

作者 | 萝卜
来源 | 早起Python/ target=_blank class=infotextkey>Python(ID: zaoqi-python)
用Python基于主成分分析常见的三个应用场景中,其中有一个是「数据描述」,以描述产品情况为例,比如著名的波士顿矩阵,子公司业务发展状况,区域投资潜力等,需要将多变量压缩到少数几个主成分进行描述,压缩到两个主成分是最理想的,这样便可在一张图内表现出来。
但这类分析一般做主成分分析是不充分的,能够做到因子分析更好。但因子分析的知识点非常庞杂,所以本文将跳过原理,直接通过案例再次「实战PCA分析」,用于主成分分析到因子分析的一个过渡,目标有两个:
能够通过主成分分析结果来估计生成的主成分所表示的含义
借以引出因子分析的优势和学习的必要性是本文的目标
公司希望从事数据分析岗位的你仅用两个短句就概括出以下数据集所反映出的经济现象。

用几个长句都不一定能够很好的描述数据集的价值,更何况高度凝练的两个短句,短短九个指标就已经十分让人头疼了,如果表格再宽一些呢,比如有二三十个变量?
本节我们将使用Python对上面的数据进行分析。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
plt.rc('font', **{'family': 'Microsoft YaHei, SimHei'})
# 设置中文字体的支持
plt.rcParams['axes.unicode_minus'] = False
# 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题
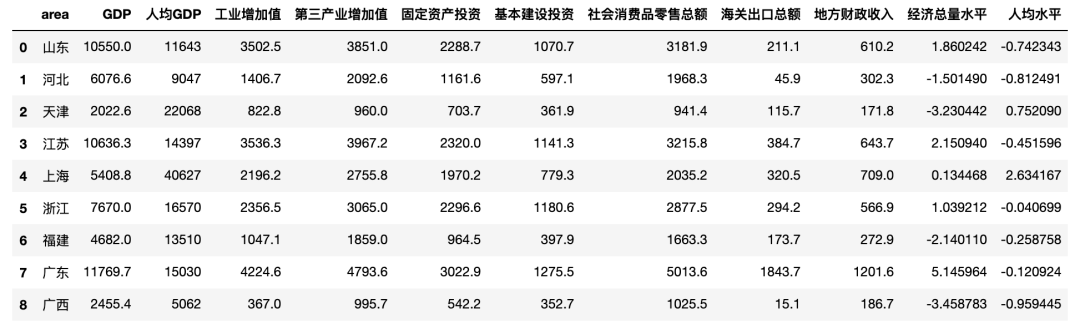
df = pd.read_csv('城市经济.csv')
df
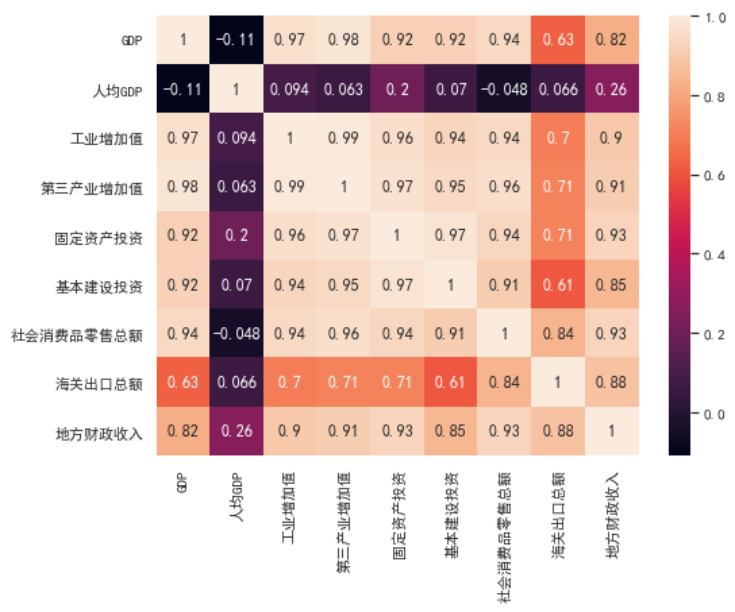
在做主成分分析前,都应该进行变量间相关性的探索,毕竟如果变量是独立的,则不可压缩。
plt.figure(figsize=(8, 6))
sns.heatmap(data=df.corr, annot=True) # annot=True: 显示数字
发现变量间的相关性较高,有变量压缩的必要性
使用中心标准化,即将变量都转化成z分数的形式,避免量纲问题对压缩造成影响
from sklearn.preprocessing import scale
data = df.drop(columns='area') # 丢弃无用的类别变量
data = scale(data)
需要说明的是第一次的n_components参数最好设置得大一些(保留的主成份),观察explained_variance_ratio_取值变化,即每个主成分能够解释原始数据变异的百分比
from sklearn.decomposition import PCA
pca = PCA(n_components=9) # 直接与变量个数相同的主成分
pca.fit(data)
# 累积解释变异程度
plt.plot(np.cumsum(pca.explained_variance_ratio_), linewidth=3)
plt.xlabel('成份数')
plt.ylabel('累积解释方差'); plt.grid(True)
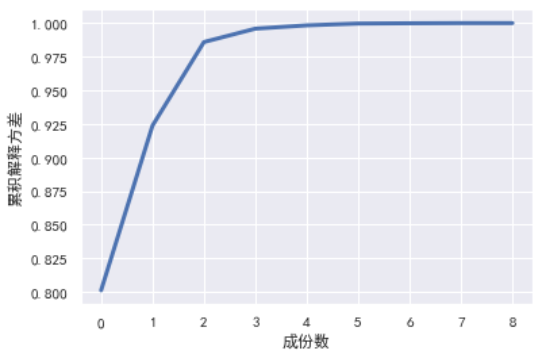
可以看出,当取主成分数为2时,累积解释方差就已经达到0.97有多(0.85 就已经足够),说明我们只需要取两个主成分即可
综上可知两个主成分就已经足够了
pca = PCA(n_components=2) # 直接与变量个数相同的主成分
pca.fit(data)
pca.explained_variance_ratio_
new_data = pca.fit_transform(data) # fit_transform 表示将生成降维后的数据
# 查看规模差别
print("原始数据集规模: ", data.shape)
print("降维后的数据集规模:", new_data.shape)

可以看到9个变量压缩成两个主成分!
先看两个主成分与 9 个变量的系数关系
results = pd.DataFrame(pca.components_).T
results.columns = ['pca_1', 'pca_2']
results.index = df.drop(columns='area').columns
results
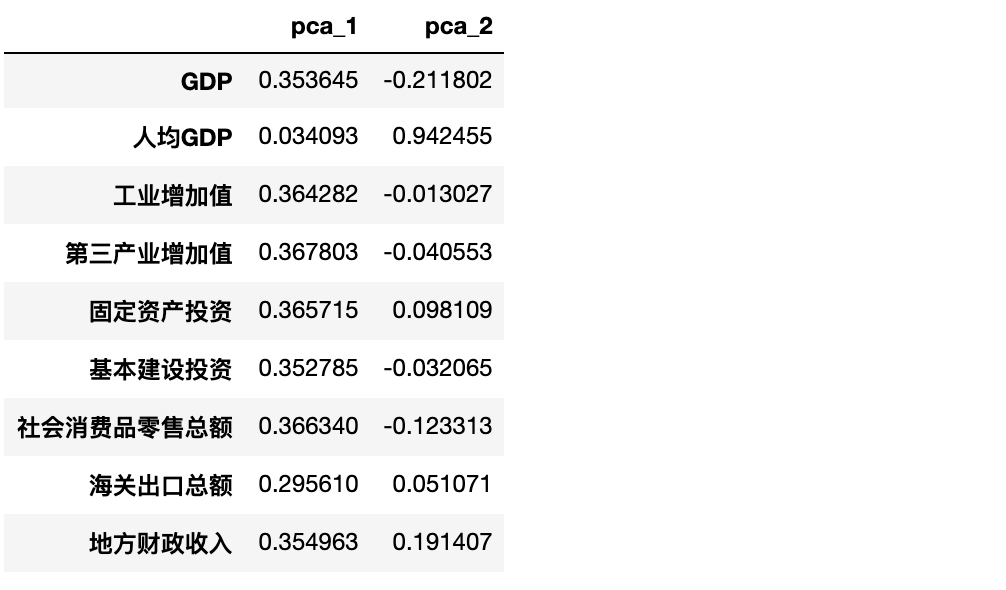
可以明显看出:
主成分1几乎不受data的第二个自变量人均GDP的影响,0.034,其他自变量对其影响程度都差不多。
主成分2受data的第二个自变量人均GDP影响最大,达到了0.94
通过上面的PCA建模,我们把9个自变量压缩成了2 主成分,每个主成分受哪些变量的影响也有了了解。虽然得到的主成分都没有什么意义,但我们是否可以通过变量们对主成分的影响程度来为生成的两个主成分命名呢?
第一个主成分在表达经济总量的指标上的权重相当,可考虑命名为经济总量水平;而第二个主成分只在人均GDP上权重很高,可暂时考虑命名为人均水平
注意:这里的给主成分命名(包括后续有关因子分析的推文)都是对降维后的数据进行的,而不是生成的主成分,这样才有比较和描述的价值。每个自变量在生成的主成分上的权重只是给这个主成分的命名提供参考,真正的命名操作是对压缩后的数据进行。
new_data = pca.fit_transform(data) # fit_transform 表示将生成降维后的数据
results = df.join(pd.DataFrame(new_data, # new_data 是降维后的数据
columns=['经济总量水平', '人均水平'])) # 与原来的数据拼接
results
绘制波士顿矩阵,这里的散点图的点标注代码是前人的优秀轮子,直接拿来用即可。
plt.figure(figsize=(10, 8))
# 基础散点图
x, y = results['经济总量水平'], results['人均水平']
label = results['area']
plt.scatter(x, y)
plt.xlabel('经济总量水平'); plt.ylabel('人均水平')
# 对散点图中的每一个点进行文字标注
## 固定代码,无需深究,拿来即用
## 给点标注是需要将 x 和 y 以及标签如上段代码那样单独拆开
for a,b,l in zip(x,y,label):
plt.text(a, b+0.1, '%s.' % l, ha='center', va='bottom', fontsize=14)
# 添加两条竖线
plt.vlines(x=results['经济总量水平'].mean,
ymin=-1.5, ymax=3, colors='red')
plt.hlines(y=results['人均水平'].mean,
xmin=-4, xmax=6, colors='red')
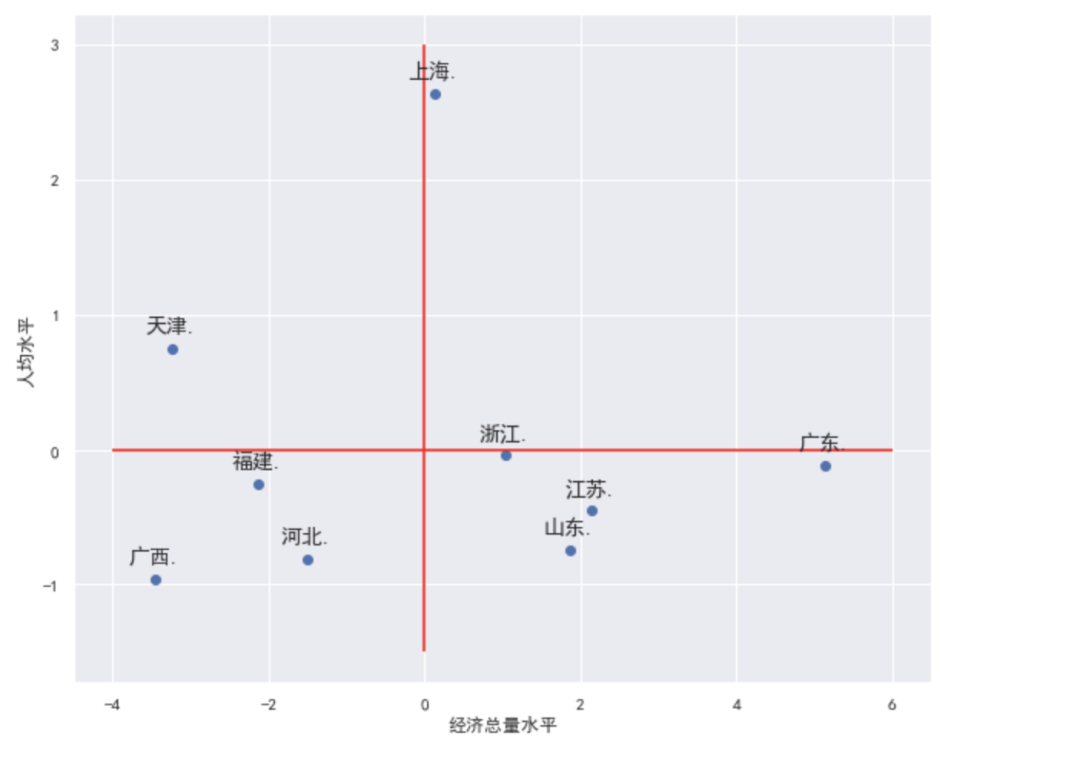
最终从上图可以看出:
广西,河北,福建三地的人均水平和经济总量水平都偏低
上海的人均经济水平很高,但经济总量水平缺只是略优于均值
广东的人均经济水平稍次于均值,但经济总量水平很高
......
本文讲解了基于主成分分析的样本特征描述,并使用Python示范了完整的流程。其中,也对由多个自变量生成的主成分的命名描述操作中需要注意的点作了比较详细的说明。其实PCA并不能非常好的满足维度分析的需求,能够做到「因子分析」最好,它是主成分方法的拓展,作为维度分析的手段,因子分析也是构造合理的聚类模型和稳健的分类模型的必然步骤。
Python商业数据挖掘自动化系列代码及数据已经上传GitHub,如有需要可以自行下载:「https://github.com/liuhuanshuo/zaoqi-Python/tree/master/商业数据分析实战」。






