
如今国内市场的“百模大战”正如火如荼,无论是BAT这样的传统豪强,还是美团、字节跳动这样的新兴巨头,乃至科大讯飞等传统AI厂商都已入局。但提到AI大模型,似乎大家还是认为ChatGPT、Bing Chat、Bard等海外厂商的相关产品往往更加好用。
事实上,这并非错觉。近期牛津大学进行的一项研究就显示,用户所使用的语言对于大型语言模型(LLM)的训练成本有着密切的联系。
根据这一研究结果显示,按照OpenAI采用的服务器成本衡量和计费方式,让一个LLM处理一句缅甸掸语的句子需要198个词元(tokens),但同样的句子用英语写则只需17个词元。据统计,简体中文的训练费用大约是英语的两倍,西班牙语是英语的1.5倍,而缅甸的掸语则是英语的15倍。词元通常是指语料中文字存在的最小单位,但它的具体指代则是多变的,既可以是字、也可以是分词结果的词。
由于AI业界目前会使用词元来代表通过OpenAI或其他厂商API访问大模型所需的计算成本,所以也就意味着牛津大学的这项研究表明,英语才是目前训练大模型最便宜的语言,其他语言的成本则要大得多。
那么为什么会造成这一现象呢?用中文本身相比于英文更加复杂来解释显然并不科学,毕竟现代语言学是欧洲创建起来的,甚至现代汉语的语法分析原理也脱胎于西方的语法分析原理。

汉藏语系的语法结构与印欧语系相去甚远,参照印欧的屈折型语法来看以汉语为代表的孤立型语法,当然会觉得复杂。然而,词元(tokens)是以OpenA视角里中的训练成本来定义的,不是以字符来划分。而且,英文单词间是存在空格的,对英文文本处理时可以通过空格来切分单词。然而中文词之间不存在天然地空格,并且中文词是由多个字构成的,所以对于中文文本处理之前首先要进行分词。
真正导致用英文训练AI大模型成本更低的原因,是OpenAI等厂商的分词算法与英文以外其他语言的语义理解技术不到位有关。以OpenAI为例,作为一家美国公司,其团队在训练大模型时必然会选择以英语语料为起点,标注人工的投入显然也是英语系最方便,毕竟这会直接影响到大模型训练的强度和产出,也是为什么他们选择的人工标注团队在肯尼亚,而后者作为英联邦国家,以英语为官方语言、且教育水平较高。
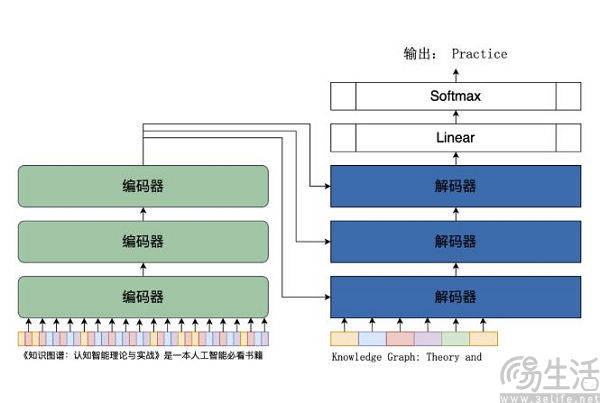
AI理解不同语言不是通过翻译,而是直接学习相关语言的文本。那么AI大模型使用不同语言的能力差别又从何而来呢?答案是不同语言语料的丰富程度。此前百度的“文心一言”在内测过程中出现文生图不符实际的情况,就曾有主流观点认为,这是由于中文自然语言处理领域缺乏高质量中文语料所导致的结果。
而语料则是AI大模型的基础,生成式AI的原理大概可以总结为,通过大量的语料库进行训练,再从各种类型的反馈中进行流畅的学习,并根据需要对反馈进行整理,以建立相应的模型,从而使得AI能够对人类的问题做出相应的回答和决策。AI大模型之所以比以往的AI产品表现得更“聪明”,单纯是因为语料规模更大,比如OpenAI的GPT-3就拥有1750亿的参数量。

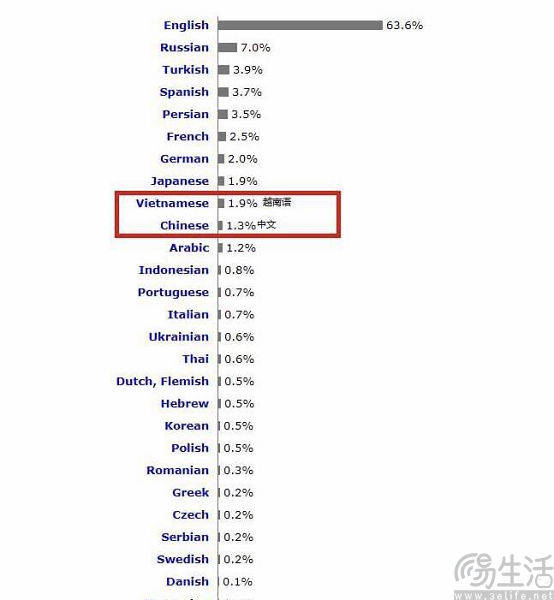
“力大砖飞”其实是当下大模型的底层逻辑,在这种情况下,语料基本就决定了它们的上限。语料肯定是越多越好,但如今的事实,却是英文才是目前互联网世界中使用人群规模最大、使用频率最高的语言。在去年6月,W3Techs又一次发布的全球互联网网页统计报告中就显示,英语仍一骑绝尘,占比高达六成(63.6%)以上,俄语为第二名(7%),中文则仅有1.3%、排名第八。
当然,W3Techs的统计只包含了网站,这也是为什么占全球网民五分之一的中文互联网中,能够拿得出手的网站仅占全球网站的1.3%。毕竟由于国内发达的移动互联网生态,App才是主体,大量信息已经聚集在了各式各样的App中,并且这些信息也难很通过爬虫获取,所以也导致其很难进行准确的统计。
这样的状态自然也导致了汉语语料库的匮乏,因为AI行业的惯例是使用互联网公开数据,而App里的数据则是属于运营方的,违规抓取App内数据是妥妥的违法行为。而国内互联网大厂将信息牢牢控制在自家App里,进而也导致了公开的中文语料不增反减。
不同于海外市场Reddit、Twitter这类愿意卖数据的平台,将无边界扩张思维铭刻在脑海里的国内互联网巨头,几乎每一家都在贪大求全,而敝帚自珍更是成为了各家共同的选择。既然互联网上的公开信息是以英文为主,即使国内的AI大模型训练往往也是从英文为起点,所以文心一言会出现“英翻中”的现象也就不足为奇了。

归根结底,AI大模型使用不同语言的训练成本,其实和该语言构筑的互联网生态繁荣程度呈现正相关。例如丹麦语、荷兰语等小语种使用者在互联网上留下的内容过于匮乏,就导致训练AI大模型使用它们来输出内容不光成本更高,而且效果也更差。但更加不妙的是,由于马太效应的影响,英文在AI领域的强势地位还或将会持续增强。
因此国内市场的AI大模型想要更好用,获得足够、且高质量的语料库是关键。互联互通这个已经被提出多时的概念真正被贯彻的那一刻,或许才是中文AI大模型比肩ChatGPT们的时候。


























