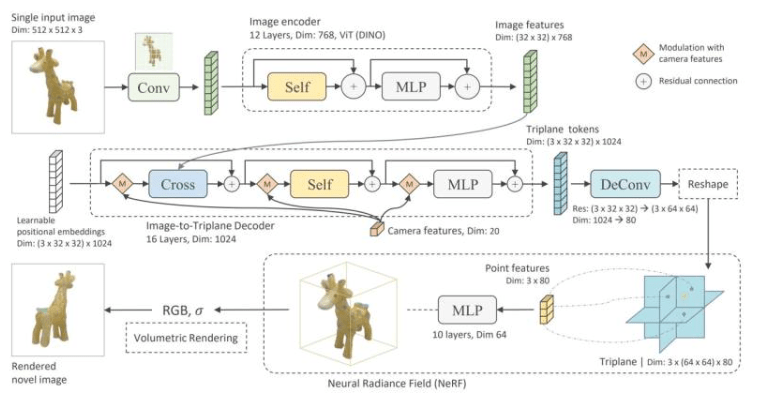
在人工智能(AI)领域,训练数据是培养和训练AI模型的关键。高质量的训练数据对于AI算法的准确性和性能至关重要。本文将为您介绍如何收集和准备AI模型的训练数据,以确保模型的质量和效果。
一、收集训练数据的方法
1.数据来源多样化:收集来自不同渠道和来源的数据,包括开放数据集、传感器数据、社交媒体数据等。多样化的数据来源可以提供更全面和丰富的信息,帮助模型更好地理解和学习数据特征。
2.众包和协作:利用众包平台或与其他研究人员、机构合作,通过众包的方式收集大规模的训练数据。同时,与专业人士合作,进行数据标注和质量控制,确保数据的准确性和可靠性。
3.数据爬取和抓取:通过网络爬虫或API接口,获取互联网上的相关数据。这种方法可以快速获取大量数据,但需要注意合法性和隐私保护,遵守相关法律和规定。
二、准备训练数据的步骤
1.数据清洗和预处理:对收集到的数据进行清洗和预处理,包括去除噪声、处理缺失值、处理异常值等。这样可以提高数据的质量和准确性,减少对模型的干扰。
2.数据标注和注释:对于需要标注和注释的数据,可以利用人工或半自动的方式进行。通过标注和注释,可以为模型提供准确的标签和目标值,帮助模型学习和预测。
3.数据划分和集成:将数据划分为训练集、验证集和测试集,以便评估模型的性能和泛化能力。同时,可以集成不同来源和类型的数据,增加数据的多样性和覆盖度。
4.数据增强和扩充:通过数据增强技术,如旋转、翻转、缩放等,生成更多的训练样本。这样可以增加数据的多样性和丰富性,提高模型的泛化能力和鲁棒性。
三、注意事项和挑战
1.数据隐私和安全:在收集和处理训练数据时,需要注意保护数据的隐私和安全。遵循相关法律和规定,确保数据的合法使用和保密性。
2.数据偏见和不平衡:收集的数据可能存在偏见和不平衡的问题,导致模型的性能下降。在数据收集和准备过程中,需要注意避免偏见和不平衡,保证数据的代表性和平衡性。
3.数据质量控制:建立有效的数据质量控制机制,及时发现和纠正数据中的错误和问题。确保数据的准确性和可靠性,提高模型的性能和效果。
4.数据量和资源需求:大规模的训练数据需要大量的存储和计算资源。在收集和准备训练数据时,需要充分考虑资源的需求和限制。
收集和准备AI模型的训练数据是确保模型质量和效果的关键步骤。通过多样化的数据来源、数据清洗和预处理、数据标注和注释,以及数据增强和扩充等方法,可以获得高质量的训练数据。然而,在数据收集和准备过程中,需要注意数据的隐私和安全、偏见和不平衡、数据质量控制等问题。只有通过合理的方法和注意事项,才能为AI模型提供高质量的训练数据,提高模型的性能和效果。