
译者 | 刘涛
您可能已经使用过一些AI写作检测器,但是现在您想知道AI检测是如何工作的,对么?我不是AI研究专家。但是,我可以从数据科学的角度来解释这个问题。
我将讲述:
AI检测是利用复杂的机器学习和自然语言处理模型,实现对人工文本与机器文本的区分。它包括使用人工智能检测软件,该软件在已建立的文本库中进行训练,从而开发预测算法,这种算法能够从新的测试材料中识别出模式。然后,您会获得一个概率分值,用于判断该被评估的材料是通过人工创建还是自动创建的。
人工智能文本检测对于确保信息的可靠性非常重要,在搜索引擎优化(seo)、学术界和法律领域也能发挥关键作用。
AI内容生成器无疑很有用,而且在竞争中必不可少。但它们同样也是出了名的不可靠。因此,无论是谷歌,还是学校,以及客户,都想要确定内容,您不能不加审核就把原创内容发出去。
您能想象如果人们被允许:
信任将不复存在。
这也是为什么您要用到这些工具的原因,因为在大部分时间里,人们并不知道它们之间的区别。
我们再深入看下这些工具有那些不同的工作方式。
但这里有两个主要概念:
这些是训练模型以使用上述两个概念来检测 AI 内容时使用的更常见的一些技术。
分类器有点像哈利波特中的分类帽,将数据分到预先确定的类中。
使用机器或深度学习模型,这些分类器检查各种特征,如用词、语法、风格和语气,以区分AI生成的文本和人工书写的文本。
想象一个散点图,其中每个数据点都是一个文本条目,这些特征将形成坐标轴。
那么,假设我们有两个类:
您所测试的任何文本都将属于这两个集群中的一个。下面是我制作的图形,方便您看到。

分类器的工作是形成一个边界来分隔这两个类。
根据使用的分类器模型,一些示例包括:
注意:您不需要知道它们是什么,只需知道它们是以不同方式对数据进行排序的算法。
该边界可能是一条线、曲线或其他一些随机形状。
当您测试一个新文本(数据点)时,分类器会简单地将它们放在这些类中的任何一个中。
如果每个单词都有自己的秘密代码,就像我们在看一些惊心动魄的间谍电影一样,会怎么样?
在人工智能(AI)和语言理解方面,这正是发生的情况。
这些代码被称为嵌入式编码(Embeddings)。本质上,它们是单词唯一的DNA。通过捕捉每个术语背后的核心含义,并理解每个术语在上下文中如何与其他术语相关,这些嵌入式编码形成了一个语义网络。
这是通过将每个单词表示为N维空间中的向量并运行一些高级计算来实现的。它可以是2D、3D或302934809D。
注意:向量是一个同时具有大小和方向的量。但是对于这个解释,只需把它当作是图表上的坐标即可。
但是为什么是向量呢?
因为计算机无法理解单词。令人震惊,但这是现实。因此,必须通过向量化将单词首先转换为数字。以下是一个表格示例:

注意:向量化的文本数值可以具有广泛的取值范围,不仅仅是二进制的1或0。我只是为了更容易地可视化而做出了这样的表格。
这是另一个在二维图形上绘制向量的例子:

我确信您能够想象三维物体的外观,但请不要让我描绘四维物体,因为没人知道会是什么样。然而,通过数学算法,计算机可以使用数学魔法来呈现出四维物体。
这正是谷歌运作的方式。您在搜索栏中输入内容,却能获得与其惊人相关的结果,这是如何实现的呢?
但是,如何区分人工生成的文本与使用 AI 生成的文本呢?
我们将所有文本转换为它们各自的嵌入式向量,然后将它们输入机器学习模型进行训练。
模型即使不知道任何实际的措辞,也会形成所有这些连接,并找出与 AI 生成文本常见的所有“代码”。
但是,如何区分人工生成的文本与使用 AI 生成的文本呢?
我们将所有文本转换为它们各自的嵌入式向量,然后将它们输入机器学习模型进行训练。
模型即使不知道任何实际的措辞,也会形成所有这些连接,并找出与 AI 生成文本常见的所有“代码”。
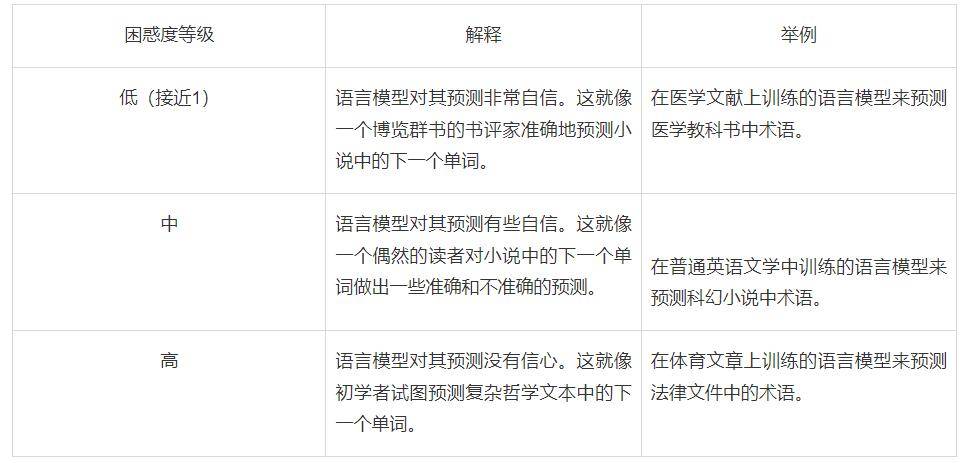
困惑度(Perplexity):AI 生成文本的试金石
困惑度是一个衡量概率分布或语言模型能够预测样本精度的指标。
在 AI 生成内容检测的背景下,困惑度作为衡量 AI 生成文本的试金石。困惑度越低,文本由 AI 生成的概率越大。
这就像侦探使用指纹匹配来识别嫌疑人一样。
以下的表格对此进行了详解:
爆发度是由 AI 模型生成的句子长度和复杂程度的变化。
想象一下您在一家餐厅里,现场充斥着各种对话,有些大声喧哗,有些安静私密。与这些对话相似,由人写出的句子有很多细微差别,因此常常让人难以预料。
但是,AI 模型产生的结果通常在长度和复杂性上更趋于一致,而人类写作则表现出更多的多样性或者说“爆发性”。如果 AI检测器注意到句子的长度、结构和节奏的细微差异,它们也会将文本标记为潜在的 AI生成文本。
以下表格中的一些例子:

我会直截了当地告诉您,即使分数为100%,它也永远不会是100%准确的。
那只是模型的置信度。
当 AI 检测器分析文本时,它通常会基于所给材料的显著特征计算每种分类的分数或概率,而不仅仅由人类编写或 AI 生成的内容之间的区别所决定。
例如,假设我们使用 AI 检测器对某些文本进行了分析,它为“AI”和“人类”分别给出了0.7和0.3的分数。
这些数字表示我们的检测器已经大致判断出,我们的材料属于同种类型和非同种类型的概率之比为7:3(70%对30%)。
因此,最终决定是否适用某种类型变得非常容易。
与其把事物划分为“人类”与“AI”,倒不如给它们分配概率度量,这样才能更深入地了解预测的可信度。除了把文字归类成两类外,还需要考虑许多因素来决定文字是由人写的还是由AI写的。
如果所使用的评估方法涉及计算概率得分,则这些得分之间的差距程度可能会影响 AI 模型对预测的确定性。
例如,如果分配给 AI 生成的作品和人工完成的作品的分数之间没有太大的差异(例如得分分别为0.51和0.49),那么检测它们的来源将比它们的概率差距很大的情况更具挑战性(例如获得0.9和0.1的概率差距)。
因此,尽管产生二进制结果,但这个决定包括详细的分析,很大程度上依赖于概率得分之间的差异。
注意:您可能会看到其他文章讨论 AI 检测器如何通过计算每个单词成为下一个预测单词或温度参数(temperature:指一种用于控制生成文本的随机性和创造性的参数,通常使用softmax函数实现)的概率值来工作。这是指 AI 作者的工作方式,而不是 AI 检测器。那些文章完全搞错了搜索意图。
这是一个相当长的段落,但这是我能够最好地解释它的方式。
随着我们见证人工智能的进一步发展,机器生成内容的复杂程度也在不断增加,这给有效检测此类内容带来了独特的挑战。因此,所有参与其开发过程的人都需要努力创建更加先进和准确的工具,以跟上应对这种复杂性的能力。
准确检测由AI生成的虚假信息对于维护在线信息的可信度至关重要,这将是有效应对这些威胁的唯一途径。
此外,我们需要特别关注与隐私侵犯、违背意愿和潜在的滥用这种强大技术相关的道德考虑。
以下是一些最受益于使用AI检测的群体:
学校:防止学生滥用AI写作软件。
企业:摆脱垃圾邮件、虚假评论或虚假新闻。
执法机构:消除冒充、身份欺诈和网络欺凌等犯罪活动。
社交媒体平台:清除散布和鼓吹不实信息的机器人和虚假账号。
媒体和新闻组织:识别虚假新闻和宣传,甚至替换过度依赖AI的作家。
政府组织:根除虚假信息的运动和宣传。
AI内容检测工具是否存在限制或缺陷?
AI内容检测工具确实存在一些限制和缺陷。随着人工智能产生的内容不断增多,人们越来越难分辨出这些文字是否是由人类产生的,因此它们的准确性并不总是完美的。
此外,AI检测器可能难以识别那些被特意设计成不可被检测出的AI生成内容。未来AI生成和检测技术的发展将共同决定AI检测的局限性程度。
为什么要在SEO中使用AI检测?
尽管谷歌在最近的更新中表示,如果AI生成的内容有价值,就不再会被视为垃圾内容,但关于谷歌是否能够检测到AI生成的内容,仍然有争议。您永远无法真正知道谷歌何时或是否会改变立场而对您进行惩罚。因此,大多数SEO(搜索引擎优化)仍会使用AI检测来确保安全。
AI检测的准确性如何?
AI检测只能准确判断所检测文本与其训练数据的相似程度。它提供的是置信度评分,而不是简单的是或否的结果。
我已经介绍了您需要了解的有关AI检测的所有内容。从为什么需要它,训练这样一个模型背后的真正过程,到它的准确性以及它的前景。
我希望这可以帮助您更好地了解这个话题。
译者介绍
刘涛,51CTO社区编辑,某大型央企系统上线检测管控负责人。

























