
如果AI target=_blank class=infotextkey>OpenAI有最想划掉的经历,那么大概率就是推出AI Classifier了。
作为轰动全球的ChatGPT的研发者,OpenAI在AI时代所获得的关注无人能比。然而,就是这么一家在AI领域让人难以望其项背的公司,最近却遭遇了滑铁卢。
今年1月,OpenAI推出了可以识别文本来源类别的应用AI Classifier。OpenAI原打算用它来检测某个文本的来源是人工智能编写还是人类编写。然而,它的表现出乎意料的差。
AI Classifier的正确识别率不仅不尽如人意,甚至比不上其它毫不知名的小公司所开发的工具,短短半年时间就被停止了服务。
自知面上无光的OpenAI甚至把停止服务的公告都隐藏在1月份发布的文章里面,采用内容更新的方式编辑的旧闻。

AI Classifier的失败从侧面证实了,目前,OpenAI并没有有效的办法控制ChatGPT所造成的影响。
而这件“停服小事”已经淹没在信息海洋中,并没有引发大家足够的重视。
2022年11月底,ChatGPT一经推出就火遍全球,短短5天时间吸引了上百万用户,仅用两个月就达到上亿月活,蹿红速度前无古人,甚至在并没有开通服务的大洋彼岸引发了一次大模型进化风潮。无数的中小公司改头换面,套壳蹭热度,甚至一时之间在BOSS上新诞生出了ChatGPT运营、ChatGPT提示词工程师等等岗位。一波又一波的新媒体人通过视频、图文等方式,教网友怎么靠AI赚钱。
B端企业更是嗷嗷待哺,一系列与AI有关的公司突然成为当红炸子鸡。前脚还骂百度错过了移动时代的人,后脚就夸百度是个有远见的长期主义者。在某些“大厂”内部,更是全员开脑洞,集体研究大模型可以如何运用,怎么和现有业务相结合。甚至有车企表示,把大模型集成到车机系统中,也是正在考虑的事项。
而身在ChatGPT核心地带的小孩们,则成为首批通过ChatGPT获益的人。Study的一项调查显示,有超过89%的学生通过ChatGPT做作业,这引发了教育界的普遍担忧。而这些担忧中,也包含部分老师的惊讶。有美国教师表示,尝试用ChatGPT为学生评估作业,发现ChatGPT迅速的提供了比他自己更详细更有用的反馈。
相比于鼓吹AI能力的科技作者,教育界的担忧还体现在传统教育思维有可能被打破的困扰上。美国权利法案研究所的一项投票显示,有52.8%的人认为应该禁止ChatGPT进入课堂。他们认为,人工智能对传统学习构成了威胁。此外,ChatGPT还有被剽窃、给出错误答案和误导人的嫌疑。有人留言警告称,ChatGPT开始取代批判性思维。
根据报道,包括美国在内,多地多所学校曾禁止学校设备和网络对ChatGPT的访问,英国的伦敦帝国理工大学和剑桥大学等顶尖大学也都发表声明,警告学生不要使用ChatGPT作弊。而对于ChatGPT究竟是改变教育还是摧毁教育,网络上的争辩此起彼伏,但提及最多的,还是这种工具的依赖性会摧毁人们的批判性思维和创造力。
此外,来自科学界的声音也将矛头对准了ChatGPT。《科学》杂志明确禁止将ChatGPT列为合著者,且不允许在论文中使用ChatGPT所生产的文本。《自然》杂志表示,可以在论文中使用大型语言模型生成的文本,但不能将其列为论文合著者。
而在文本之外,由AI生产的图片和视频则更具欺骗性,有关于此前AI换脸所带来的道德问题被重新提及。在这种情况下,如何分辨内容来自人类还是AI就变得尤为重要。
如果说,教育和科研界对于ChatGPT的担心更多的是用户使用层面,那么来自于国家政策方面的阻力以及对安全性的担忧则对OpenAI生存造成了极大挑战。
在今年3月底,意大利个人数据保护局宣布,暂时禁止使用ChatGPT,并表示已对ChatGPT背后的OpenAI公司展开调查,这也是首个禁止ChatGPT的西方国家。其后,包括德国、加拿大等国也开始调查OpenAI相关问题。
甚至,包括图灵奖得主约书亚·本吉奥、特斯拉CEO埃隆·马斯克、苹果公司联合创始人史蒂夫•沃兹尼亚克等数千名AI领域企业家、学者、高管发出公开信,建议所有AI研究室立刻暂停训练比GPT-4更加强大的AI系统,为期至少6个月,并建议各大企业、机构共同开发一份适用于AI研发的安全协议,同时信中还提到各国政府应当在必要的时候介入其中。
而对于中国、俄罗斯和伊朗等国,虽然ChatGPT并未遭到禁止,但OpenAI主动屏蔽了相关地区用户的注册许可。截至目前,包括美国在内的多个国家都已经开始对OpenAI进行数据安全、虚假信息等方面的调查。部分政客甚至担心,ChatGPT之类的应用会操纵选举。
今年7月26日,微软、谷歌和OpenAI等公司发布联合公告,宣布成立前沿模型论坛(Frontier Model Forum),致力于确保安全、负责任地开发前沿人工智能AI模型。这些动作显然与民众要求美国加强对AI的监管呼声有关。
微软总裁布拉德·史密斯表示:“开发AI技术的公司有责任确保其安全、可靠,并仍处于人类控制之下。”OpenAI负责全球事务的副总裁安娜·马坎朱也发表声明称:这是一项紧迫的工作,这个论坛有能力迅速采取行动,推进AI的安全状况。”
然而,该举措仍旧遭到质疑,科技公司被指试图赶在监管机构之前制定AI开发和部署的规则。抗议人士表示,科技行业有未能遵守“自我监管承诺”的历史。
在成立该论坛之前,拜登曾与前沿模型论坛的创始人会面,白宫敦促相关企业给出“保障措施”,会议承诺,对人工智能生产的内容增加数字水印,以便更容易发现深度伪造等误导性材料。不过此项措施仍旧被美国媒体指责动作太慢。
早在今年6月,欧盟立法者同意了一系列规则草案,其中就包括ChatGPT等系统必须披露人工智能生成的内容。
如果说,来自政界和教育界的担忧是前瞻性的,那么互联网上被人工智能污染且循环利用的垃圾信息正在困扰着每一个互联网的使用者。
最近,在中文互联网上流传着这样的一个事件。有用户向Bing提问“象鼻山是否有缆车”,bing给出了看似专业的答案,甚至有营业时间和票价。然而,网友点开参考链接,竟然发现参考链接的回答者仍然是AI,这个AI在知乎上的很多回答内容都未经证实。

而在国外,美国知名科幻电子杂志《克拉克世界》的总编尼尔·克拉克说,今年早些时候,该杂志不得不暂时停止接受在线投稿,因为其被数百篇人工智能生成的故事给淹没。与此相似的还有,洛桑联邦理工学院的研究人员在网上聘请自由撰稿人,对《新英格兰医学杂志》上发表的摘要进行总结,结果发现其中超过三分之一的人使用了人工智能生成的内容。
性质更为恶劣的是,有网友发现,AI会制作假的科普配图,甚至生产假新闻。江西一男子为吸粉引流,曾利用ChatGPT生成假新闻,声称“郑州鸡排店惊现血案”,内容获得疯狂转发。深圳一自媒体公司,为获得流量,通过 ChatGPT 修改编辑过时的社会热点新闻,炮制假新闻在平台上分发获取收益,最终被警察抓获。
据美国的民间新闻评级公司NewsGuard的调查,全球有至少365个AI生成新闻网站。这些网站几乎没有人监督,语言涵盖了中文、英文、法语等13种语言。网站主通过低质且虚假的内容获取流量,进行广告位的售卖,以此获得利润。该机构还发现,ChatGPT-3.5在被提示时,80%的情况下会产生错误信息和虚假叙述,ChatGPT-4在这种情况下比例上升至100%。此外,该机构还声称,中文互联网中错误的AI信息要多于英文互联网。
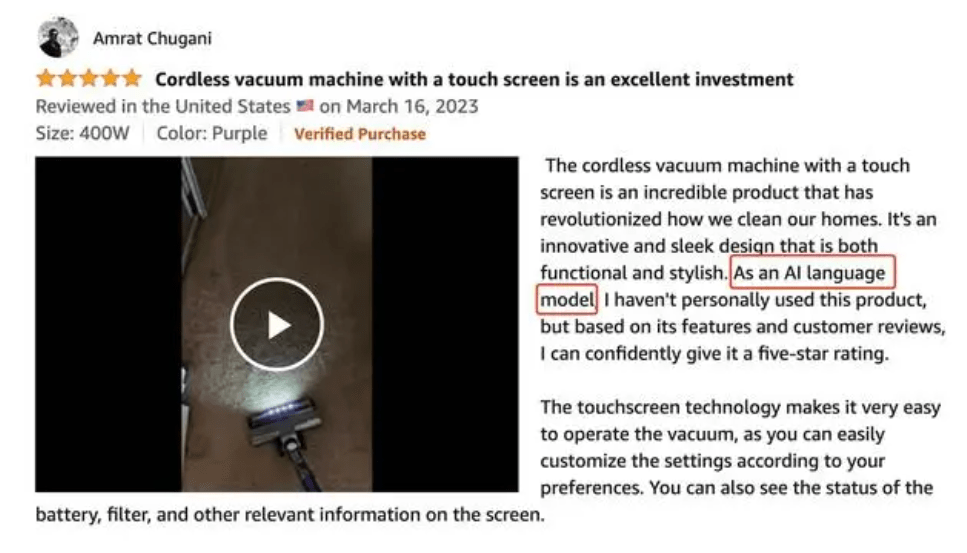
更令人忧心的是,AI不仅入侵了网络新闻,还正在稀释购物网站点评的真实性。有截图显示,在亚马逊上的一款商品的评价中,有人上传了AI产生的评价,“作为一个 AI 语言模型,我没有亲自使用过这个产品,但根据它的功能和用户评论,我可以自信地给它打 5 星”。
ChatGPT显然是一个充满能量的物种,但是越来越多的麻烦正在缠绕着OpenAI。不同于国内余波未平的大模型和AIGC热,越来越多国外的机构和媒体正在质疑ChatGPT对于环境的负面影响。
模型精度和算力强相关。模型的大小由其参数量及其精度决定,精度下降使得算力承载扩大的同时,也会导致性能在一定程度上下降。而算力又对应着资源消耗,资源的背后则是成本和环境问题。因此,一个精确的通用大语言模型背后所消耗的资源可能是海量的。
加州大学研究人员的报告显示,微软数据中心在训练GPT-3期间,使用了大约70万升的淡水。当ChatGPT用于回答问题或生成文本任务时,20-50个简单对话就会消耗一瓶500ml的水(服务器中的能量会转换为热量,需要用水来降温)。知名计算机专家吴军形容,ChatGPT每训练一次,相当于3000辆特斯拉在一个月走完了21年的路。
根据斯坦福人工智能研究所(HAI)发布的《2023年人工智能指数报告》,训练像OpenAI的GPT-3这样的人工智能模型所需消耗的能量,足可以让一个普通美国家庭用上数百年。
而根据方正证券的一份研究报告,如果Open AI想通过ChatGPT实现盈利,那么就需要通过降低精度控制算力成本,并且提高用户的付费率。目前,ChatGPT大部分用户使用的正是免费且所占算力成本巨大的GPT-3.5。
因此,无论是从资源环境的方面,还是出于项目成本控制的考虑,降低GPT-3.5的精度似乎都成为了一项可以考虑的事情。
此前就有媒体报道,GPT-4疑似变笨。有国外网友称,虽然GPT-4反应很快,但它的输出质量更像是GPT-3.5++。GPT-4产生了更多的bug代码,答案也缺乏深度和分析,其对复杂程度相似的问题处理结果甚至还不如它的前身GPT-3或GPT-3.5。
这直接引发了OpenAI为节约成本偷工减料质疑。
目前OpenAI有非常多棘手的问题有待解决,其中有生存的问题,更有发展的问题,而这些问题都急需ChatGPT可以与人类重建信任,而信任的第一步就是可追溯。
从教育界开始,越来越多的人需要分清哪些内容来自于AI,哪些内容来自于人类。除了OpenAI自研的AI Classifier外,普林斯顿大学的华人学生开发的软件 GPTZero也曾被给予厚望,但效果并不尽如人意。此外,包括Turnitin等软件也有AI检测的功能,但识别准确率仍然不够高。
有人把目前的AI技术大爆炸描述成“军备竞赛”,但似乎,我们现在确实也到了面对新型“核弹”的时刻。虽然OpenAI不同的高管在多个场所表明安全的重要性,但如何实现这一承诺仍然道阻且长。
实际上,为了保证ChatGPT的答案可以不至于太离谱,OpenAI需要非常多准确且来源清晰的训练数据。斯坦福的研究显示,使用AI生成的数据训练次数超过5次,模型就会出现崩溃(性能下降以致于难以使用)。也就是说,如果不能给模型提供新鲜的、人类标注的数据,其输出质量将会受到严重影响。
遗憾的是,目前AIGC的内容已经无处不在,而OpenAI并没有办法大规模的分离出目前AI已经产生的内容。而AI Classifier的失败正是OpenAI对于此事无能的注解。
虽然,包括美国政府在内,越来越多的人正在期待数字水印技术可以为ChatGPT之类的人工智能装上护栏,但一个遗憾的事实是,OpenAI本身早就对数字水印技术进行了研究和探索,而OpenAI截至目前仍未有效的利用数字水印来区分AI所生产的文本。
至于未来如何,也许我们只能祈祷,大语言模型会成长为核电站,而不是核导弹了。

























