
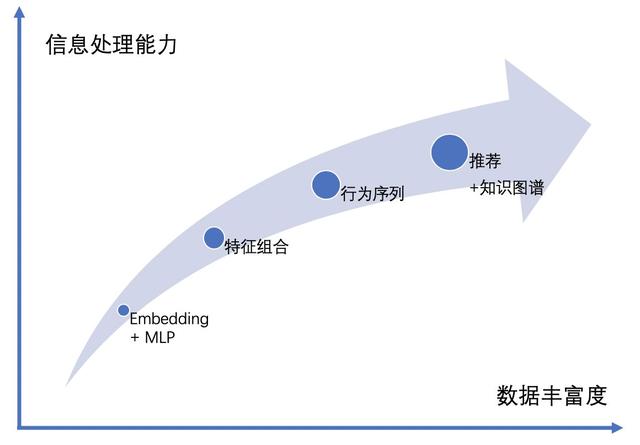
近些年,随着深度学习理论,GPU 和 CPU 等计算机硬件,TensorFlow、Caffe、PyTorch 等算法平台的发展,深度学习算法在个性化推荐、计算机视觉、自然语言处理、语音识别等领域大放光彩。本文从神经网络结构的角度梳理深度推荐算法的发展,把近几年业界主流的算法归纳为四个阶段的网络结构:Embedding+MLP 的网络结构,基于特征组合的网络结构,基于用户行为序列的网络结构和融入知识图谱的网络结构。
2016 年,谷歌发表的 Wide&Deep 模型[1]和 YouTube 深度学习推荐模型[2]在业界引起了广泛的关注。在当时,推荐领域的深度学习算法落地还非常少,大多数公司还处在使用 CF(协同过滤)进行召回和 LR(逻辑回归)进行排序的阶段,工程师们把主要精力花在特征挖掘上来提升效果。这两篇论文的发表给大家带来了新方向,深度学习推荐算法的相关论文也如雨后春笋般涌现。
谷歌的这两个模型都是基于 Embedding + MLP 的网络结构。Embedding 的应用使得深度学习算法有了强有力的离散特征处理能力,MLP(多层感知机)使得算法有了强大的非线性拟合能力。两者的配合使用,模型的拟合能力大大超越了使用 0-1 离散特征的 LR 模型。Embedding + MLP 的网络结构也成为了当前深度学习推荐算法的基础结构。
谷歌在《Deep Neural Networks for YouTube Recommendations》[2]论文中提出的召回模型不仅算法具有创新性,而且在大规模召回的工业场景中非常实用。通过抽取最后一层的用户向量和视频向量,配合高效的近邻搜索算法,可以实现工业级的在线大规模召回。这篇论文有更多的技术细节值得深究,可参考知乎的一些解读,这里不在赘述。e.g. https://zhuanlan.zhihu.com/p/52169807
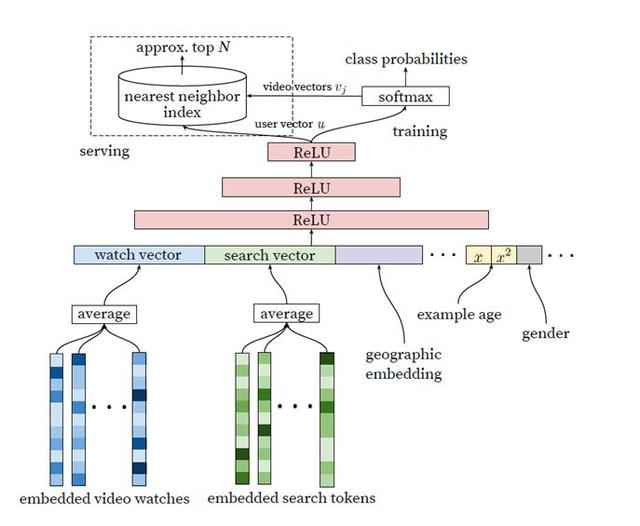
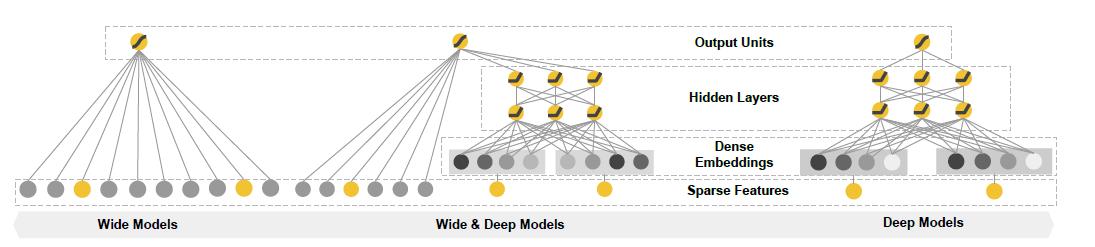
在《Wide & Deep Learning for Recommender Systems》[1]中,Wide 侧使用的是线性结构 y= w*x +b,通过对 0-1 离散特征的交叉组合,模型可以非常有效地学到这部分可解释性非常强的信息。Deep 侧则采用了 Embedding+MLP 的结构,通过 Embedding 把稀疏高维离散特征转化成了低维稠密的连续特征,并将该特征和连续类特征拼接在一起放入 MLP 层,通过 MLP 的非线性处理能力去发现线性模型无法捕捉的更深层次特征组合效应。两部分模型的联合使用带来了超越传统模型的效果。
特征工程是整个推荐工作中的重要组成部分,特征工程能带来很好的效果提升,但同时也耗时耗力。深度学习算法天然有着强大的拟合能力,随着神经网络结构的发展,特征工程的复杂度和必要性在不断的在降低,工程师们可以把更多的精力聚焦于算法的优化上。
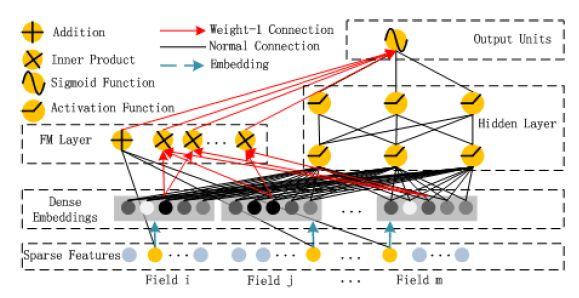
在 Wide&Deep 的模型中,Wide 侧 0-1 离散特征的交叉组合带来了很好的效果,但需要人工进行特征工程。在 2017 年发表的《DeepFM:A Factorization-machine based Neural Network for CTR Prediction》[3]的模型中,离散特征经过 Embedding 层后获得的低维稠密向量,通过在 FM Layer 进行两两的 Inner product 操作实现了 Order-2 的特征组合。DeepFM 的应用,使得这个模型基本不需要特征工程,而且性能在某些数据集上超过了 Wide&Deep 模型。
仔细对比 Wide&Deep 和 DeepFM,会发现 DeepFM 只进行了 Order-2 和 Order-1 的特征组合,而 Wide&Deep 模型中的 Wide 侧实现了更高阶的特征组合。DeepFM 是否可以做更高阶的特征组合呢?直观的推想,在 FM Layer 可以加入 Order-3、Order-4 的特征组合,但是参数会急剧上升。在 FM Layer,假设有 m 个 field,每个 field 经 Embedding 层后形成了 k 维稠密向量,Order-2 的特征组合需要 O(k*m^2)的参数,Order-3 的特征组合则需要 O(k *m^3)的参数,参数量的快速增长导致 DeepFM 不适合进行更高阶的特征组合。
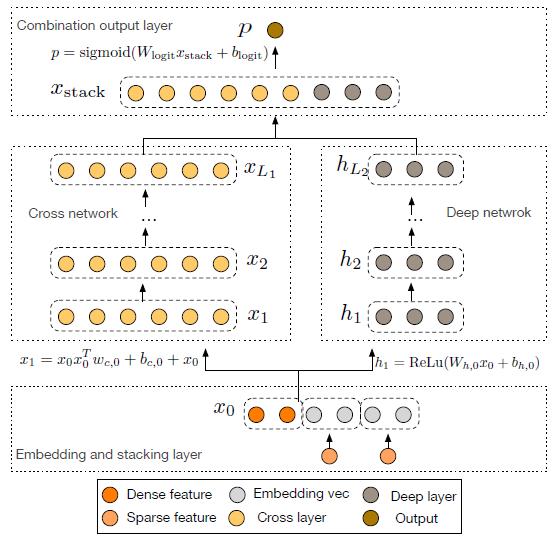
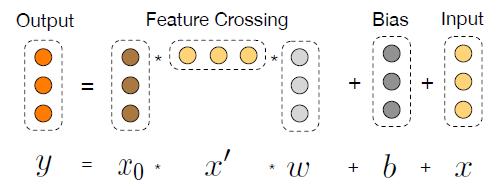
在《Deep & Cross Network for Ad Click Predictions》[4]这篇论文里直接提到了 FM、FFM 类的算法由于参数爆炸无法生成并处理高阶特征组合的问题。如图 5 所示采用了一种比较巧妙的方式进行特征组合,在 DCN 的每一层 cross net 中,参数 w 是一个 n *1 维的向量(n 为交叉特征的维数),随着层数 k 的增长,参数是以 O(k *n)的速度增长,通过这样的设计,Order-3、Order-4 甚至更高阶的特征组合并不会带来参数的爆炸。当然这里还是会有一些信息损失,与 DeepFM 相比较,每个交叉特征的参数并非完全独立。
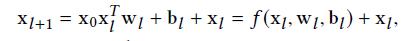
在电商推荐、信息流推荐和短视频推荐等领域,行为序列有效的代表了用户偏好。传统的机器学习算法,或是 Embedding+MLP 的神经网络很难使用原始的序列作为特征,一般是把序列做进一步的特征工程才能放入模型。2017 年前后,基于行为序列的算法不断的发展完善,逐渐成为主流的推荐算法。
基于行为序列的推荐模型总体来看存在五个挑战[5]:
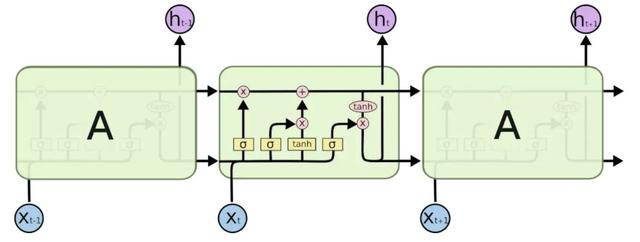
RNN、GRU 和 LSTM 被设计用来处理序列结构的数据,其计算方式是顺序的,能从左往右、或从右往左依次计算。这样的计算方式存在一些问题:时间片 t 的计算只依赖于 t-1 的结果,计算过程中信息会丢失,尽管 GRU 和 LSTM 的机制在一定程度上缓解了长期依赖的问题,但对于特别长的序列,GRU 和 LSTM 依然处理不好。一般在 RNN、GRU、LSTM 在处理序列时,会结合 pooling layer 一起使用,一方面长序列不适合直接放入下一层的全连接网络,另一方面通过 max pooling 或者 mean pooling,可以做一定的信息抽取。总体来看,RNN 类型的网络结构,基本无法解决前述的五个挑战,另一方面这样串行式的计算,在当前 GPU 的结构上运行效率较低。
Attention 机制的出现带来了神经网络发展的新方向,RNN(GRU、LSTM)结合 Attention 机制的网络结构取得了不错的效果。阿里巴巴的 DIN(Deep Interest Net)中 Activation Unit 也使用了相似的思想,因为用户的兴趣并不是唯一的,在面对不同的物品时,这样 Activation Unit 的机制能够在用户历史行为中行挑选出相关的信息。
谷歌的 Transformer[6]和 BERT[7]是 Attention Based Model 中的集大成者,这两个网络结构先后在自然语言处理领域中把算法效果提升到了新高度。
在 Encoder-Decoder 架构的模型中以前一般以 RNN 为主导,Transformer 是第一个完全基于 attention 的序列模型。Transformer 的网络结构可以把序列中任意两个位置的距离缩小为常量,并且具有很好的并行性。在文本翻译任务中,Transformer 的运行速度要远远快于 RNN 类的模型。Github 上对 Transformer 由非常好的解读[8],这里不再赘述。
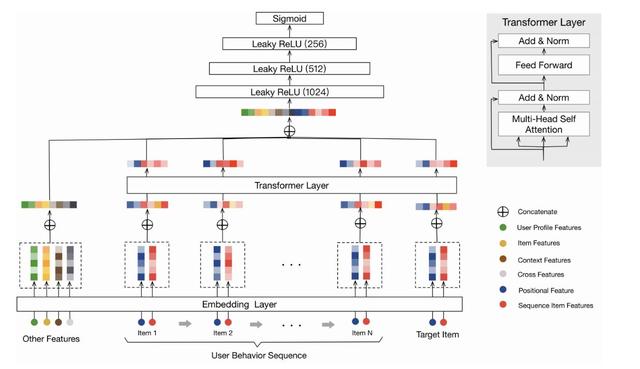
Transformer 也被应用到了推荐领域,阿里巴巴发表的《Behavior Sequence Transformer for E-commerce Recommendation in Alibaba》[9]通过 Transformer 抽取用户行为序列中的信息,并与其他特征拼接到一起放入 MLP 层,最终建模成一个二分类问题。当然这里做了一些适配,比如原始版本的 Transformer 中使用了 positional embedding 来捕捉句子中的顺序信息,在推荐中,作者使用了物品曝光时间与点击时间之间的差作为“positional embedding”的输入。在文中,Transformer 的输入层只使用了物品的 item_id 和 category_id 作为特征。回顾上文描述的五个挑战,基于 Transformer 的推荐可以很好的解决前三个挑战,后两个问题,从网络结构上来看,并不能很好的解决。
2018 年,谷歌发表了论文《Bert: Pre-training of deep bidirectional transformers for language understanding》,BERT 的全称是 Bidirectional Encoder Representations from Transformer,从名称上也可以看出来 BERT 从 Transformer 中取 Encoder 部分,进行双向的表示学习。BERT 有两个版本的模型,Base 版本使用了 12 层的 Encoder,Large 版本的使用了 24 层的 Encoder,在 NLP 领域应用时,都需要大量的数据进行预训练,因为一般在实际应用时会使用谷歌预训练好的 BERT 模型,然后再基于应用场景的数据进行 fine-tuning 使之很好的适用于当前的场景。论文的题目中有四个关键词,Pre-training,Deep,Bidirectional,Transformer,正是这四个关键词使得算法在 Language Understanding 场景中取得了 state of art 的效果。
BERT 也被应用到了推荐场景,在《BERT4Rec-Sequential Recommendation with Bidirectional》[10]中问题被定义为基于用户的历史行为序列来预测下一个物品。文中使用 BERT 来处理用户的行为序列,可以说是一种比较“完美”的结构,在序列推荐中,个人认为很难再有模型在结构上能超越 BERT。不过在该文中,用户侧的特征和场景的特征没有被应用起来,只是用了用户行为序列,这一点其实也值得探索。和基于 Transformer 的推荐类似,序列推荐的五个挑战中,前三个能够很好的解决,后两个问题从结构上看也不能很好的解决。
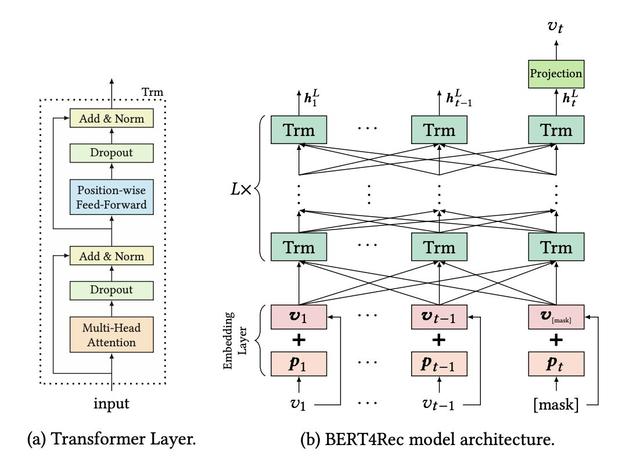
从网络结构的角度,RNN、CNN,甚至 Transformer、BERT 都可以由全连接神经网络表示,前者只是从全连接神经网络中挑选了部分节点组建的网络,但在具体应用场景中,全连接神经网络却无法达到前者的效果。我想原因有两点:第一,这些具有显著结构的神经网络,其实是一种非常有效的先验知识,而全连接神经网络在当前所使用的训练数据、训练方法下,并不能有效地学习到这些知识;第二,和具有先验结构的神经网络相比,全连接神经网络会有更多的参数,训练的难度大大提升了。
伴随着 Embedding 技术和图神经网络算法的发展,知识图谱在推荐系统、问答系统、社交网络等领域得到了非常广泛的应用。知识图谱在推荐系统中的应用一般可以带来三方面的收益:第一,多样性,基于知识图谱,可以选择不同关系的物品进行推荐;第二,可解释性,通过推荐物品与历史物品间的关系可进行解释;第三,精确性,知识图谱刻画了物品更加立体的信息,通过在模型中加入这些信息提升推荐的效果。
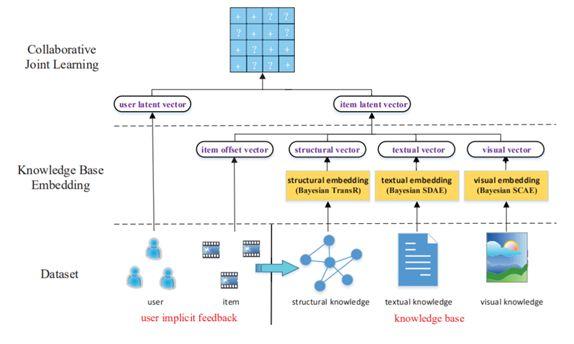
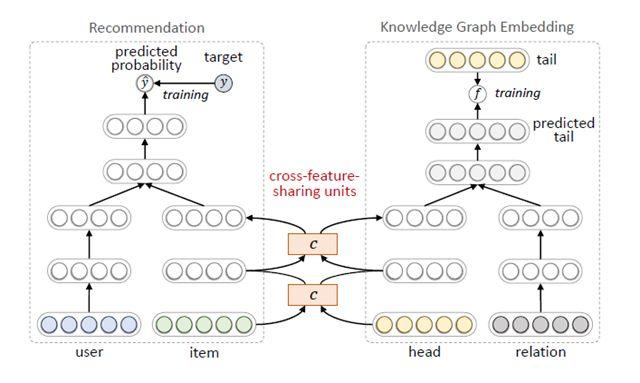
总体来看有三种训练方式可以把知识图谱应用到推荐模型中。第一种是依次训练,基于知识图谱的表示学习,把用户和物品用低维稠密的向量表示,再把向量作为用户和物品的特征放入推荐算法中。这种方法的优点是,知识图谱模型可以独立训练,与推荐模型解耦,不影响推荐模型的训练、预测效率;缺点是知识图谱模型本身更适合实体分类、连接预测等知识图谱的任务,可能并不适合推荐任务,带来的效果增益比起端到端训练的差。第二种是联合训练[11],如图 9 所示,从知识图谱中抽取用户或物品的结构化信息作为特征放入模型,进行端到端的训练。第二种方法效果必然比第一种好,但缺点是训练和预测的效率都会变低,特别是在做在线推理的时候,带来比较大的挑战。第三种方法是交替训练[12],如图 10 所示,把推荐和知识图谱表示学习建模成两个独立的任务,采用多任务学习的框架使用底层部分网络参数的共享,在训练时可固定一端模型的参数,训练另一端模型,两个交替地训练。在推荐算法的推理阶段,可独立运行一端模型,没有额外的开销。通过这种方式,把知识图谱的信息融入到推荐模型中。
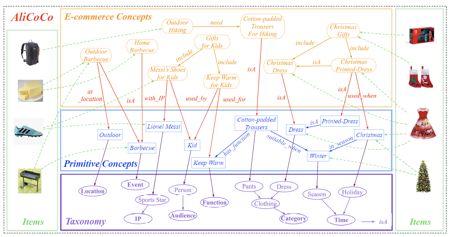
在不同的领域,一般会有基于特定场景的知识图谱建模。在电商领域,AliCoCo[13]是阿里巴巴为搜索和推荐设计的电商知识图谱,传统的推荐算法往往基于用户历史行为而不是知识的角度进行推荐,这种推荐方式存在一个盲点,淘宝推荐使用了基于类目-属性-属性值的底层数据管理体系,该体系导致缺少必要的知识广度和深度去描述用户的需求。当用户搜索“如何举办一次烧烤”时,只能返回单个或几个类目的商品而不能理解用户的一整套需求。如图 11 所示,AliCoCo 设计了四层的概念体系,包括电商概念层、原子概念层、原子概念分类体系和商品层。用电商概念层去表示用户的需求,而每个电商概念都有一个或多个原子概念组成,每个电商概念或者原子概念都会关联多个商品。当用户命中电商概念时,相应的主题推荐界面会被展示,里面不仅仅是食品,也有烧烤相关的工具等。通过这种方式,用户的需求可以被更好的理解。
在零售领域,沃尔玛不仅有线下门店也有线上门店,结合自身业务的需求,沃尔玛建立了商品的知识图谱[14]。通过把业务中商品与商品间的关系、商品与自然语言的关系归纳为 Describe、IsA、Co-buy、Co-view、Substitute 和 Search 六大类,把商品和词汇定义为实体完成了图谱的定义。再基于图神经网络和多任务学习,实现了实体和关系的向量化供下游推荐、搜索等场景的使用。
总结
纵观最近五年业界主流的推荐算法,从一开始 Embedding+MLP 的网络,发展到特征组合的网络,再到基于用户行为序列的网络,到当前的推荐+知识图谱,算法的信息处理能力不断的变强,能够处理的数据也越来越丰富,未来也将持续沿着这个趋势发展。
[1]《Wide & Deep Learning for Recommender Systems》
[2]《Deep Neural Networks for YouTube Recommendations》
[3]《DeepFM: A Factorization-Machine based Neural Network for CTR Prediction》
[4]《Deep & Cross Network for Ad Click Predictions》
[5]《Sequential Recommender Systems: Challenges, Progress and Prospects》
[6]《Attention Is All You Need》
[7]《Bert: Pre-training of deep bidirectional transformers for language understanding》
[8] http://jalammar.github.io/illustrated-transformer/
[9]《Behavior Sequence Transformer for E-commerce Recommendation in Alibaba》
[10]《BERT4Rec-Sequential Recommendation with Bidirectional》
[11]《Collaborative knowledge base embedding for recommender systems》
[12]《Multi-task feature learning for knowledge graph enhanced recommendation》
[13]《AliCoCo: Alibaba E-commerce Cognitive Concept Net》
[14]《Product Knowledge Graph Embedding for E-commerce》
作者:ezewang,腾讯 WXG 应用研究员


















