周彦武
2021年5月26日,极狐阿尔法S 华为HI版正式下线,标志着华为进军自动驾驶迈出关键一步,实现了量产。

图片来源:互联网
华为自动驾驶主要传感器是800万像素的立体双目摄像头和转镜式高线激光雷达。

图片来源:互联网
前风挡玻璃下有4颗摄像头,两侧是立体双目800万像素摄像头,中间是540万像素100°水平FOV摄像头,负责车前侧。
图片来源:互联网
上图可以看出华为800万像素立体双目的水平FOV是60°,但是对单个摄像头是30°,这个比较窄的FOV保证了有效距离比较远,探测车辆有效距离高达500米,小目标如行人或儿童乃至角锥是180米。立体双目阵营的整车厂主要有奔驰、丰田、斯巴鲁、捷豹路虎、本田,此外大众和福特合资的Argo也是立体双目路线。Tier1则有博世、大陆汽车、维宁尔、LG、电装、大疆、日立和华为。
了解华为自动驾驶系统,同样从专利入手,华为是申请专利最积极的公司。2021年4月底,华为一项自动驾驶领域专利正式公开,其中虽然没有直接说立体双目与激光雷达的融合,但仔细看,就是指立体双目与激光雷达的融合。华为还有众多立体双目的专利,包括在线标定、自标定、立体匹配,还有立体双目的L4级泊车。在立体双目L4级泊车的专利里,华为还特别解释了基线长短对测距精度的影响。
为什么要将立体双目与激光雷达融合?激光雷达的缺点是其比较稀疏,即便是最强的Luminar激光雷达也难以和100万像素的摄像头比。再有就是不同物体激光反射率差别极大,同样距离下,可能一辆白色车能探测到,一辆黑色车就探测不到。再比如交通指示牌,激光雷达对其反射回来的高强度回波非常敏感,容易在点云中形成“鬼影”和“膨胀”,这样的点云是不可用的。还有空洞,“空洞”描述的是激光雷达对于近场低矮障碍物的探测在从远到近过程中“时有时无”的丢失现象。障碍物原始点云“时有时无”会让感知算法难以连续跟踪,这容易导致智能驾驶的急刹车或频繁“减速加速”顿挫。除了空洞,还有激光雷达行业内部的术语“吸点”,这就是在近距离跟车时,车牌是强反射目标,与车体的低反射目标容易混淆,测距不准,形成盲区,称之为“吸点”。激光雷达数据的稀疏性与非结构化,导致传统算法无法适应,深度学习这种测不准的黑盒子算法将激光雷达深度信息的高精度造成了衰减。摄像头的缺点是必须有足够的纹理特征,比如颜色完全一致的大货车侧面,平整的水泥路面等没有纹理特征的目标,单目摄像头会完全失效。立体双目虽然此时仍可以探测到目标,但深度信息准确度也会下降。
立体双目某种意义上也可看做一个激光雷达,其提供准确的深度信息,视差图可以转换为点云。因此立体双目与激光雷达融合的效果,远比其他种类的传感器要好,单目通过深度学习可以估算深度,但准确度远不能和测量模式的立体双目比。
图片来源:互联网
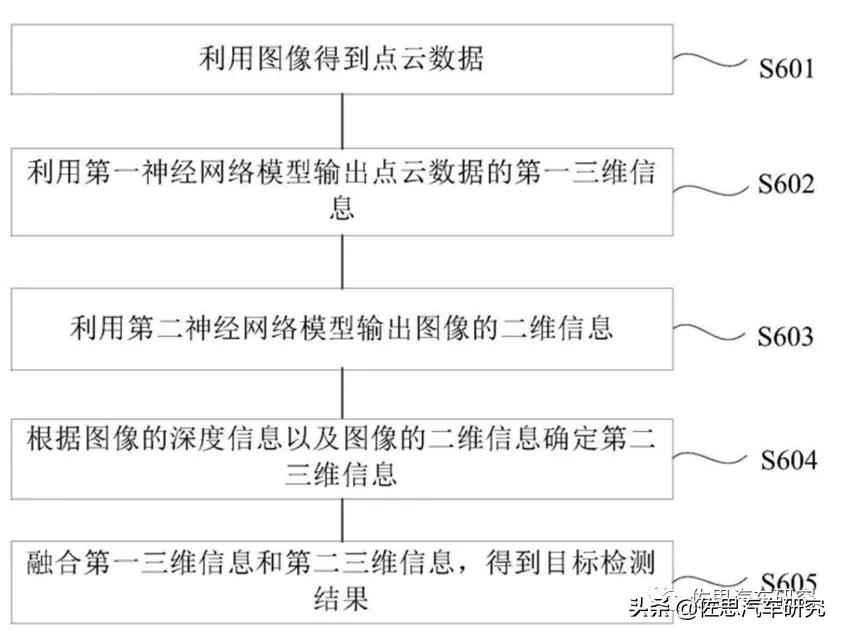
华为专利里讲的非常复杂,并且只字未提激光雷达,但显然,能提供准确可靠的三维信息的只有激光雷达和立体双目,自然是两者间的融合。华为对立体双目做了比较详细的描述,即S601步骤,S601包括S6011图像获取,S6012标定相机获取相机参数,S6013图像数据立体校正,S6014图像数据预处理,S6015立体匹配,立体匹配是立体双目视觉的核心难点,华为专利里是这么写的:通过极线约束及双目相机与目标物体的距离估计出的视差搜索空间,从而减少匹配的搜索范围;通过多重网格技术引进粗网格系列加速偏微分方程的收敛,提高匹配速度;通过细网格迭代,将残差从最细网格依次限制到粗糙的网格中,运用像素的灰度、梯度及平滑度相结合的相似度判断准则在粗网格搜索空间内寻找匹配点,得到视差值;将粗网格得到的视差值依次延拓到细网格,通过组合修正得到最终匹配点的视差值;按照以上步骤在整幅图像数据上进行遍历,直到得到完整连续的视差图。S6016点云重建,通过双目立体系统深度恢复原理,获取图像数据每个点的三维空间坐标,得到图像数据对应的点云数据;对点云数据进行基于移动最小二乘法的平滑滤波,获取平滑后的点云数据。
S602阶段,利用激光雷达的点云数据用深度学习模型推理得出第一个三维信息立体框,业内一般叫3D BBX。S603和S604实际是一步,将2D深度学习推理后的信息(即语义分割)与立体双目的深度信息融合获得第二个三维信息立体框,最后将两个三维信息融合。可以看做是2D图像、立体双目深度图和激光雷达的三融合。
图片来源:互联网
传感器融合是非常困难的,通常都是吃力不讨好的,花费巨大,效果极有可能反而不如单一传感器,这是因为相机通过将真实世界投影到相机平面来记录信息,而点云则将几何信息以原始坐标的形式存储。就数据结构和类型而言,点云是不规则,无序和连续的,而图像是规则,有序和离散的。这导致了图像和点云处理算法方面的巨大差异。但立体双目的视差图可以转换为点云,融合难度大大降低。
奔驰和丰田的自动驾驶上,是以双目为核心,以低线束激光雷达辅助,是简单的弱融合。而华为使用了3个高线束激光雷达,应该是强融合。
图片来源:互联网
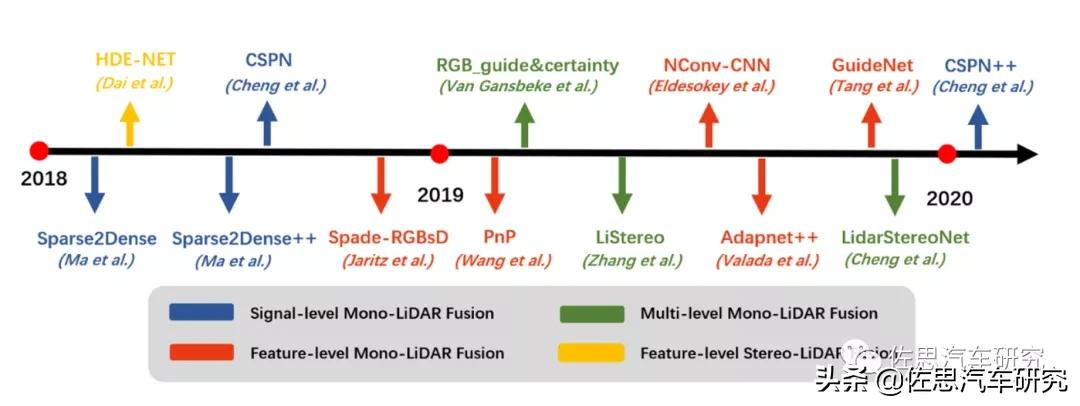
激光雷达与视觉融合的发展时间线如上图,当然这些都是实验室级别的,没有进入实用阶段。有单级的如像素级或体素Voxel融合,有提取特征的特征级融合,也有多级融合。
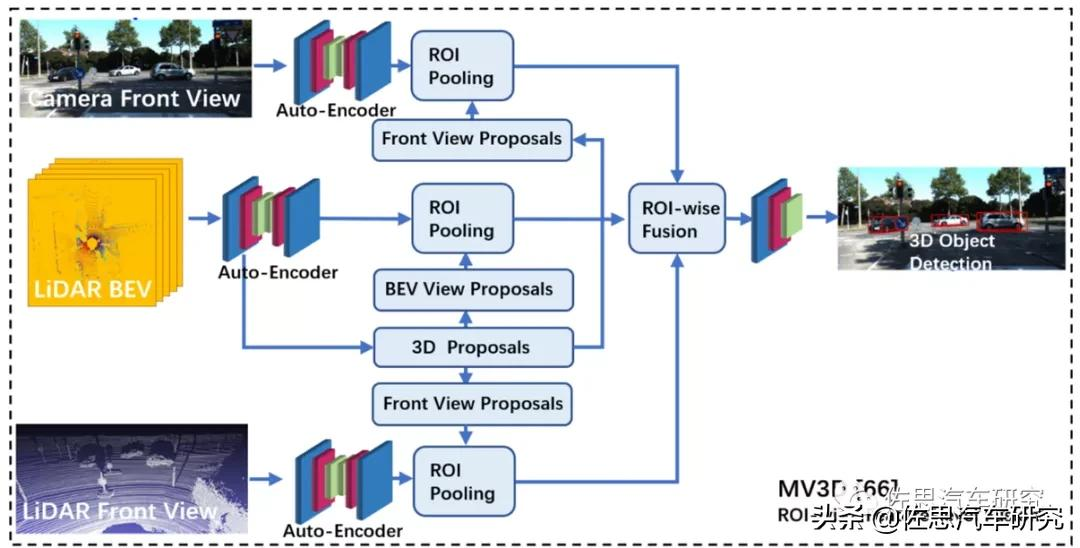
图片来源:互联网
上图是国内常用的自动驾驶传感器融合技术框架
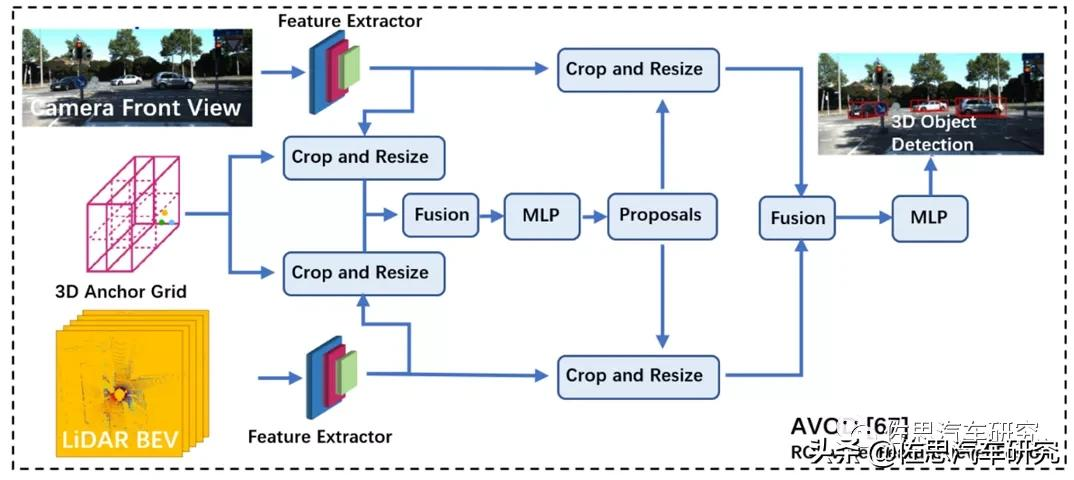
图片来源:互联网
上图是国外常用的自动驾驶传感器融合技术框架
两者都离不开激光雷达鸟瞰图,鸟瞰图避免了透视遮挡,并保留了对象的方向信息和x,y坐标的原始信息。这些方向和x,y坐标信息对于3D对象检测至关重要,且鸟瞰图和其他视角之间的坐标转换较为直接。绝大多数如Waymo或百度阿波罗科技类公司自动驾驶都是这样设计的,这是业内大多数公司的选择,是最成熟的算法,生态系统最完整,但这样意味着少不了车顶的激光雷达,这对汽车造型提出极大挑战,一直无法量产实用化。Waymo之类的厂家在这种算法上投入巨大,以至于无法转移,否则之前数年的研发成果付之东流。
丰田或奔驰则是以双目为核心,首先是立体双目利用视差图加栅格占有法找出可行驶空间。其次是光流预测自车移动轨迹与周边车辆移动轨迹,最后才是用DNN的目标识别与追踪,做语义分割,提高智能程度。激光雷达的作用主要是增强双目的远距离探测目标能力,丰田的激光雷达只有3线。
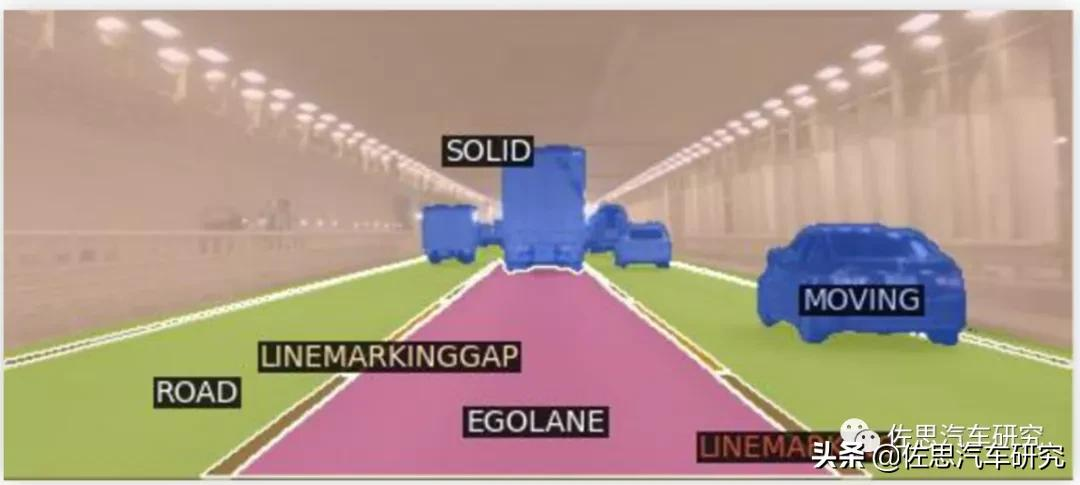
图片来源:互联网
这种方案,成本低,可靠性高,缺点是低速城市环境比较复杂,双目的可行驶空间精度不够,只适合高速路段。需要高线束激光雷达做增强。
华为的思路一开始就介于丰田和Waymo之间,三融合非常近似于第一种MV3D的算法,实际三融合勉强可以看做用立体双目取代鸟瞰激光雷达,同时双目也可以做单目用,单独抽出一路做纯2D图像,最后立体双目点云和激光雷达点云的三融合,也就是上文中的三融合。这样高速与低速环境都能适应,也不使用头顶激光雷达,车辆造型更好处理。缺点是在树木特别密集道路可能会有卡顿。
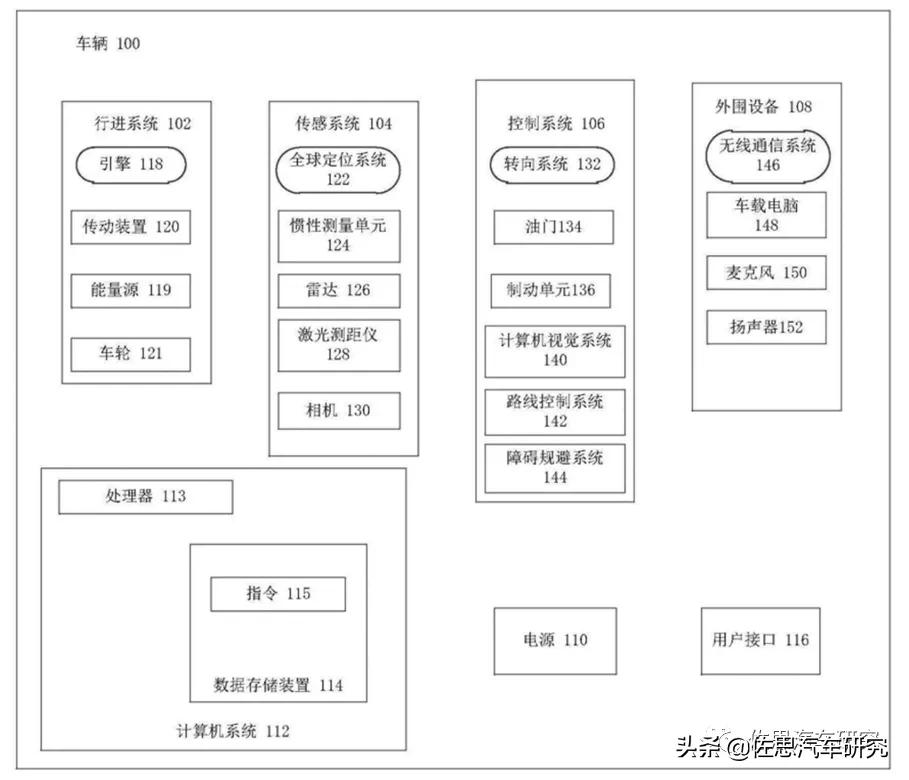
华为专利里的自动驾驶系统,图片来源:互联网
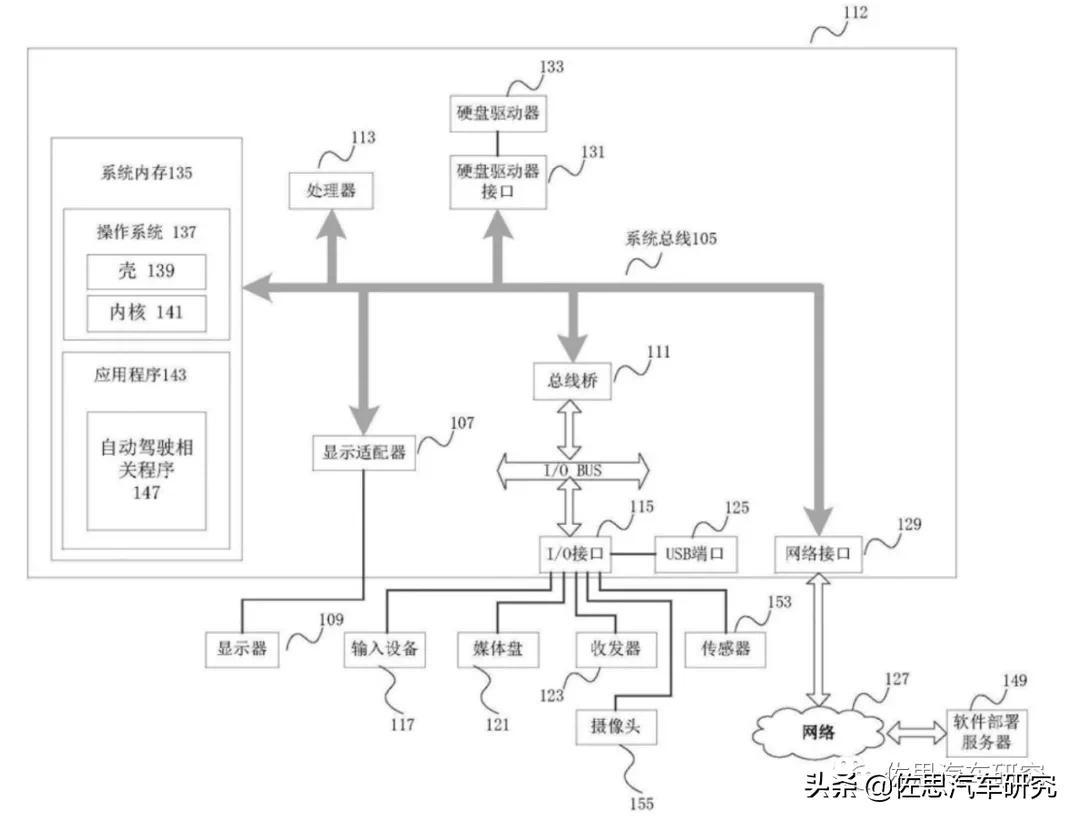
华为自动驾驶接口系统,图片来源:互联网
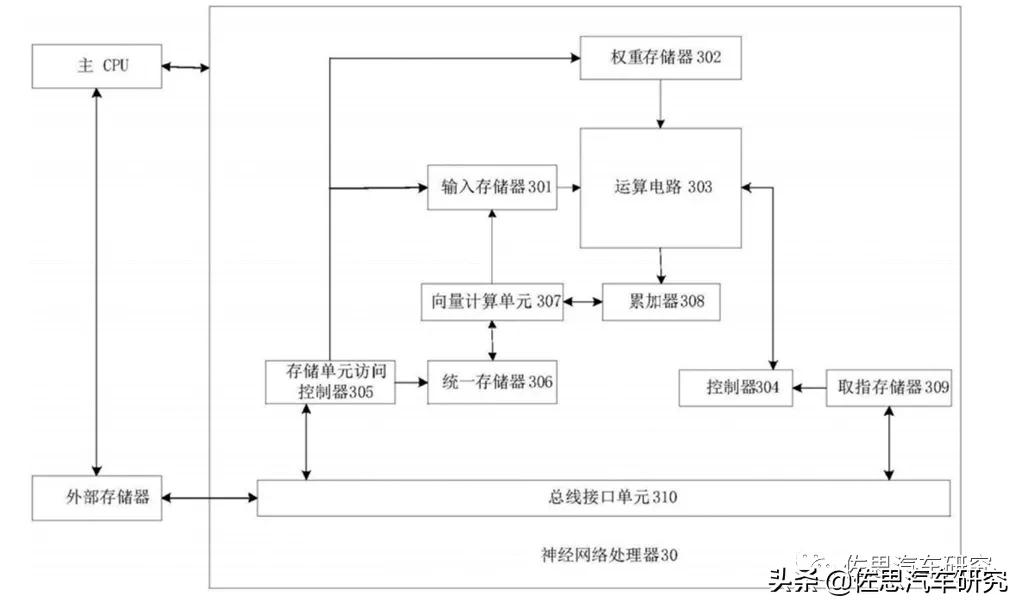
华为自动驾驶运算系统,图片来源:互联网
复杂的三融合可能导致计算系统成本高,功耗高,实时性差,这仅是从专利推断的,估计实用中的华为自动驾驶系统要简化一些。