想必大家都听说过删库跑路吧,我之前一直把它当一个段子来看。
可万万没想到,就在昨天,我们公司的某位员工,竟然写了一个比删库更可怕的 Bug!
给大家分享一下(不是公开处刑),希望朋友们引以为戒。
一、Bug 起因
事情是这样的,昨天中午 11 点左右,突然用户群里的小伙伴反馈:自己直接成为了 鱼聪明 AI 网站 的管理员!
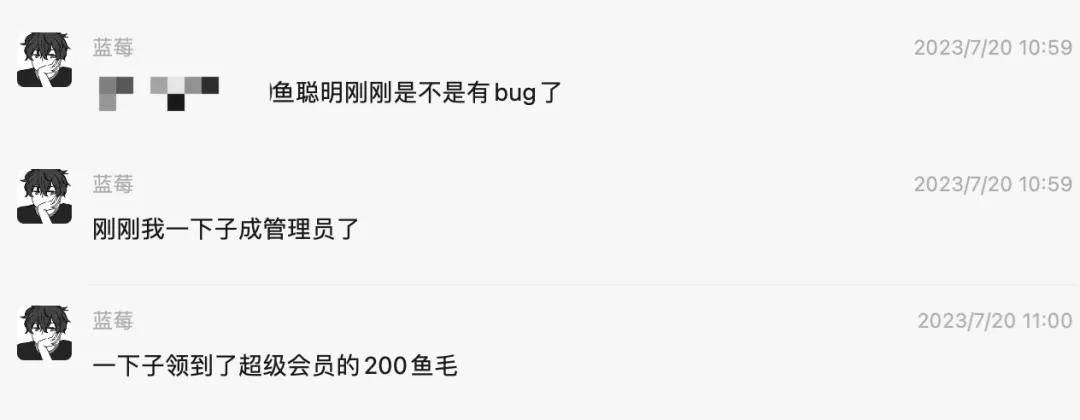
接下来,陆续有更多同学反馈:大家都成管理员了!

看到这里,我立刻就去查了下数据库,结果看到的是:
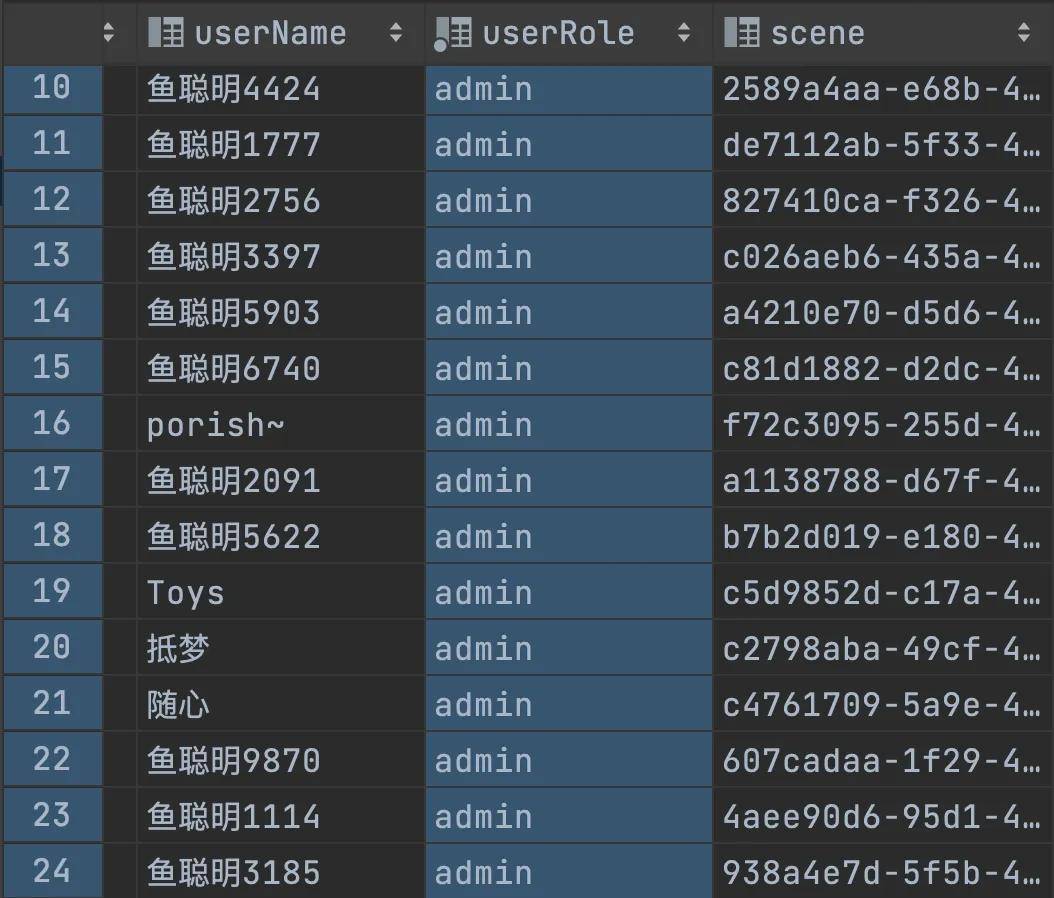
好家伙,早起脑供血不足的我立刻高血压上来了,怎么所有的用户都变成管理员了?!
我赶紧问下我所有的员工,这特么是谁干的!!!
然后员工小 A 大叫:“我 X,是我今天执行单元测试更新数据的时候,少加了个 where 条件!”
本来的预期:update user set userRole = 'admin' where id = 1
实际上执行:update user set userRole = 'admin'
于是导致整个库里的所有用户都变成了管理员,大家可以愉快地薅鱼毛了。
二、紧急处理
后来据这位写 Bug 的同学的回忆,由于她之前没有遇到过类似的情况,第一时间脑袋是一片空白、头嗡嗡的,完全不知道接下来要怎么做。
不过我是很冷静的,因为之前在公司处理过类似的情况,毕竟曾经凌晨 4 - 5 点的时候都被叫起来过。。。
所以立刻就给他发了一段处理方式:

解释一下,就跟我们在路上看到一起交通事故一样,第一时间要么是保护现场,放一个小牌牌不让大家进到事故发生地;要么就是防止扩大影响,人工疏导不让更多人围观、阻塞交通。
一般这两件事情是同时执行的,由于我知道怎么能够判定哪些用户本来是 VIP(比如通过 VIP 信息)、而且程序又有详细的日志,所以第一时间是让员工先把 user 表的所有角色设置为普通用户权限,防止有人继续利用管理员权限去做一些不好的事情。
接下来就是立刻停止了线上的前后端服务,一方面是为了后面好恢复数据,另外也是防止一些同学发现自己突然从会员变成了普通用户,增加大量的人工咨询成本。
所以当时很多同学访问鱼聪明时,看到了这样的截图:

稳定现场后,接下来就是想办法恢复数据到正常的状态,好在我给数据库设置了分钟级别的备份,可以直接把数据恢复到事故发生前的最近正常的时间点。
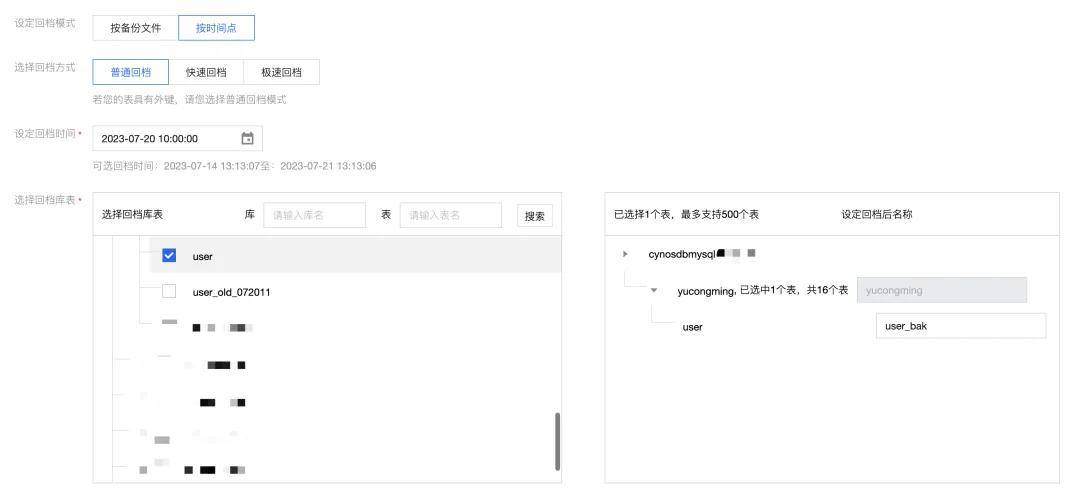
有了备份后的老数据,还要考虑恢复这个时间点后新增的用户数据。
有很多种恢复策略,我优先选择了逻辑最简单的策略:直接更新用户 updateTime > '2023-07-20 10:00:00' 的数据,根据 id 点对点覆盖除了 userRole 之外的数据列;如果没有对应的 id,新增一条数据。也就是使用类似 saveOrUpdate 的方法。
理想很丰满,现实很残酷。万万没想到,由于 updateTime 是一个发生数据修改时自动更新的字段,导致所有的数据 updateTime 全是最新的,相当于要把数据库全量的数据都去比较一遍。
于是我的员工呢,写了类似下面这样的程序:
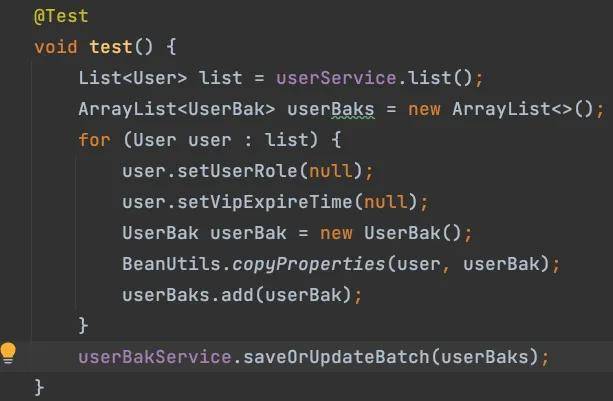
然后就开始执行了,结果执行了很久很久,数据都没更新完。
看来单线程还是太慢了,于是我用并发编程的方式改进了同步的过程。先把所有用户分组,然后多线程同时执行 saveOrUpdateBatch 方法。
示例代码如下:
void restoreUserTable() {
List<User> userList = userService.list();
List<UserBak> userBakList = userList.stream().map(user -> {
user.setUserRole(null);
UserBak userBak = new UserBak();
BeanUtils.copyProperties(user, userBak);
return userBak;
}).collect(Collectors.toList());
int batchSize = 1000;
// 使用 lambda 表达式将 userList 每1000个元素分为一组
List<List<UserBak>> groupedBakUsers = IntStream.range(0, userList.size())
.boxed()
.collect(Collectors.groupingBy(index -> index / batchSize)) // 将索引按组分组
.values()
.stream()
.map(indices -> indices.stream()
.map(userBakList::get) // 根据索引获取 User 对象
.collect(Collectors.toList())) // 每组1000个元素的列表
.collect(Collectors.toList()); // 所有分组的列表
List<CompletableFuture<Void>> completableFutureList = new ArrayList<>();
int i = 1;
for (List<UserBak> groupedBakUser : groupedBakUsers) {
int finalI = i;
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> {
boolean b = userBakService.saveOrUpdateBatch(groupedBakUser, batchSize);
});
i++;
completableFutureList.add(completableFuture);
}
CompletableFuture.allOf(completableFutureList.toArray(new CompletableFuture[]{})).join();
}
使用这种方式,很快数据就恢复完成了。
当然,还有更简单的方式,比如联表查询、对比哪些数据行发生了变动,再去做修改。只不过当时情况紧急、再加上数据库量级可控,我们选择了相对理解成本最低的方式。
之后,我这边又手动做了一次全量备份,并且思考了一下还有没有遗漏的问题,才恢复上线。
三、事后复盘
整个事故时长接近 2 个小时,大致分为:
从某种意义上来说,这次的事故比直接删库更严重!因为删库了赶紧恢复就好,但这次不仅出现了 “数据污染”,还出现了 “越权” 的问题,我们网站内仅管理员可见的敏感信息会存在泄露风险。好在我们也没什么敏感信息哈哈。
还有就是用户可能会利用漏洞来薅鱼毛(管理员可以大量获取),但经过我们的统计,这段时间利用漏洞薅鱼毛的人数寥寥无几,大家都是非常善良的,这才放下心来。
虽然这次的事故带来的损失不是特别大,但也发现了我们系统存在的问题。
我也跟这位员工说:出了事情不可怕,可怕的是不知道改正,出现同样的事情。
那么应该如何防止出现类似的事故呢?
1、控制操作权限
为了防止用户执行 update、delete 操作时不小心漏掉了 where 条件、直接更新全量数据,企业中一般是会禁止不带 where 条件的修改操作的。
出现这次的事故后,我也立刻给 MySQL 开启了 sql_safe_updates 配置:
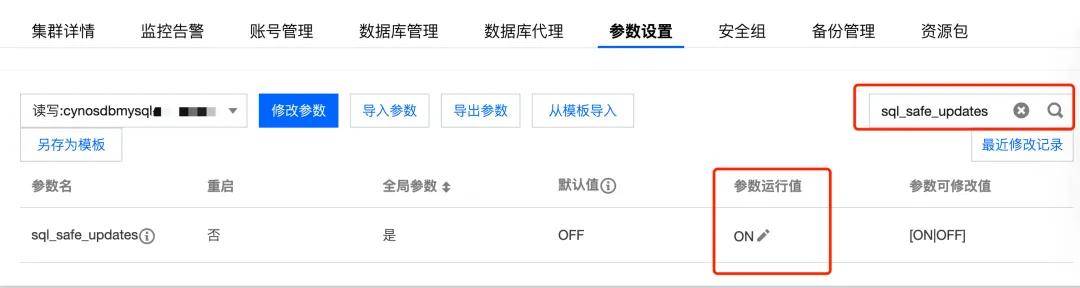
缺少 where 条件的更新会直接触发下列报错:

之前为什么没加?主要是因为以前都是自己一个人开发系统,而且会有需要全量更新的场景,图省事儿。
2、生产环境隔离
正常情况下,不应该允许直接在本地连接和操作线上数据库的数据。而是需要先编写代码、提交代码审核、发布上线后,再执行修改操作。
像这次的事故,如果员工不是本地直接更新数据库,而是提交代码给我看一下,我大概率就会发现他少写了更新条件,就能防止了。
其实之前在腾讯的时候,我都会严格注意这些事项的。但之所以现在自己公司的项目是允许员工在本地连接线上的,想必大家也能猜到原因 —— 业务规模小、人数少,直接在同一个库开发会方便一些。
但如果项目的规模上来了,一定要做好多套环境的隔离,本地环境、测试环境、预发布环境、线上环境都要严格区分了。
3、SQL 审批
之前在腾讯的时候,想要修改关键库的数据,不能直接执行 SQL 语句,而是要先把 SQL 语句提交到审核平台,等你的领导和数据库运维确认没问题后,才能执行。这样每条 SQL 都是至少有 2 个人看过的,能够大大增加安全性。
曾经我觉得这种机制很麻烦,但经历过一些血泪教训后,才意识到这个环节真的是泰裤辣!
4、数据库审计
数据库审计是指记录和监控数据库的访问及 SQL 语句执行情况,从而精细化风险控制,提高数据安全性。
可以自己在数据库配置(比如开启日志、使用审计插件等),也可以使用第三方云服务自带的审计规则配置。
5、提升风险意识
最不需要技术,却也是最重要的一点,那就是要让团队的所有同学意识到这件事情带来的风险、问题的严重性。
因为你永远叫不醒一个装睡的人,同理,再多的防护也限制不了本身就想搞事的人。
所以这件事情是我和这位员工共同的责任,作为惩罚,我们决定请其他同事喝奶茶。就这么愉快地决定了~
不过也有做的好的地方,比如做了完整又灵活的数据备份,这是线上项目必备的操作。
以上就是本期分享,希望大家不仅是看个乐,也能有一些收获和启发,不过希望大家都不要遇到这类闹心的事情。
作者丨程序员鱼皮
来源丨公众号:程序员鱼皮(ID:coder_yupi)