在 上篇文章 用了整篇的内容来描述网络数据包在 Kube.NETes 网络中的轨迹,文章末尾,我们提出了一种假设:同一个内核空间中的两个 socket 可以直接传输数据,是不是就可以省掉内核网络协议栈处理带来的延迟?
不论是同 pod 中的两个不同容器,或者同节点的两个 pod 间的网络通信,实际上都发生在同一个内核空间中,互为对端的两个 socket 也都位于同一个内存中。而在上篇文章的开头也总结了数据包的传输轨迹实际上是 socket 的寻址过程,可以进一步将问题展开:同一节点上的两个 socket 间的通信,如果可以 快速定位到对端的 socket -- 找到其在内存中的地址,我们就可以省掉网络协议栈处理带来的延迟。

互为对端的两个 socket 也就是建立起连接的客户端 socket 和服务端 socket,他们可以通过 IP 地址和端口进行关联。客户端 socket 的本地地址和端口,是服务端 socket 的远端地址和端口;客户端 socket 的远端地址和端口,则是服务端 socket 的本地地址和端口。
当客户端和服务端的完成连接的建立之后,如果可以使用本地地址 + 端口和远端地址 + 端口端口的组合 指向socket 的话,仅需调换本地和远端的地址 + 端口,即可定位到对端的 socket,然后将数据直接写到对端 socket(实际是写入 socket 的接收队列 RXQ,这里不做展开),就可以避开内核网络栈(包括 netfilter/iptables)以及 NIC 的处理。
如何实现?看标题应该也猜出来了,这里借助 eBPF 技术。
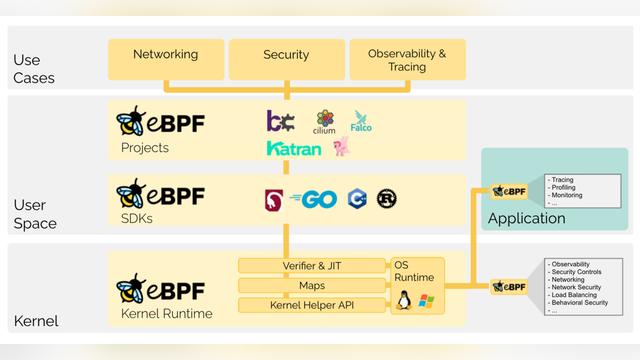
linux 内核一直是实现监控/可观测性、网络和安全功能的理想地方。不过很多情况下这并非易事,因为这些工作需要修改内核源码或加载内核模块, 最终实现形式是在已有的层层抽象之上叠加新的抽象。eBPF 是一项革命性技术,它能在内核中运行沙箱程序(sandbox programs), 而无需修改内核源码或者加载内核模块。
将 Linux 内核变成可编程之后,就能基于现有的(而非增加新的)抽象层来打造更加智能、 功能更加丰富的基础设施软件,而不会增加系统的复杂度,也不会牺牲执行效率和安全性。
下面截取了 eBPF.io[1] 网站的介绍。
在 网络 方面,在不离开内核空间的情况下使用 eBPF 可以加快数据包处理速度。添加额外的协议解析器并轻松编写任何转发逻辑以满足不断变化的需求。
在 可观测性 方面,使用 eBPF 可以自定义指标的收集和内核聚合,以及从众多来源生成可见性事件和数据结构,而无需导出样本。
在 链路跟踪与分析 方面,将 eBPF 程序附加到跟踪点以及内核和用户应用程序探测点,可以提供强大的检查能力和独特的洞察力来解决系统性能问题。
在 安全 方面,将查看和理解所有系统调用与所有网络的数据包和套接字级别视图相结合,来创建在更多上下文中运行并具有更好控制级别的安全系统。
eBPF 程序是事件驱动的,当内核或应用程序通过某个 hook(钩子) 点时运行。预定义的钩子类型包括系统调用、函数进入/退出、内核跟踪点、网络事件等。

Linux 的内核在系统调用和网络栈上提供了一组 BPF 钩子,通过这些钩子可以触发 BPF 程序的执行,下面就介绍常见的几种钩子。
上面两种属于网络事件类型的钩子,下面介绍同样是网络相关的,套接字的系统调用。
eBPF 程序的一个重要方面是共享收集的信息和存储状态的能力。为此,eBPF 程序可以利用 eBPF Map 的概念存储和检索数据。eBPF Map 可以从 eBPF 程序访问,也可以通过系统调用从用户空间中的应用程序访问。

Map 有多种类型:哈希表、数组、LRU(最近最少使用)哈希表、环形缓冲区、堆栈调用跟踪等等。
比如上面附加到 socket 套接字上用来在每次发送消息时执行的程序,实际上是附加在 socket 哈希表上,socket 就是键值对中的值。
eBPF 程序不能调用任意内核函数。如果这样做会将 eBPF 程序绑定到特定的内核版本,并会使程序的兼容性复杂化。相反,eBPF 程序可以对辅助函数进行函数调用,辅助函数是内核提供的众所周知且稳定的 API。
这些 辅助函数[4] 提供了不同的功能:

讲完 eBPF 的内容,对实现应该会有一个大概的思路了。这里我们需要两个 eBPF 程序分别维护 socket map 和将消息直通对端的 socket。这里感谢 Idan Zach 的示例代码 ebpf-sockops[5],我将代码做了 简单的修改[6],让可读性更好一点。
原来代码用使用了 16777343 表示地址 127.0.0.1,4135 表示端口 10000,二者是网络 字节序列转换后的值。
附加到 sock_ops 的程序:监控 socket 状态,当状态为 BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB 或者 BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB 时,使用辅助函数 bpf_sock_hash_update[^1] 将 socket 作为 value 保存到 socket map 中,key
__section("sockops")
int bpf_sockmap(struct bpf_sock_ops *skops)
{
__u32 family, op;
family = skops->family;
op = skops->op;
//printk("<<< op %d, port = %d --> %dn", op, skops->local_port, skops->remote_port);
switch (op) {
case BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB:
case BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB:
if (family == AF_INET6)
bpf_sock_ops_ipv6(skops);
else if (family == AF_INET)
bpf_sock_ops_ipv4(skops);
break;
default:
break;
}
return 0;
}
// 127.0.0.1
static const __u32 lo_ip = 127 + (1 << 24);
static inline void bpf_sock_ops_ipv4(struct bpf_sock_ops *skops)
{
struct sock_key key = {};
sk_extract4_key(skops, &key);
if (key.dip4 == loopback_ip || key.sip4 == loopback_ip ) {
if (key.dport == bpf_htons(SERVER_PORT) || key.sport == bpf_htons(SERVER_PORT)) {
int ret = sock_hash_update(skops, &sock_ops_map, &key, BPF_NOEXIST);
printk("<<< ipv4 op = %d, port %d --> %dn", skops->op, key.sport, key.dport);
if (ret != 0)
printk("*** FAILED %d ***n", ret);
}
}
}附加到 socket map 的程序:在每次发送消息时触发该程序,使用当前 socket 的远端地址 + 端口和本地地址 + 端口作为 key 从 map 中定位对端的 socket。如果定位成功,说明客户端和服务端位于同一节点上,使用辅助函数 bpf_msg_redirect_hash[^2] 将数据直接写入到对端 socket。
这里没有直接使用 bpf_msg_redirect_hash,而是通过自定义的 msg_redirect_hash 来访问。因为前者无法直接访问,否则校验会不通过。
__section("sk_msg")
int bpf_redir(struct sk_msg_md *msg)
{
__u64 flags = BPF_F_INGRESS;
struct sock_key key = {};
sk_msg_extract4_key(msg, &key);
// See whether the source or destination IP is local host
if (key.dip4 == loopback_ip || key.sip4 == loopback_ip ) {
// See whether the source or destination port is 10000
if (key.dport == bpf_htons(SERVER_PORT) || key.sport == bpf_htons(SERVER_PORT)) {
//int len1 = (__u64)msg->data_end - (__u64)msg->data;
//printk("<<< redir_proxy port %d --> %d (%d)n", key.sport, key.dport, len1);
msg_redirect_hash(msg, &sock_ops_map, &key, flags);
}
}
return SK_PASS;
}环境
安装依赖。
sudo apt update && sudo apt install make clang llvm gcc-multilib linux-tools-$(uname -r) linux-cloud-tools-$(uname -r) linux-tools-generic克隆代码。
git clone https://Github.com/addozhang/ebpf-sockops
cd ebpf-sockops编译并加载 BPF 程序。
sudo ./load.sh安装 iperf3。
sudo apt install iperf3启动 iperf3 服务端。
iperf3 -s -p 10000运行 iperf3 客户端。
iperf3 -c 127.0.0.1 -t 10 -l 64k -p 10000运行 trace.sh 脚本查看打印的日志,可以看到 4 条日志:创建了 2 个连接。
./trace.sh
iperf3-7744 [001] d...1 838.985683: bpf_trace_printk: <<< ipv4 op = 4, port 45189 --> 4135
iperf3-7744 [001] d.s11 838.985733: bpf_trace_printk: <<< ipv4 op = 5, port 4135 --> 45189
iperf3-7744 [001] d...1 838.986033: bpf_trace_printk: <<< ipv4 op = 4, port 45701 --> 4135
iperf3-7744 [001] d.s11 838.986078: bpf_trace_printk: <<< ipv4 op = 5, port 4135 --> 45701如何确定跳过了内核网络栈了,使用 tcpdump 抓包看一下。从抓包的结果来看,只有握手和挥手的流量,后续消息的发送完全跳过了内核网络栈。
sudo tcpdump -i lo port 10000 -vvv
tcpdump: listening on lo, link-type EN10MB (Ethernet), capture size 262144 bytes
13:23:31.761317 IP (tos 0x0, ttl 64, id 50214, offset 0, flags [DF], proto TCP (6), length 60)
localhost.34224 > localhost.webmin: Flags [S], cksum 0xfe30 (incorrect -> 0x5ca1), seq 2753408235, win 65495, options [mss 65495,sackOK,TS val 166914980 ecr 0,nop,wscale 7], length 0
13:23:31.761333 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 60)
localhost.webmin > localhost.34224: Flags [S.], cksum 0xfe30 (incorrect -> 0x169a), seq 3960628312, ack 2753408236, win 65483, options [mss 65495,sackOK,TS val 166914980 ecr 166914980,nop,wscale 7], length 0
13:23:31.761385 IP (tos 0x0, ttl 64, id 50215, offset 0, flags [DF], proto TCP (6), length 52)
localhost.34224 > localhost.webmin: Flags [.], cksum 0xfe28 (incorrect -> 0x3d56), seq 1, ack 1, win 512, options [nop,nop,TS val 166914980 ecr 166914980], length 0
13:23:31.761678 IP (tos 0x0, ttl 64, id 59057, offset 0, flags [DF], proto TCP (6), length 60)
localhost.34226 > localhost.webmin: Flags [S], cksum 0xfe30 (incorrect -> 0x4eb8), seq 3068504073, win 65495, options [mss 65495,sackOK,TS val 166914981 ecr 0,nop,wscale 7], length 0
13:23:31.761689 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 60)
localhost.webmin > localhost.34226: Flags [S.], cksum 0xfe30 (incorrect -> 0x195d), seq 874449823, ack 3068504074, win 65483, options [mss 65495,sackOK,TS val 166914981 ecr 166914981,nop,wscale 7], length 0
13:23:31.761734 IP (tos 0x0, ttl 64, id 59058, offset 0, flags [DF], proto TCP (6), length 52)
localhost.34226 > localhost.webmin: Flags [.], cksum 0xfe28 (incorrect -> 0x4019), seq 1, ack 1, win 512, options [nop,nop,TS val 166914981 ecr 166914981], length 0
13:23:41.762819 IP (tos 0x0, ttl 64, id 43056, offset 0, flags [DF], proto TCP (6), length 52) localhost.webmin > localhost.34226: Flags [F.], cksum 0xfe28 (incorrect -> 0x1907), seq 1, ack 1, win 512, options [nop,nop,TS val 166924982 ecr 166914981], length 0
13:23:41.763334 IP (tos 0x0, ttl 64, id 59059, offset 0, flags [DF], proto TCP (6), length 52)
localhost.34226 > localhost.webmin: Flags [F.], cksum 0xfe28 (incorrect -> 0xf1f4), seq 1, ack 2, win 512, options [nop,nop,TS val 166924982 ecr 166924982], length 0
13:23:41.763348 IP (tos 0x0, ttl 64, id 43057, offset 0, flags [DF], proto TCP (6), length 52)
localhost.webmin > localhost.34226: Flags [.], cksum 0xfe28 (incorrect -> 0xf1f4), seq 2, ack 2, win 512, options [nop,nop,TS val 166924982 ecr 166924982], length 0
13:23:41.763588 IP (tos 0x0, ttl 64, id 50216, offset 0, flags [DF], proto TCP (6), length 52)
localhost.34224 > localhost.webmin: Flags [F.], cksum 0xfe28 (incorrect -> 0x1643), seq 1, ack 1, win 512, options [nop,nop,TS val 166924982 ecr 166914980], length 0
13:23:41.763940 IP (tos 0x0, ttl 64, id 14090, offset 0, flags [DF], proto TCP (6), length 52)
localhost.webmin > localhost.34224: Flags [F.], cksum 0xfe28 (incorrect -> 0xef2e), seq 1, ack 2, win 512, options [nop,nop,TS val 166924983 ecr 166924982], length 0
13:23:41.763952 IP (tos 0x0, ttl 64, id 50217, offset 0, flags [DF], proto TCP (6), length 52)
localhost.34224 > localhost.webmin: Flags [.], cksum 0xfe28 (incorrect -> 0xef2d), seq 2, ack 2, win 512, options [nop,nop,TS val 166924983 ecr 166924983], length 0通过 eBPF 的引入,我们缩短了同节点通信数据包的 datapath,跳过了内核网络栈直接连接两个对端的 socket。
这种设计适用于同 pod 两个应用的通信以及同节点上两个 pod 的通信。
[^1]: 该辅助函数将引用的 socket 添加或者更新到 sockethash map 中,程序的输入 bpf_sock_ops 作为键值对的值。详细信息可参考 https://man7.org/linux/man-pages/man7/bpf-helpers.7.html 中的 bpf_sock_hash_update。
[^2]: 该辅助函数将 msg 转发到 socket map 中 key
[1] eBPF.io: https://ebpf.io
[2] sk_buff: https://atbug.com/tracing-network-packets-in-kubernetes/#sk_buff
[3] bpf_sock_ops: https://elixir.bootlin.com/linux/latest/source/include/uapi/linux/bpf.h#L6377
[4] 辅助函数: https://man7.org/linux/man-pages/man7/bpf-helpers.7.html
[5] Idan Zach 的示例代码 ebpf-sockops: https://github.com/zachidan/ebpf-sockops
[6] 简单的修改: https://github.com/zachidan/ebpf-sockops/pull/3/commits/be09ac4fffa64f4a74afa630ba608fd09c10fe2a