长度代表除前4个字节之后的报文长度(攻击者使用的含义)。
其实,正是因为这个长度含义的定义,导致正常业务可以执行,而攻击报文会进入死循环。
下面继续分享代码:
in.readerIndex(in.readerIndex() - 4);
经上面的skipBytes和readUnsignedShort的调用,ByteBuf的读索引已经跑到了第4个字节上了。所以这里in.readerIndex()返回的值为4,而in.readerIndex(4-4)的作用就是将读索引重置为0,也就是从头开始读。
if (in.readableBytes() < pkgLength) {
return;
}
这个判断是在读索引移动到0之后,看看报文的可读字节数是否小于报文内容中指定的字节数。很显然,in.readableBytes()对应的值为44个字节,而pkgLength为40个字节,不会进行return。
out.add(in.readBytes(pkgLength));
读取40个字节,进行输出。还剩下4个字节的内容,readIndex指向第40个字节的位置。
readableBytes = in.readableBytes();
由于readIndex已经指向第40个字节,所以此时可读字节数为4。
然后,进入第二轮循环。此时,神奇的情况就出现了。我们可以看到攻击的后4个字节的报文值全为0。
in.skipBytes(2);
int pkgLength = in.readUnsignedShort();
因此跳过2个字节后,readIndex为42,pkgLength获取第43和44字节的值:0。
in.readerIndex(in.readerIndex() - 4);
上述代码又将readIndex设置到第40个字节。
if (in.readableBytes() < pkgLength) {
return;
}
此时会发现readableBytes返回值为4,但pkgLength已经变为0了,不会return。
接下读取内容时就出现状况了:
out.add(in.readBytes(pkgLength));
// 这里还剩下4个字节
readableBytes = in.readableBytes();
上述readBytes读取字节数为0,而readableBytes始终为4。此时,整个while循环进入了死循环,大量消耗CPU资源。
此时还没完,最多只是把CPU跑到100%,但是当不停的将空字符写到接收数据的缓冲区域之后,缓冲区开始疯狂调用处理业务的Handler,进一步侵入到业务处理逻辑当中。
虽然业务逻辑层做了判断,也进行了连接的关闭,但此时已经与连接无关,while循环已经进入死循环,关掉连接也没什么作用。同时,业务层有日志输出,大量的日志输出到磁盘当中,导致磁盘被刷满。
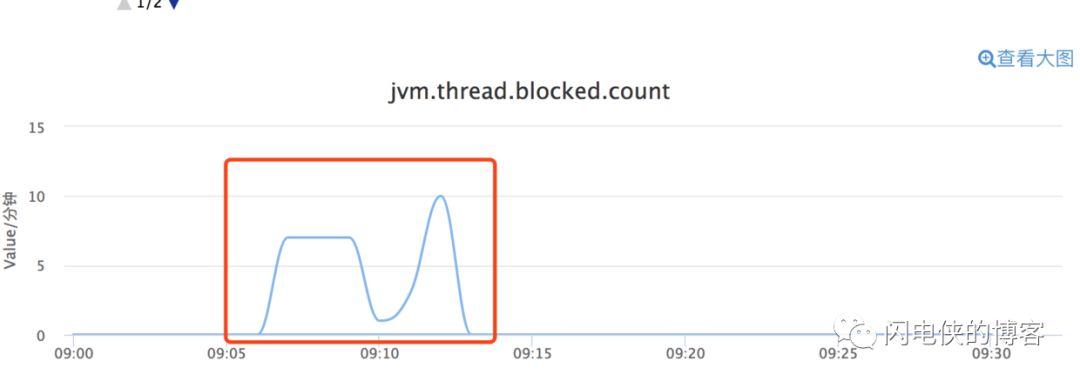
最终导致服务器的CPU监控和磁盘监控报警。乍一看,还以为是又一次DDoS攻击……
总结一下,其实就是攻击者传输的报文长度和报文内指定的长度不一致,导致了解析报文时进入了死循环。
问题一旦发现,解决起来就很容易了。其实通过这件事也得到一些启发。第一,遇到问题,迎难而上解决掉它,往往是最好的方案,逃避只能将问题往后拖,但并不能解决掉。第二,只要静下心来分析,一步步分析,很少有解决不掉的问题。