智东西
编译 | 程茜
编辑 | 心缘
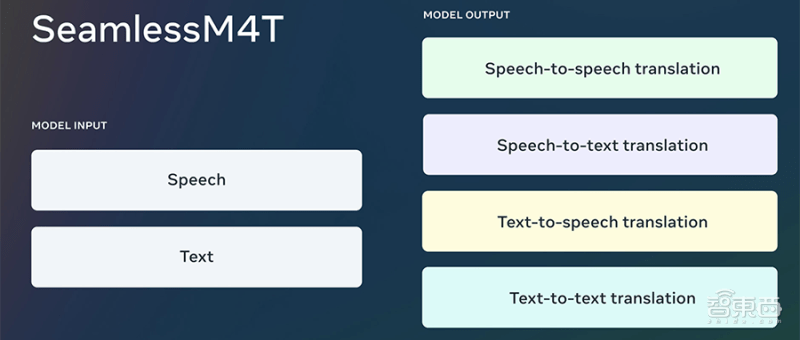
智东西8月23日报道,昨晚,Meta官宣AI大模型SeamlessM4T,该模型可翻译和转录近百种语言。
SeamlessM4T能实现近百种语言的自动语音识别、语音到文本翻译,以及近百种输入语言和35种输出语言的语音翻译、文本转语音翻译。
构建通用语言翻译器有一定挑战性,因为现有的语音到语音、语音到文本的系统都只涵盖了全球现存语言的一小部分,SeamlessM4T扩大了语言覆盖的范围,并且是一个可以完成多种任务的统一多语言模型。
秉持其一贯的开源策略,Meta在开源协议CC BY-NC 4.0下公开发布了SeamlessM4T,开发人员可以在这个模型的基础上进行开发。同时,Meta还发布了SeamlessAlign的数据集,其博客提到这也是迄今为止最大的开放多模态翻译数据集,覆盖挖掘的语音和文本对齐总计达270000小时。
SeamlessM4T Demo体验网址:https://seamless.metademolab.com/
模型代码下载地址:https://Github.com/facebookresearch/seamless_communication
一、录音、选择、翻译一气呵成,背景噪声干扰、说话人角色区分
Meta的博客中提到一般而言,现有的语音到语音翻译过程,会被划分为多个阶段,然后不同阶段会有对应的单独系统,很少能有统一的系统去完成多个任务。
SeamlessM4T的出现就解决了语音到语音翻译任务对单独系统的依赖的难题。
打开SeamlessM4T的Demo体验网站,用户点击下方的“START RECORDING”按钮就可以开始录音,录制完成进入第二步,“SELECT TRANSLATION LANGUAGE”选择需要翻译的语言种类,最后点击下方的“TRANSLATE”就会出现翻译的文本、语音两种结果。

在Meta的测试中,SeamlessM4T在保持高资源语言性能的同时,提高了中低资源语言的翻译性能,并且在近100种语言中实现了自动语音识别、语音转文本、语音转语音、文本转语音和文本转语音等多任务支持。
为了在不依赖基于文本的指标情况下更准确地评估SeamlessM4T,研究人员将无文本指标扩展到可以进行跨语音和文本单元评估的BLASER 2.0。进行鲁棒性测试时,与当前其它模型相比,SeamlessM4T在语音转文本任务中背景有噪声和出现多个说话人时的表现更好,平均分分别提高了37%和48%。
从基本的数据来看,SeamlessM4T的模型需要大量高质量端到端数据,仅仅靠人工转录和翻译的语音无法满足近100种语言语音翻译的需求。因此,Meta为200种语言构建了大规模多语言和模态文本嵌入空间SONAR,能快速搜索具有相似性的多种语言。
同时,通过挖掘公开可用的网络数据存储库中的数百亿个句子和400玩小时的语音数据,Meta还构建了语料库SeamlessAlign,能自动将超过443000小时的语音与文本进行对齐,并创建了约29000小时的语音到语音对齐。
同时,SeamlessM4T的构建还借鉴了Meta此前的技术积累,包括去年发布的文本到文本机器翻译模型NLLB、发规模多语言翻译数据集SpeechMatrix,以及今年的跨1100种语言的语音识别技术Massively Multilingual Speech等,基于大量先前的研究成果,才使得SeamlessM4T能仅用单一模型就实现多语言和多任务的翻译功能。
二、适配多任务模型架构、语音文本编码器
为了构建统一模型,Meta的研究人员在工具包、模型架构、编码器等上都进行了适配。
Meta重新设计了序列建模工具包fairseq,并使用多任务UnitY模型架构,这一新架构能实现自动语音识别、文本到文本、文本到语音、语音到文本和语音到语音翻译。
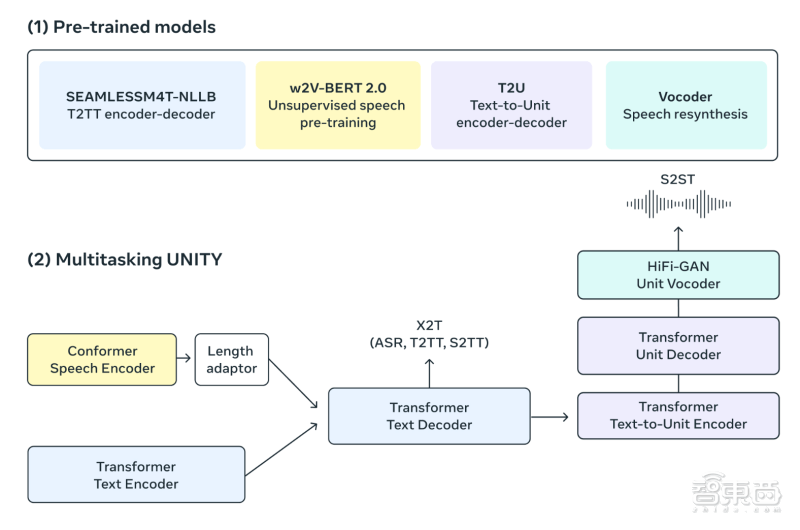
处理语音的过程中,自监督语音编码器w2v-BERT 2.0相比于w2v-BERT版本,训练稳定性和生成质量有了提升,编码器可以将获取到的音频信号分解为更小的部分构建内部表示。
文本编码器采用的是文本到文本翻译模型NLLB,它经过训练可以理解近100种语言的文本并生成对翻译有用的信息。
然后到了生成文本的步骤,通过多任务训练,Meta利用NLLB模型,通过标记级知识蒸馏来指导语音到文本翻译模型,就可以将这一编码器应用于自动语音识别、多语言翻译任务。例如,某人用法语说“bonjour(你好)”,可以将其翻译为斯瓦西里语的文本“habari”。
翻译内容的语音输出,Meta基于UnitY模型中的文本到单元(T2U)组件,这一组件可以根据文本输出生成离散语音单元,并在UnityY微调之前根据自动语音识别数据进行预训练。然后使用多语言HiFi-GAN单元声码器将这些离散单元转换为音频波形。
结语:语言翻译仍需清除有害内容输出
就Meta的测试结果来看,SeamlessM4T相比于其他系统的翻译、转录效果更好,并且覆盖的语言范围也更为广泛。
值得一提的是,与所有生成式AI存在的风险类似,翻译过程的准确性也十分重要,这一AI模型可能会错误转录用户说的话,或转录有害信息等。
因此,Meta还将高度多语言的有害性内容分类器扩展到语音,以帮助识别语音输入和输出中的有害内容。