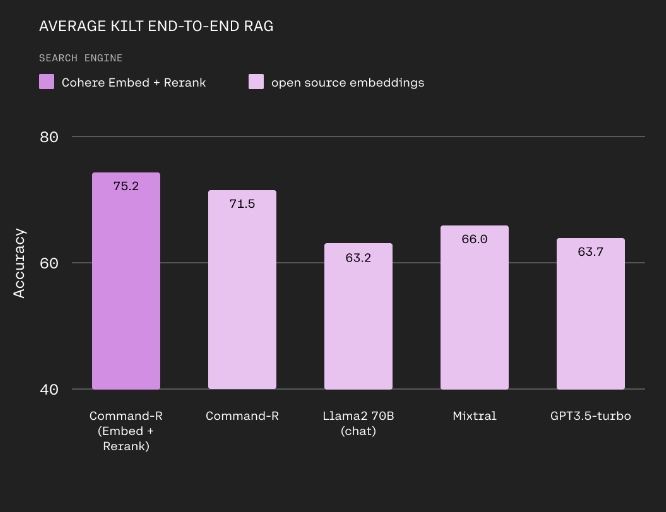
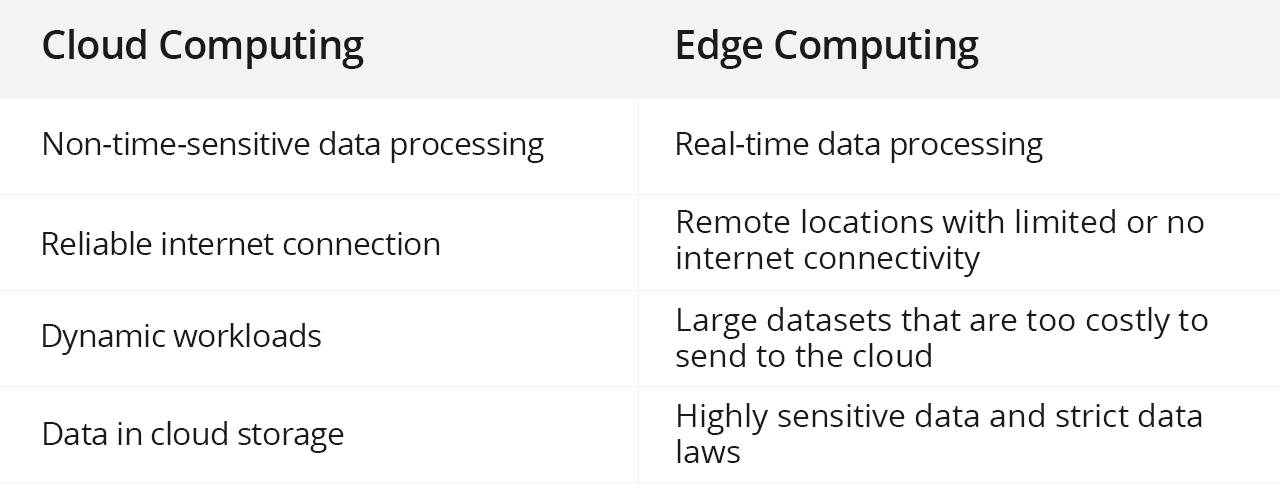
Transformer是一种基于注意力机制的深度神经网络结构,近年来在自然语言处理领域广受欢迎。相较于传统的RNN、LSTM等序列模型,Transformer具有卓越的建模能力和可扩展性。本文将从通用的建模能力、与卷积形成互补的优势、更强的建模能力、对大模型和大数据的可扩展性、更好地连接视觉和语言几方面探讨Transformer建模的优点。
首先,Transformer拥有通用的建模能力,能够处理不同长度的输入序列和输出序列。传统的RNN和LSTM一次只能处理一个输入和一个输出,而Transformer一次可以同时处理多个输入和多个输出。这使得Transformer具有更高的并行性和计算效率,能够处理更长、更复杂的序列数据。
其次,Transformer与卷积形成互补,具有更强的建模能力。卷积神经网络(CNN)主要用于图像处理,利用滤波器来提取不同方向和大小的特征。而Transformer则主要用于自然语言处理,利用注意力机制来学习词之间的关系。这两种模型结构形成互补,能够应对不同类型的数据。例如,在图像描述生成任务中,可以将CNN提取的图像特征和Transformer学习到的语言特征结合起来,实现视觉和语言的连接。
此外,Transformer具有更强的建模能力。相较于传统的RNN和LSTM,Transformer能够处理更长的序列数据,并且不会出现梯度消失等问题。同时,Transformer在训练时采用了层次化的注意力机制,在处理长序列时能够将注意力集中在与当前位置相关的词上,从而提高建模效果。
另外,Transformer对大模型和大数据的可扩展性也很强。在自然语言处理领域,需要处理的数据量往往非常庞大,例如GPT-3模型就包含了1750亿个参数。传统的RNN和LSTM处理大数据时需要进行切分或者采样,而Transformer可以通过并行计算来提高训练速度。同时,Transformer还支持分布式训练,可以通过多台机器来加速训练过程。
最后,Transformer能够更好地连接视觉和语言。在计算机视觉领域,Transformer被广泛应用于图像描述生成、图像问答等任务中。通过将图像特征和文本特征结合起来,可以生成自然语言描述。这不仅提高了计算机视觉的应用价值,也丰富了自然语言处理的应用场景。
总之,Transformer作为一种新兴的深度神经网络结构,在自然语言处理和计算机视觉等领域具有广泛的应用前景。其通用的建模能力、与卷积形成互补的优势、更强的建模能力、对大模型和大数据的可扩展性以及更好地连接视觉和语言的特点,使得Transformer成为当前最为流行的深度学习模型之一。