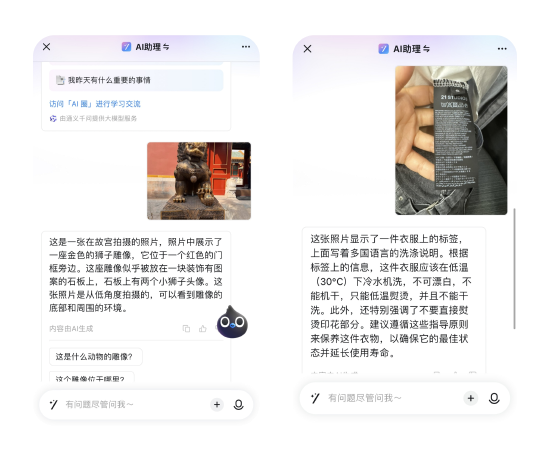
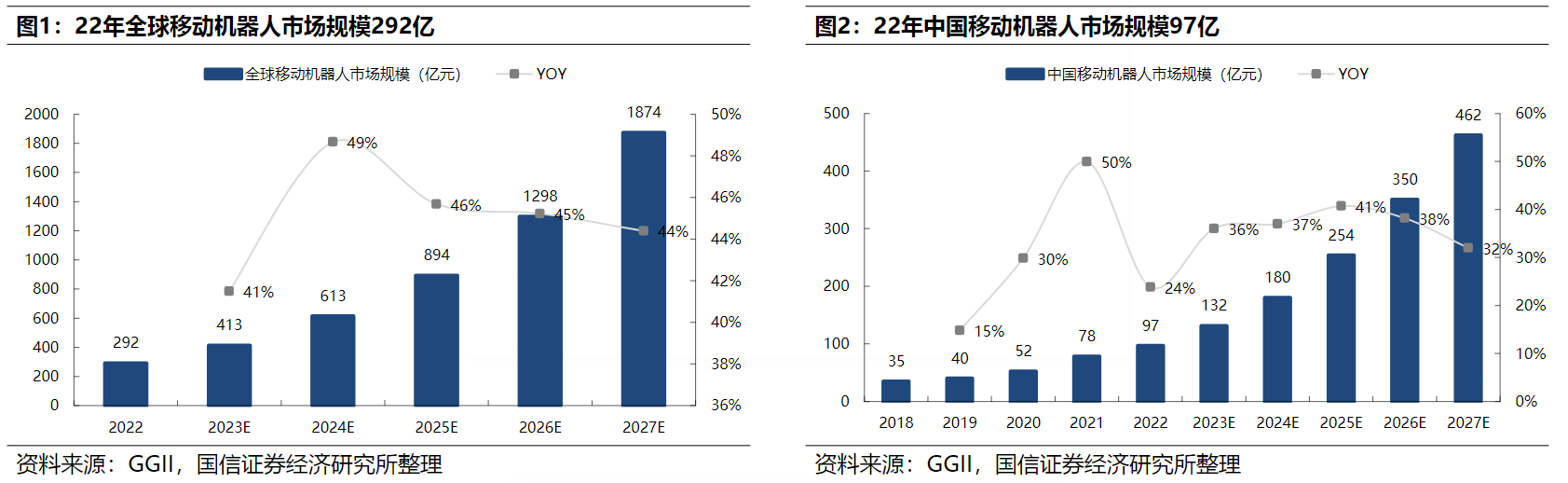
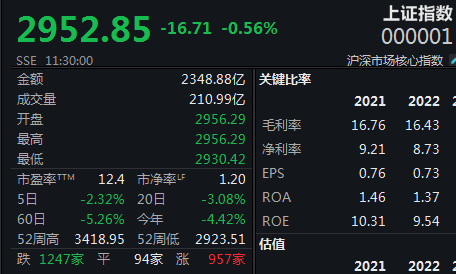
随着人工智能技术的飞速发展,多模态预训练成为了新的研究热点。它将文本和视觉数据相结合,利用深度学习算法进行训练,实现了文本和视觉生成的卓越能力。本文将介绍多模态预训练的原理和应用,揭示其在各个领域中的潜力。
第一部分:多模态预训练的原理
深度学习与预训练模型
深度学习是一种人工智能技术,通过模仿人脑的神经网络结构,实现对大规模数据的学习和分析能力。而预训练模型则是指在大规模数据上进行训练,以得到在特定任务中有用的模式和特征。
多模态预训练的概念
多模态预训练结合了自然语言处理和计算机视觉的技术,使得模型能够同时处理文本和图像数据,从而更好地理解和生成多媒体内容。
多模态预训练的网络结构
多模态预训练模型通常采用Transformer等架构,通过自监督学习的方式对文本和视觉数据进行联合建模。这种网络结构能够学习到文本和图像之间的语义关联,使得模型在生成任务中表现出色。
第二部分:多模态预训练的应用领域
图像描述生成
多模态预训练模型可以从一张图片中学习到其中的视觉特征,并与文本数据进行融合,生成准确且富有表现力的图像描述。这项技术在图像注释、图像搜索等领域有着广泛的应用前景。
视觉问答
多模态预训练模型能够理解图像中的内容,并根据问题生成准确的回答。这项技术在智能助理、教育培训等领域具有潜在的应用价值,可以提供更智能化的人机交互体验。
文本翻译与生成
多模态预训练模型能够将源语言的文本信息和目标语言的图像信息进行联合建模,实现更准确和流畅的翻译效果。同时,在文本生成领域,多模态预训练模型也可以生成更具表现力和多样性的文本内容。
第三部分:多模态预训练的挑战与未来发展
数据集和规模
多模态预训练模型受限于大规模数据集的获取和标注,尤其是同时包含文本和图像的数据集。未来的研究需要解决这一问题,构建更丰富和多样化的数据集。
模型的可解释性
多模态预训练模型在生成任务中通常表现出色,但其生成的结果无法直接解释。为了提升模型的可靠性和可解释性,需进一步探索如何让模型产生可解释的结果。
应用领域的扩展
目前多模态预训练技术主要集中在图像和文本的组合上,未来可以将其扩展到音频、视频等多种模态的组合,以满足更广泛的应用需求。
总之,多模态预训练的出现为文本和视觉数据的处理和生成带来了重大的突破。它通过深度学习的方法,将文本和图像之间的关联性进行了有效建模,为图像描述、视觉问答、文本翻译与生成等领域的应用提供了新的思路和技术支持。随着研究的不断深入,多模态预训练必将在更多的领域中展现其巨大的潜力,并为人们的生活带来更多的便利和智能化体验。