全网真的无数据可用了!
外媒报道称,OpenAl、Anthropic等公司正在努力寻找足够的信息,来训练下一代人工智能模型。

前几天,AI target=_blank class=infotextkey>OpenAI和微软被曝出正在联手打造超算「星际之门」,解决算力难题。
然而,数据也是训练下一代强大模型,最重要的一味丹药。
面对穷尽互联网的数据难题,AI初创、互联网大厂真的坐不住了。

GPT-5训练,用上了YouTube视频
不论是下一代GPT-5、还是Gemini、Grok等强大系统的开发,都需要从大量的海洋数据中学习。
可以预见的是,互联网中高质量公共数据已经变得非常稀缺。
与此同时,一些数据所有者,比如Reddit等机构,制定政策阻止AI公司的访问数据。
一些高管和研究人员称,由于对高质量文本数据的需求,可能会在2年内超过供应,这可能会减缓人工智能的发展。
也包括2022年11月,就有MIT等研究人员警告,机器学习数据集可能会在2026年之前耗尽所有「高质量语言数据」。
 论文地址:https://arxiv.org/pdf/2211.04325.pdf
论文地址:https://arxiv.org/pdf/2211.04325.pdf
WSJ报道称,这些人工智能公司正在寻找未开发的信息源,并重新思考如何训练先进的AI系统。
知情人士透露,OpenAI已经在讨论如何通过转录YouTube公开视频,来训练下一个模型GPT-5。

为了获取更多真实数据,OpenAI还曾与不同机构合作签署协议,以便双方共享部分内容和技术。

还有一些公司采用AI生成的合成数据,作为训练材料。
不过,这种方法实际上可能会造成严重的故障。
此前,莱斯大学和斯坦福团队的研究发现,将AI生成的内容喂给模型,尤其经过5次迭代后,只会导致性能下降。
研究人员对此给出一种解释,叫做「模型自噬障碍」(MAD)。
 论文地址:https://arxiv.org/abs/2307.01850
论文地址:https://arxiv.org/abs/2307.01850
对于AI合成数据的使用,在这些公司都是秘密进行的。这种解决方案已然被视为一种新的竞争优势。
AI研究Ari Morcos表示,「数据短缺」是一个前沿的研究问题。他在去年创立DatologyAI之前。曾在Meta Platforms和谷歌的DeepMind部门工作。
他的公司建立了改进数据选择的工具,可以帮助公司以更低的成本训练AI模型.
「不过目前还没有成熟的方法可以做到这一点」。

数据稀缺,成为永恒
数据、算力、算法都是训练强大人工智能重要的资源之一。
对于训练ChatGPT、Gemini这样的大模型完全基于互联网上获取的文本数据打造的,包括科学研究、新闻报道和维基百科条目。
这些材料被分成「词块」——单词和单词的一部分,模型利用这些词块来学习如何形成类人的表达方式。

一般来说,AI模型接受训练的数据越多,能力就越强。
OpenAI正是在这种策略上大大投入,才使得ChatGPT名声远扬。
不过一直以来,OpenAI从未透露过关于GPT-4的训练细节。
但研究机构Epoch研究人员Pablo Villalobos估计,GPT-4是在多达12万亿个token上训练的。
他继续表示,基于Chinchilla缩放定律的原理,如果继续遵循这样扩展轨迹,像GPT-5这样的AI系统将需要60万亿-100万亿token的数据。

利用所有可用的高质最语言和图像数据,仍可能会留下10万亿到20万亿,甚至更多的token的缺口,目前尚不清楚如何弥合这一差距。
两年前,Villalobos在论文中写道,到2024年中期,高质量数据供不应求的可能性为50%。到2026年,供不应求的可能概率达到90%。
不过,现在他们变得乐观了一些,并估计这一时间将推迟到2028年。
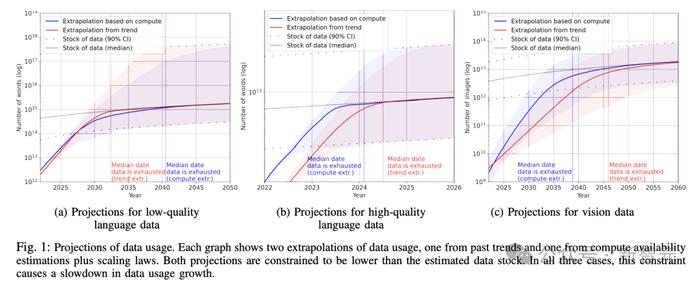
大多数在线数据对于AI的训练是无用的,因为它们包含了大量的句子片段、污染数据等,或者不能增加模型的知识。
Villalobos估计,只有一小部分互联网对模型训练会有用,可能只有CommonCrawl收集的信息的1/10。
与此同时,社交媒体平台、新闻出版商和其他公司一直在限制AI公司,使用自家平台数据进行人工智能训练,因为担心公平补偿等问题。
而且公众也不愿意交出私人对话数据(比如iMessage上的聊天记录)来帮助训练模型。

然而,小扎最近把META在其平台上获取数据的能力,吹捧为Al研究工作的一大优势。
他对外公开称,Meta可以在其网络(包括Facebook和Instagram)上挖掘数千亿张公开共享的图片和视频,这些图片和视频的总量超过了大多数常用的数据集。

数据选择工具的初创公司DatologyAI使用可一种称为「课程学习」的策略。
在这种策略中,数据以特定的序列被输入到语言模型中,希望人工智能能够在概念之间形成更智能的连接。
在2022年的一篇论文中,Datalogy AI研究人员Morcos和合著者估计,如果数据正确,模型可以用一半的时间取得同样的结果。

这有可能降低训练和运行大型生成式人工智能系统的巨大成本。
不过,到目前为止,其他的研究表明,「课程学习」的方法并不有效。
Morcos表示团队正在调整这一方法,这是深度学习最肮脏的秘密。
OpenAI谷歌要建「数据市场」?
奥特曼曾在去年对外透露,公司正在研究训模型的新方法。
「我认为,我们正处于这些巨型模型时代的末期。我们会用其他方法让它们变得更好」。
知情人士表示,OpenAI还讨论了创建一个「数据市场」。
在这个市场上,OpenAI它可以建立一种方法,来确定每个数据点对最终训练模型的贡献,并向该内容的提供商支付费用。

同样的想法,也在谷歌内部进行了讨论。
目前,研究人员一直努力创建这样一个系统,暂不清楚是否会找到突破口。
据知情人士透露,高管们已经讨论过使用其自动语音识别工具Whisper在互联网上转录高质量的视频和音频示例。
其中一些将通过YouTube公共视频进行,并且部分数据已经用于训练GPT-4。
下一步,合成数据
一些公司也在尝试制作自己的数据。
喂养AI生成的文本,被认为是计算机科学领域的「近亲繁殖」。
这样的模型往往会输出没有意义的内容, 一些研究人员将其称为「模型崩溃」。
OpenAI和Anthropic的研究人员正试图通过创建所谓的更高质量的合成数据来避免这些问题。
在最近的一次采访中,Anthropic的首席科学家JaredKaplan表示,某些类型的合成数据可能会有所帮助。同时,OpenAI也在探索合成数据的可能性。

许多研究数据问题的人都乐观认为,「数据短缺」解决方案终会出现。