
译者 | 李睿
本文作者Martin Heller是一名Web和windows编程顾问,也是行业媒体InfoWorld的特约编辑和评论员。Heller表示,他在2021年11月撰写关于Github Copilot的文章时,Copilot是当时发布的为数不多的人工智能代码生成技术之一。他将GitHub Copilot作为Visual Studio代码扩展进行了测试。当时,Copilot并不总是能生成良好的、正确的、甚至是可运行的代码,但它仍然有一些用处。Copilot(以及其他使用机器学习的代码生成器)背后的巨大承诺是,它的设计是通过将用户反馈和将新代码样本摄取到其训练语料库中,并且随着时间的推移而改进。
截至2023年5月,仅Visual Studio code就有数百个“人工智能”或“代码生成”扩展可用。其中一些可能会在编码时为用户节省一些时间,但是用户不能在没有检查、测试和调试的情况下就相信它们生成的代码。
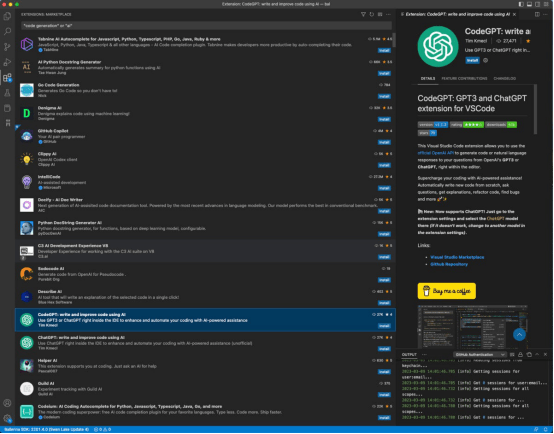 图1
图1
市场上有数以百计的Visual Studio Code承诺“代码生成”或“人工智能”扩展可用,但实际上只有一小部分基于机器学习生成代码
在这一领域一个很有前途的发展是一些工具可以自动生成单元测试。生成单元测试是一个比生成通用代码更容易处理的问题——事实上,它可以使用简单的模式来完成,但是用户仍然需要检查和运行生成的测试,以确定它们是否有意义。
本文将简要介绍语言模型的历史,然后考察最先进的大型语言模型(LLM),例如AI target=_blank class=infotextkey>OpenAI公司的GPT家族和谷歌公司的LaMDA和PaLM,它们目前用于文本生成和代码生成。最后,将简单介绍10个代码生成工具,其中包括Amazon CodeWhisperer、google Bard和GitHub Copilot X等。
语言模型可以追溯到安德烈·马尔科夫在1913年提出的马尔可夫链,这是马尔可夫模型的一个特例。马尔科夫指出,在俄语中,特别是在普希金的韵文小说《尤金·奥涅金》中,一个字母出现的概率取决于前一个字母,而且一般来说,辅音和元音往往交替出现。此后,马尔可夫方法被推广到词汇、其他语言和其他语言应用中。
1948年,克劳德·香农(Claude Shannon)在通信理论方面扩展了马尔可夫的理论,1985年,IBM公司的Fred Jelinek和Robert Mercer再次扩展了马尔科夫的理论,产生了一个基于交叉验证(他们称之为删除估计)的语言模型,并将其应用于实时、大词汇量的语音识别。从本质上讲,统计语言模型为单词序列分配概率。
要想快速查看语言模型的运行情况,可以在谷歌搜索或智能手机上的短信应用程序中输入几个单词,并允许它提供自动完成选项。
2000年,Yoshua Bengio等人发表了一篇关于神经概率语言模型的论文,其中神经网络取代了统计语言模型中的概率,绕过了维度的诅咒,并将单词预测(基于以前的单词)提高了20%~35%,而不是平滑的三元模型(当时是最新技术)。语言的前馈、自回归、神经网络模型的思想至今仍在使用,尽管这些模型现在有数十亿个参数,并且是在广泛的语料库上训练的,因此有了“大型语言模型”这个术语。
正如人们将看到的,随着时间的推移,语言模型的规模不断变得更大,以使它们表现得更好。然而,这样做是有代价的。2021年发表的论文《随机鹦鹉的危险:语言模型是否太大?》的作者Emily Bender、Timnit Gebru质疑人们是否在这一趋势上走得太远。他们建议,除了其他事项之外,人们应该首先权衡环境和财务成本,并将资源投入到整理和仔细记录数据集上,而不是从网络上摄取一切。
Gebru和Bender后来都因为指责谷歌公司在人工智能的道德应用问题而辞职。Bender现在入职华盛顿大学,而Gebru创立了分布式人工智能研究所。
最近大型语言模型的爆发是由Google Brain项目和Google Research项目的Ashish Vaswani等人在2017年发表的论文《注意力就是你所需要的一切》引发的。该论文介绍了“Transformer这种新的简单网络架构,它完全基于注意力机制,完全省去了递归和卷积。”Transformer模型比递归和卷积模型更简单,也更优越。它们训练所需的时间也显著减少。
ELMo
ELMo是AllenNLP在2018年推出的深度语境化单词表示(参见ELMo论文),它既模拟了单词使用的复杂特征(例如语法和语义),也模拟了这些用法在不同的语言语境中是如何变化的(例如建模多义性)。其最初的模型有9360万个参数,并在十亿个单词基准上进行训练。
BERT
BERT是来自Google AI Language的2018年语言模型,基于该公司的Transformer(2017)神经网络架构(参见BERT论文)。BERT的目的是通过在所有层中对左右场景进行联合条件反射,从未标记的文本中预训练深度双向表示。原文中使用的两种模型规模分别是1亿个参数和3.4亿个参数。BERT使用掩码语言建模(MLM),其中约15%的令牌被“破坏”用于训练。它是在英文维基百科和多伦多图书语料库上训练的。
T5
来自谷歌的2020文本到文本传输转换器(T5)模型(见T5论文)使用一个新的开源预训练数据集,称为Colossal Clean Crawled Corpus (C4),基于来自GPT、ULMFiT、ELMo和BERT及其后继者的最佳迁移学习技术,综合了一个新的模型。C4是一个基于CommonCrawl数据集的800GB数据集。T5将所有自然语言处理任务重新构建为统一的文本到文本格式,其中输入和输出始终是文本字符串,而BERT风格的模型只输出一个类标签或输入的一个范围。基本的T5模型总共有大约2.2亿个参数。
GPT家族
OpenAI公司是一家人工智能研究和部署公司,其使命是“确保通用人工智能(AGI)造福人类”。当然,OpenAI公司还没有实现通用人工智能(AGI)。一些人工智能研究人员(例如Meta-FAIR的机器学习先驱Yann LeCun)认为OpenAI公司目前研究的通用人工智能(AGI)方法是一条死胡同。
OpenAI公司开发了GPT语言模型家族,这些模型可以通过OpenAI API和微软的Azure OpenAI服务获得。需要注意的是,整个GPT系列都是基于谷歌公司的2017 Transformer神经网络架构,这是合法的,因为谷歌公司开放了Transformer的源代码。
GPT(生成预训练Transformer)是OpenAI公司在2018年开发的一个模型,使用了大约1.17亿个参数(参见GPT论文)。GPT是一个单向转换器,它在多伦多图书语料库上进行了预训练,并使用因果语言建模(CLM)目标进行了训练,这意味着它被训练为预测序列中的下一个标记。
GPT-2是GPT的2019年直接扩展版,具有15亿个参数,在800万个网页或约40GB的文本数据集上进行了训练。OpenAI公司最初限制使用GPT-2,因为它“太好了”,会产生“假新闻”。尽管随着GPT-3的发布,潜在的社会问题变得更加严重,但该公司最终还是让步了。
GPT-3是一个2020年开发的自回归语言模型,具有1750亿个参数,在Common Crawl、WebText2、Books1、Books2和英语维基百科的过滤版本的组合上进行训练(见GPT-3论文)。GPT-3中使用的神经网络与GPT-2中使用的类似,有几个额外的块。
GPT-3最大的缺点是它容易产生“幻觉”,换句话说,它在没有辨别依据的情况下编造事实。GPT-3.5和GPT-4也有同样的问题,尽管程度较轻。
CODEX是GPT-3在2021年推出的新一代模型,针对5400万个开源GitHub存储库的代码生成进行了微调。这是GitHub Copilot中使用的模型,将在下一节中讨论。
GPT-3.5是GPT-3和CODEX在2022年的一组更新版本。GPT-3.5-turbo模型针对聊天进行了优化,但也适用于传统的完成任务。
GPT-4是一个2023年的大型多模态模型(接受图像和文本输入,发出文本输出),OpenAI公司声称它在各种专业和学术基准上表现出人类水平的性能。GPT-4在许多模拟考试中表现优于GPT-3.5,包括统一律师考试、LSAT、GRE和几个AP科目考试。
值得关注的是,OpenAI公司没有解释GPT-4是如何训练的。该公司表示,这是出于竞争原因,考虑到微软公司(一直在为OpenAI公司提供资金)和谷歌公司之间的竞争,这在一定程度上是有道理的。然而,不知道训练语料库中的偏差意味着人们不知道模型中的偏差。
Emily Bender对GPT-4的看法(于2023年3月16日发表在Mastodon上)是“GPT-4应该被认为是有毒的垃圾,除非OpenAI公司对其训练数据、模型架构等进行开放。”
ChatGPT和BingGPT是最初基于GPT-3.5-turbo的聊天机器人,并于2023年3月升级为使用GPT-4。目前使用基于GPT-4的ChatGPT版本,需要订阅ChatGPTPlus。基于GPT-3.5的标准ChatGPT是根据2021年9月截止的数据进行训练的。用户可以在微软Edge浏览器中访问BingGPT,它也接受了2021年中断的数据的训练,但它说(当你问它时) “我正在不断学习,并用网络上的新信息更新我的知识。”
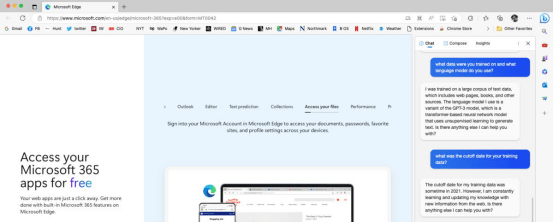 图2 BingGPT在图片右侧解释其语言模型和训练数据
图2 BingGPT在图片右侧解释其语言模型和训练数据
2023年3月初,香港科技大学人工智能研究中心的Pascale Fung就ChatGPT评估进行了演讲。
LaMDA(对话应用程序语言模型)是谷歌2021年的“突破性”对话技术,是2017年针对对话训练的Transformer模型,经过微调,可以显著提高其反应的敏感性和特异性。LaMDA的优势之一是它可以处理人类对话中常见的话题漂移。
LaMDA的一个版本为谷歌公司的对话式人工智能服务Bard提供了动力。Bard于2023年3月21日发布,并于2023年5月10日全面发布。以下将讨论它的代码生成功能。
PaLM
PaLM (路径语言模型)是来自Google Research的2022年密集的纯解码器Transformer模型,具有5400亿个参数,使用Pathways系统进行训练(参见PaLM论文)。PaLM是使用英语和多语言数据集的组合进行培训的,这些数据集包括高质量的网络文档、书籍、维基百科、对话和GitHub代码。
谷歌公司还为PaLM创建了一个“无损”词汇表,它保留了所有空白(对代码尤其重要),将词汇表外的Unicode字符拆分成字节,并将数字分割成单独的令牌,每个数字一个令牌。PaLM Coder是PaLM 540B的一个版本,仅对Python/ target=_blank class=infotextkey>Python代码数据集进行了微调。
PaLM-E
PaLM-E是谷歌公司在2023年推出的“具体化”(用于机器人)多模态语言模型。研究人员从一个强大的大型语言模型PaLM开始,并通过补充机器人代理的传感器数据来具体化它(PaLM-E中的“E”)。PaLM-E也是一个功能强大的视觉和语言模型。除了PaLM之外,它还集成了ViT-22B视觉模型。
LLaMA
LLaMA(大型语言模型元人工智能)是由Meta AI(又名Meta- FAIR))于2023年2月发布的650亿个参数的“原始”大型语言模型。Meta表示,“在大型语言模型空间中训练像LLaMA这样的小型基础模型是可取的,因为它需要更少的计算能力和资源来测试新方法,验证其他人的工作,并探索新的用例。基础模型在大量未标记的数据上进行训练,这使得它们非常适合针对各种任务进行微调。”
LLaMA以多种尺寸发布,同时还发布了一张模型卡,详细说明了模型是如何构建的。Meta-FAIR的Yann LeCun表示,最初,用户必须请求检查点和标记器,但现在它们已经被释放了,因为有人通过提交请求正确获得了模型,并在4chan上发布了一个可下载的种子。
虽然包括ChatGPT和Bard在内的一些大型语言模型可以生成用于发布的代码,但如果它们对某些代码进行微调,通常是来自免费开源软件的代码,以避免公然侵犯版权。这仍然引发了“开源软件盗版”的担忧,比如2022年针对GitHub、微软(GitHub的所有者)和OpenAI公司的GitHub Copilot产品和OpenAI GPT Codex模型提起集体诉讼的主张。
需要注意的是,除了使用在公共可用代码上训练的人工智能模型之外,一些代码生成工具依赖于搜索代码共享网站,例如Stack Overflow。
Amazon CodeWhisperer
Amazon CodeWhisperer集成了Visual Studio Code和JetBrains IDE,根据现有代码生成代码建议以响应注释和代码完成,并可以扫描代码以查找安全问题。用户还可以激活CodeWhisperer,以便在AWS Cloud9和AWS Lambda中使用。
CodeWhisperer很好地支持Python、JAVA、JavaScript、TypeScript和C#编程语言,以及其他10种编程语言。它对个人开发人员是免费的,对专业团队来说,每个用户每月需要支付19美元。
Heller采用CodeWhisperer编写了如下所示的Python代码,并对它进行了审查、测试和调试,其结果很好。
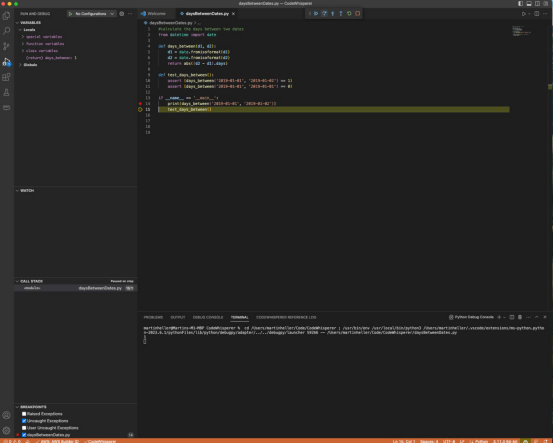 图3
图3
Heller使用Amazon CodeWhisperer生成代码。在文件的顶部输入了注释,剩下的大部分都是CodeWhisperer。Heller必须从几个选项中选择代码,并从前一个选项中删除未使用的导入语句
Bard
Bard于2023年4月21日宣布支持编程。该公告指出,支持20多种编程语言,包括C++、Go、Java、JavaScript、TypeScript和Python。作为一个快速测试,Heller让Bard“编写一个Go函数来返回当前的日期和时间。”它做得很快:
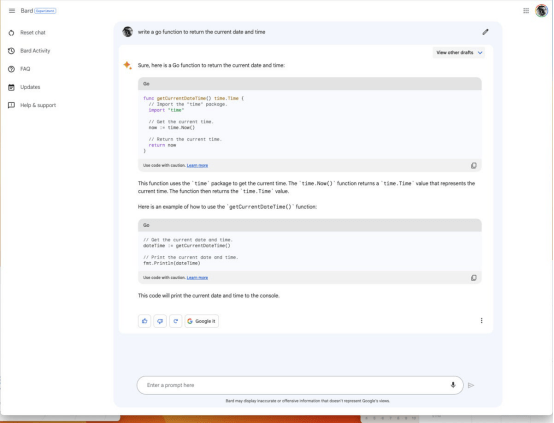 图4
图4
Bard生成了一个正确的Go语言函数,一个使用该函数的示例,以及对该函数的解释,所有这些都来自“编写一个Go函数以返回当前日期和时间”的提示。注意复制函数和测试代码的图标
Bard不仅编写了这个函数,还解释了这个函数,并生成了一个调用函数的例子。
CodeT5
CodeT5是Salesforce AI Research的2021代码特定的统一预训练编码器-解码器转换器模型。它基于2020年谷歌T5模型架构,并对CodeSearc.NET数据集和BigQuery的一些C/C#代码进行了微调。CodeT5的官方PyTorch实现位于GitHub上,在Hugging Face上有两个检查点,在GitHubREADME中有链接。
GitHub Copilot
当Heller在2021年11月审查GitHub Copilot的预发布版本时,他发现,虽然它并不总是生成良好的、正确的、甚至运行的代码,但它仍然有些有用。Copilot基于OpenAI Codex,而OpenAI Codex又基于GPT-3,GPT-3经过微调,可以在5400万个开源GitHub存储库上生成代码。GitHub Copilot目前的费用是每月10美元或每年100美元,除非用户有资格获得免费版本。
Heller喜欢Copilot在Visual Studio Code中的工作方式。基本上,必须编写函数的第一行,或者描述函数的注释,然后Copilot将生成多达10个版本的函数,可以按原样使用,编辑或不使用。正如Heller在上面所指出的,应该对Copilot生成的任何代码持保留态度,因为它确实容易产生幻觉,例如在下面的示例中第8行和第9行的代码注释中。
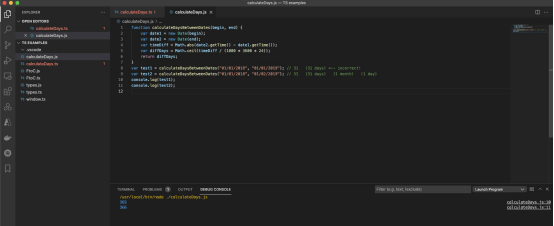 图5
图5
代码由GitHub Copilot制作。通过输入行首和一堆制表符,生成了第8行和第9行。Heller输入了第10行和第11行的开头,Copilot完成了第11行。注意,第8行和第9行中生成的关于预期结果值的不正确注释
GitHub Copilot X
目前处于技术预览阶段的GitHub Copilot X基于GPT-4。它通过聊天和终端界面、生成单元测试的能力、生成拉取请求描述的能力以及从文档中提取解释的能力“升级”了原始的Copilot。
GitHub Copilot X比原来的GitHub Copilot有了很大的改进,有时可以在没有太多人工帮助的情况下生成正确的函数和一组测试。它仍然会犯错误和产生幻觉,但远不如它的前身那么多。作为参考,以下是Heller写的原始Copilot。
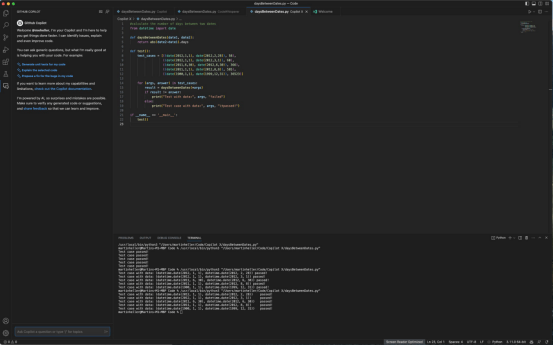 图6
图6
Heller能够让GitHub Copilot X生成大部分正确的函数和良好的参数化测试集,只需在顶部输入注释并按Enter和Tab四到五次
IntelliSense和IntelliCode
Microsoft IntelliSense是Visual Studio和Visual Studio代码的内置功能,它使用语言语义为短代码完成提供一个选项菜单。它通常能很好地帮助用户找到所需的API或方法调用,但往往会提供许多选择。
IntelliCode是IntelliSense的一个增强插件,它使用在本地机器上运行的人工智能来检测代码场景——包括变量名、函数和正在编写的代码类型,并提供最好的建议,在某些情况下可提供整行补全。IntelliCode还可以帮助用户清理重复的代码,并为常见的编程任务推荐快速操作。
IntelliCode在Visual Studio 2022中与C#、C++、Java、SQL和XAML配合使用,在Visual Studio代码中与TypeScript、JavaScript和Python配合使用。
Kite
Kite是2014年至2021年使用人工智能帮助开发者编写代码的早期尝试。尽管它吸引了50多万名开发者,但却从未创造任何收益。Kiteco存储库包含其大部分源代码,但有一些私有位已被XXXXX取代,因此一些代码无法运行。
PolyCoder
PolyCoder是卡内基梅隆大学用于代码生成的2022,27亿个参数的开源大型语言模型(见论文)。它基于GPT-2模型架构,并在12种编程语言的249GB代码上进行了训练。在C编程语言中,PolyCoder优于包括Codex在内的所有模型。
Replit Ghostwriter
Replit Ghostwriter于2022年万圣节发布,提供五种功能:代码完成、代码解释、代码转换、代码生成以胶带调试的错误检测,每月10美元(或多或少,取决于用户使用的“周期”数量)。它与Replit在线编辑器集成,支持Python、Ruby、JavaScript、TypeScript、html、css、Go、Lisp、Haskell、Bash、C、C++、Rust、Java和JSON。
根据Replit公司的说法,Ghostwriter“返回由公开可用代码训练并由Replit调优的大型语言模型生成的结果。”Replit没有指定用于Ghostwriter的大型语言模型或训练语料库,这使它与Emily Bender对GPT-4的指控相同:除非Replit公开其训练数据,模型架构等,否则应该假设Ghostwriter是有毒垃圾。这也让Replit面临着与GitHub Copilot同样的“开源软件盗版”指控。
Tabnine
Tabnine来自总部位于以色列特拉维夫的Tabnine公司,看起来就像服用了类固醇的IntelliSense,可以选择在用户自己的代码语料库上进行训练,也可以在开源代码上进行训练。它可以在编辑器或IDE中完成整行和全功能的代码补全,支持20种这样的工具,从Visual Studiocode和IntelliJ到Emacs和Vim。
根据用户选择的计划,Tabnine可以使用一种通用的人工智能模型,这种模型是在许可的开源代码上训练的,或者一组针对所有编程语言优化的生成人工智能模型“专门用于匹配的技术堆栈”,或者在用户自己的存储库上训练的私有代码模型。
Tabnine的免费Starter计划只提供基本的代码补全功能。Pro计划以每个用户每月12美元的价格完成全线和全功能代码。Tabnine尚未披露其模型架构或训练语料库。因此,根据Emily Bender原则,用户应该对它生成的任何代码进行最坏的假设。
大型语言模型有时可以用于生成或完成代码,无论它们是否在代码语料库上进行过训练。经过代码训练的语言模型往往更了解空白的重要性。而像OpenAI Codex和Tabnine这样的代码生成产品通常比更通用的语言模型与编程编辑器有更好的集成。
人们应该期待AI代码生成器随着时间和使用而改进。GitHub Copilot X比原来的Copilot更好,并相信下一个Copilot会更好。然而,永远不能假设任何类型的人工智能生成的代码都是正确或有效的,甚至不能假设它可以编译并运行。应该将人工智能生成的代码视为来自未知程序员的拉取请求,这意味着在将其作为应用程序的一部分之前,要对其进行审查、测试和调试。
原文标题:LLMs and the rise of the AI code generators,作者:Martin Heller


























