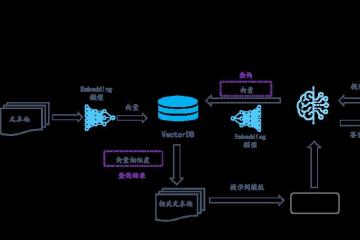
今年AI大模型应用呈井喷式发展,其中,LangChain、Haystack等端到端大语言模型应用框架更是将向量数据库推出了新热点。
向量数据库(vector database,也有人称矢量数据库),简单地说,它们是以向量格式管理、存储和检索数据的数据库。

因为它在处理高维数据方面具有先天优势,从图像处理到推荐系统,向量数据库无疑是幕后的英雄。它的主要功能包括:
因此,我们说向量数据库让AI有了记忆,这个记忆不仅仅是记录存储、也包括检索和管理。就像人类的记忆一样,我们通过同学的毕业照总是能够认得这个人是谁;我们在和朋友聊天的时候也常常会一起回忆过去。
向量数据库的核心是通过使用数学模型来管理向量数据。
那么什么又是向量?简单地说,向量是一个既有方向又有大小的数字对象。在向量数据库中,向量可以用于表示复杂的数据,例如:图像、文本。
每个数据片段都被转换成高维空间中的向量管理起来。当我们需要查找相似的数据片段时,数据库不需要遍历筛选选每个条目。而是通过计算向量之间的距离来匹配,向量越接近,数据就越相似。这种方式非常高效,通过这种方式检索数据可以比传统关系型数据库更快地处理大批量数据。
下面是个文本向量存储的示例图:

下面是图片向量化存储与检索的示例图:

大家都知道,通用大模型的运行涉及巨大的计算资源,因此许多大模型都基于MaaS,私有化成本很高。与之相矛盾的是在具体行业大模型应用中往往对数据安全要求高,并且需要与相关业务或领域知识深入融合,才能做到安全、专业。LangChain等大模型应用框架为行业大模型应用提供了一个经典解决方案,而开源的向量数据库又为LangChain等大模型应用解决方案提供了基础支撑,其实向量数据库在许多应用场景(如:企业知识库、推荐系统、档案管理等)也非常有用。因此,向量数据库也成为大模型应用发展的一个热门技术。

开源社区对向量数据库的发展功不可没,许多开源向量数据库项目在性能、灵活性和鲁棒性方面表现都非常优秀,下面列举8个目前最佳的开源向量数据库项目,这些开业项目应该能够为你的AI解决方案提供最佳技术选型。

https://Github.com/milvus-io/milvus

Milvus是由Zilliz提供的一个高度可定制的开源向量数据库,旨在为嵌入式相似性搜索等AI应用提供支持。目前Milvus已经发布了 2.0 ,Milvus 2.0是一个云原生向量数据库,设计上采用存储、计算分离。Milvus2.0中的所有组件都支持无状态,这样做就使得整个的应用更加灵活而有弹性。
Milvus建立在Faiss、Annoy、HNSW等主流向量搜索库之上,旨在对包含数百万、数十亿甚至数万亿个向量的密集向量数据集进行相似性搜索。
Milvus还支持数据分片、数据持久化、流数据摄取、向量和标量数据之间的混合搜索以及许多其他高级功能。建议使用Kube.NETes部署Milvus,以获得最佳可用性和弹性。
Milvus采用共享存储架构,存储、计算分离,具备计算节点的水平可扩展性。遵循数据平面和控制平面分解原则,Milvus包括四层:接入层、协调服务、工作节点和存储。在扩展或灾难恢复方面,这些层可以做到相互独立。
下面是Milvus的架构图。

Milvus的主要特性包括:
更多内容可以参考官网:https://milvus.io
Demo:https://milvus.io/milvus-demos/
文档: https://milvus.io/docs
https://github.com/facebookresearch/faiss

Faiss由Facebook的AI Research团队开发的向量数据库,在高维矢量搜索方面表现出色。是一个搜索效率非常突出的向量库,这也使其成为一些实时性要求高的应用程序的绝佳选择。Faiss是一个高效的相似性搜索和密集向量聚类库。它包含的算法可以搜索任何大小的向量集,甚至多达超过RAM的向量大小。它还包含用于评估和参数调整的支持代码。Faiss是用C++编写的,带有Python/ target=_blank class=infotextkey>Python/numpy的完整包装,一些常用的算法是在GPU上实现的。
Faiss是通过存储一组向量的索引,并提供了一个函数在它们当中进行比较,从而实现搜索。
目前Faiss在GitHub上的Star已经超过24K。
基于CPU、GPU的python安装方法如下:
$ conda install -c pytorch faiss-cpu$ conda install -c pytorch faiss-gpu以上只能安装一个,不能同时安装两个,因为后者是前者的超集。

https://github.com/spotify/annoy

Annoy (Approximate Nearest Neighbors Oh Yeah)是由Spotify创建的一个轻量级且功能强大的向量数据库。它专为快速搜索大型数据集而设计,非常适合需要快速响应的应用。它是一个C++库,但支持在Python中使用。
它通过创建大型的只读文件数据结构,并将这些数据结构映射到内存中,以便许多进程可以共享相同的数据。
ANNOY的核心是一种基于随机投影和树的算法。它由Erik Bernhardsson于2015年在Spotify工作时开发。ANNOY设计目标是实现在100到1000个密集维度的数据集中进行搜索。为了计算最近的邻居,它将点集分成两半,并递归地进行,直到每个集合都有k个项目。通常k应该在100左右(见下图)。

关于Annoy的主要特征官方介绍如下:
python语言下的安装annoy:
pip install annoypython语言下的使用annoy:
from annoy import AnnoyIndex
import random
f = 40 # Length of item vector that will be indexed
t = AnnoyIndex(f, 'angular')
for i in range(1000):
v = [random.gauss(0, 1) for z in range(f)]
t.add_item(i, v)
t.build(10) # 10 trees
t.save('test.ann')
# ...
u = AnnoyIndex(f, 'angular')
u.load('test.ann') # super fast, will just mmap the file
print(u.get_nns_by_item(0, 1000)) # will find the 1000 nearest neighbors
https://github.com/nmslib/nmslib

Nmslib (Non-Metric Space Library)是一个于非度量空间的开源向量数据库。是一个高效的跨平台相似性搜索库,也是一个评估相似性搜索方法的工具包,并且它的核心库没有任何第三方依赖项。
该项目的目标是创建一个用于能够在通用以及非度量空间中进行搜索的全面工具包,包括:通用搜索方法、近似搜索方法、各种度量空间访问方法以及非度量空间的方法。
Nmslib是一个可扩展的库,可以添加新的搜索方法和距离函数。支持在C++和Python、JAVA中使用,例如:可以使用Java等语言构建一个查询服务器。
https://github.com/qdrant/qdrant

Qdrant是一个包含向量数据库和向量相似度搜索引擎的开源项目。它提供了一组便捷的API来执行存储、搜索和管理向量数据,并且能够同时存储payload数据,这就有利于自定义的数据过滤,这个方面在各种神经网络、基于语义的匹配、分面搜索、精准推荐等应用程序非常有用。
Qdrant是用Rust语言开发的,因此它能在高负载下也具备高效、可靠特性。Qdrant的使用非常简单:
(1)使用Docker启动
docker run -p 6333:6333 qdrant/qdrant
br(2)在python中使用
安装:
pip install qdrant-client连接:
from qdrant_client import QdrantClient
qdrant = QdrantClient("http://localhost:6333") # Connect to existing Qdrant instance, for productionqdrant的特点如下:
https://github.com/chroma-core/chroma

Chroma是一个开源嵌入式向量数据库。基于Chroma可以轻松构建LLM应用程序。Chroma的设计非常简单、易用、灵活,可以满足各种场景下的应用。它支持使用第三方的embedding模型执行查询和元数据过滤。
下面是Chroma与OpenAI embedding搭配使用的架构示意图:

基于Docker的Chromadb可以参考:
在具体应用开发上,Python下使用Chroma也非常简单。
安装:
pip install chromadb四个核心API的使用:
import chromadb
# setup Chroma in-memory, for easy prototyping. Can add persistence easily!
client = chromadb.Client()
# Create collection. get_collection, get_or_create_collection, delete_collection also available!
collection = client.create_collection("all-my-documents")
# Add docs to the collection. Can also update and delete. Row-based API coming soon!
collection.add(
documents=["This is document1", "This is document2"], # we handle tokenization, embedding, and indexing automatically. You can skip that and add your own embeddings as well
metadatas=[{"source": "notion"}, {"source": "google-docs"}], # filter on these!
ids=["doc1", "doc2"], # unique for each doc
)
# Query/search 2 most similar results. You can also .get by id
results = collection.query(
query_texts=["This is a query document"],
n_results=2,
# where={"metadata_field": "is_equal_to_this"}, # optional filter
# where_document={"$contains":"search_string"} # optional filter
)Chroma的主要特点包括:
https://github.com/lancedb/lancedb

LanceDB是一个开源的支持持久存储的向量搜索数据库,这个开源项目可以大大简化embeddings的检索、过滤和管理。
LanceDB的内核是用Rust开发的,并使用Lance构建(Lance是一种为高性能ML工作负载设计的开源列格式)。Python和JavaScript等语言可以使用API操作LanceDB。
Python的使用方式如下:
安装:
pip install lancedb
检索:
import lancedb
uri = "data/sample-lancedb"
db = lancedb.connect(uri)
table = db.create_table("my_table",
data=[{"vector": [3.1, 4.1], "item": "foo", "price": 10.0},
{"vector": [5.9, 26.5], "item": "bar", "price": 20.0}])
result = table.search([100, 100]).limit(2).to_df()LanceDB的主要功能特点如下:
https://github.com/Stevenic/vectra

Vectra是一个Node.js的本地向量数据库,其功能类似于Pinecone或Qdrant,但区别是Vectra使用本地文件构建。每个Vectra索引都对应磁盘上的一个文件夹。文件夹中包含一个index.json文件,文件内容包含索引的所有向量以及这些索引的元数据。创建索引时,可以指定索引的元数据属性,只有这些字段才会存储在index.json文件中。而项目的其他元数据将会被保存到一个有GUID指定的文件中。
运行时,整个Vectra索引都被加载到内存中,因此它的检索效率非常高,甚至是实时的,但是它不适合用于类似需要保留长上下文的聊天机器人场景。Vectra更适合用于一些小的语料库、静态数据或者一些问答文档的检索等应用场景。
在Node.js中的使用如下:
安装:
$ npm install vectra创建实例:
if (!await index.isIndexCreated()) {
await index.createIndex();
}创建索引:
import { LocalIndex } from 'vectra';
const index = new LocalIndex(path.join(__dirname, '..', 'index'));添加数据到索引:
import { OpenAIApi, Configuration } from 'openai';
const configuration = new Configuration({
apiKey: `<YOUR_KEY>`,
});
const api = new OpenAIApi(configuration);
async function getVector(text: string) {
const response = await api.createEmbedding({
'model': 'text-embedding-ada-002',
'input': text,
});
return response.data.data[0].embedding;
}
async function addItem(text: string) {
await index.insertItem({
vector: await getVector(text),
metadata: { text }
});
}
// Add items
await addItem('apple');
await addItem('oranges');
await addItem('red');
await addItem('blue');检索数据:
async function query(text: string) {
const vector = await getVector(input);
const results = await index.queryItems(vector, 3);
if (results.length > 0) {
for (const result of results) {
console.log(`[${result.score}] ${result.item.metadata.text}`);
}
} else {
console.log(`No results found.`);
}
}
await query('green');
/*
[0.9036569942401076] blue
[0.8758153664568566] red
[0.8323828606103998] apple
*/
await query('banana');
/*
[0.9033128691220631] apple
[0.8493374123092652] oranges
[0.8415324469533297] blue
*/
以上这些开源向量数据库每一个都有自己独特的一面。选择使用哪一款取决于项目的具体需求。如果您正在处理一个需要高速数据检索的项目,那么Annoy可能是最合适的。但如果项目涉及非度量空间,那么Nmslib可能才是首选的。一个合适的向量数据库可以成为AI解决方案当中的记忆海绵体,让AI不仅能推理还能记忆、检索,提升AI应用的效果。