深度学习有如下一些众所周知且被广泛接受的定义。
(1)深度学习是机器学习的子集。
(2)深度学习使用级联的多层(非线性)处理单元,称为人工神经网络(ANN),以及受大脑结构和功能(神经元)启发的算法。每个连续层使用前一层的输出作为输入。
(3)深度学习使用ANN进行特征提取和转换,处理数据,查找模式和开发抽象。
(4)深度学习可以是监督的(如分类),也可以是无监督的(如模式分析)。
(5)深度学习使用梯度下降算法来学习与不同抽象级别相对应的多个级别的表示,由此构成概念的层次结构。
(6)深度学习通过学习将世界表示为概念的嵌套层次来实现强大的功能和灵活性,每个概念都是根据更简单的概念定义的,更抽象的表示是根据较不抽象的概念计算来的。
例如,对于图像分类问题,深度学习模型使用其隐藏层架构以增量方式学习图像类。
首先,它自动提取低层级的特征,例如识别亮区或暗区;之后,提取高层级特征(如边缘);其次,它会提取最高层级的特征(如形状),以便对它们进行分类。
每个节点或神经元代表整个图像的某一细微方面。如果将它们放在一起,就描绘了整幅图像。而且它们能够将图像完全表现出来。此外,网络中的每个节点和每个神经元都被赋予权重。这些权重表示神经元的实际权重,它与输出的关联强度相关。这些权重可以在模型开发过程中进行调整。
(1)手工特征提取与自动特征提取。为了用传统ML技术解决图像处理问题,最重要的预处理步骤是手工特征(如HOG和SIFT)提取,以降低图像的复杂性并使模式对学习算法更加可见,从而使其更好地工作。深度学习算法最大的优点是它们尝试以增量方式训练图像,从而学习低级和高级特征。这消除了在提取或工程中对手工制作的特征的需要。
(2)部分与端到端解决方案。传统的ML技术通过分解问题,首先解决不同的部分,然后将结果聚合在一起提供输出来解决问题,而深度学习技术则使用端到端方法来解决问题。例如,在目标检测问题中,诸如SVM的经典ML算法需要一个边界框目标检测算法,该算法将识别所有可能的目标,将HOG作为ML算法的输入,以便识别正确的目标。但深度学习方法(如YOLO网络)将图像作为输入,并提供对象的位置和名称作为输出。
(3)训练时间和高级硬件。与传统的ML算法不同,深度学习算法由于有大量的参数且数据集相对庞大,需要很长时间来训练,因此应该始终在GPU等高端硬件上训练深度学习模型,并记住训练一个合理的时间,因为时间是有效训练模型的一个非常重要的方面。
(4)适应性和可转移性。经典的ML技术有很大的局限性,而深度学习技术则应用广泛,且适用于不同的领域。其中很大一部分用于转移学习,这使得人们能够将预先训练的深层网络用于同一领域内的不同应用。例如,在图像处理中,通常使用预先训练的图像分类网络作为特征提取的前端来检测目标和分割网络。
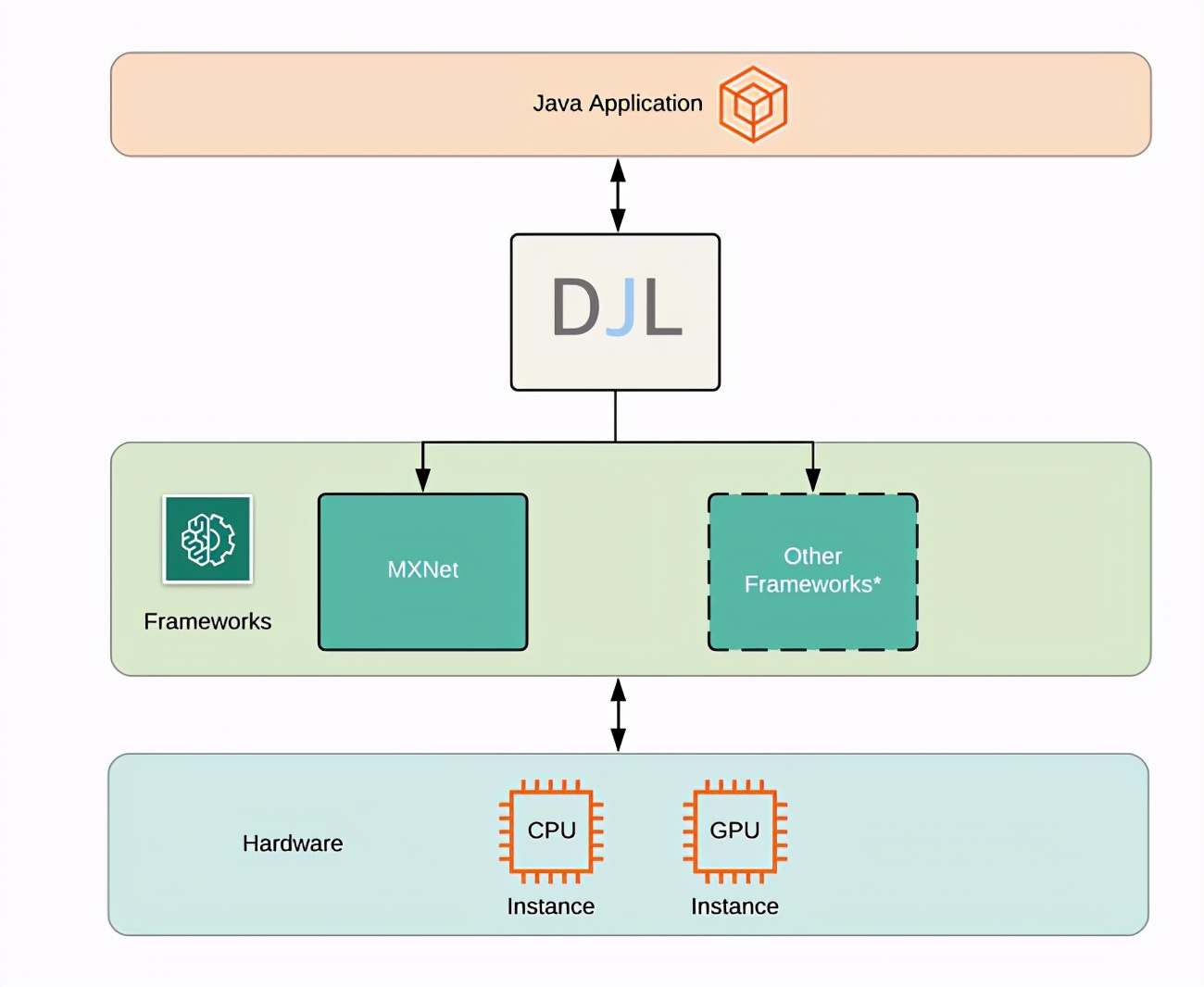
现在来看看ML和深度学习模型在图像分类(如猫和狗的图像)方面的区别。传统的ML有特征提取和分类器,可以用来解决任何问题,如图10-1所示。
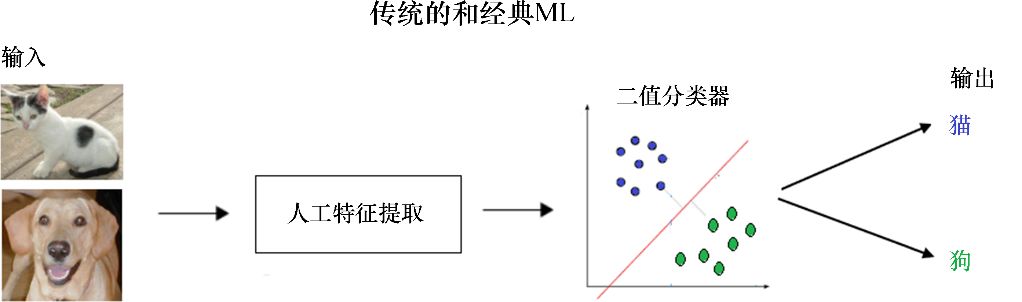
图10-1 传统的和经典的ML
图10-2所示的是深度学习网络,通过深度学习,可以看到前面讨论过的隐藏层以及实际决策过程。

图10-2 深度学习网络
如前所述,如果有更多的数据,那么最好的选择就是使用性能更好的深度网络来处理。很多时候,使用的数据越多,结果就越准确。经典的ML方法需要一组复杂的ML算法,而更多的数据只会影响其精度,需要使用复杂的方法来弥补较低准确性的缺陷。此外,学习也受到影响——当添加更多的训练数据来训练模型时,学习几乎在某个时间点停止。图10-3所示的图形描述了深度学习算法与传统的机器学习算法的性能差异。
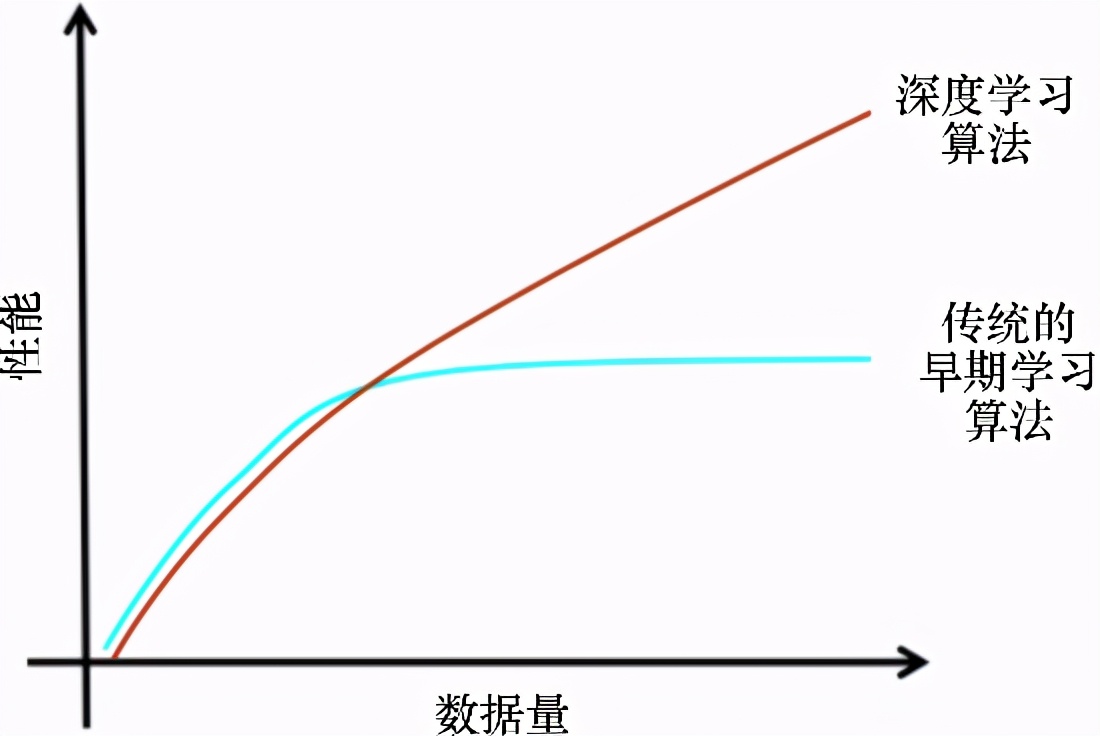
图10-3 深度学习算法与经典的机器学习算法的性能比较
本文摘自《Python图像处理实战》