前言:在程序出现bug的时候,最好的解决办法就是通过 GDB 调试程序,然后找到程序出现问题的地方。比如程序出现 段错误(内存地址不合法)时,就可以通过 GDB 找到程序哪里访问了不合法的内存地址而导致的。 本文不是介绍GDB不是使用方式,而是大概介绍 GDB 的实现原理,当然是 GDB 是一个庞大而复杂的项目,不可能只通过一篇文章就能解释清楚,所以本文主要是介绍 GDB 使用的核心的技术 - ptrace。
long ptrace(enum __ptrace_request request, pid_t pid, void *addr, void *data);
#include <sys/ptrace.h>
#include <sys/types.h>
#include <sys/wAIt.h>
#include <unistd.h>
#include <sys/user.h>
#include <stdio.h>
int main()
{ pid_t child;
struct user_regs_struct regs;
child = fork(); // 创建一个子进程
if(child == 0) { // 子进程
ptrace(PTRACE_TRACEME, 0, NULL, NULL); // 表示当前进程进入被追踪状态
execl("/bin/ls", "ls", NULL); // 执行 `/bin/ls` 程序
}
else { // 父进程
wait(NULL); // 等待子进程发送一个 SIGCHLD 信号
ptrace(PTRACE_GETREGS, child, NULL, ®s); // 获取子进程的各个寄存器的值
printf("Register: rdi[%ld], rsi[%ld], rdx[%ld], rax[%ld], orig_rax[%ld]n",
regs.rdi, regs.rsi, regs.rdx,regs.rax, regs.orig_rax); // 打印寄存器的值
ptrace(PTRACE_CONT, child, NULL, NULL); // 继续运行子进程
sleep(1);
}
return 0;
}
Register: rdi[0], rsi[0], rdx[0], rax[0], orig_rax[59]
ptrace ptrace.c
更多linux内核视频教程文档资料免费领取后台私信【内核】自行获取.
Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈-学习视频教程-腾讯课堂
本文使用的 Linux 2.4.16 版本的内核
asmlinkage int sys_ptrace(long request, long pid, long addr, long data)
{
struct task_struct *child;
struct user *dummy = NULL;
int i, ret;
...
read_lock(&tasklist_lock);
child = find_task_by_pid(pid); // 获取 pid 对应的进程 task_struct 对象
if (child)
get_task_struct(child);
read_unlock(&tasklist_lock);
if (!child)
goto out;
if (request == PTRACE_ATTACH) {
ret = ptrace_attach(child);
goto out_tsk;
}
...
switch (request) {
case PTRACE_PEEKTEXT:
case PTRACE_PEEKDATA:
...
case PTRACE_PEEKUSR:
...
case PTRACE_POKETEXT:
case PTRACE_POKEDATA:
...
case PTRACE_POKEUSR:
...
case PTRACE_SYSCALL:
case PTRACE_CONT:
...
case PTRACE_KILL:
...
case PTRACE_SINGLESTEP:
...
case PTRACE_DETACH:
...
}
out_tsk:
free_task_struct(child);
out:
unlock_kernel();
return ret;
}
#define PTRACE_TRACEME 0
#define PTRACE_PEEKTEXT 1
#define PTRACE_PEEKDATA 2
#define PTRACE_PEEKUSR 3
#define PTRACE_POKETEXT 4
#define PTRACE_POKEDATA 5
#define PTRACE_POKEUSR 6
#define PTRACE_CONT 7
#define PTRACE_KILL 8
#define PTRACE_SINGLESTEP 9
#define PTRACE_ATTACH 0x10
#define PTRACE_DETACH 0x11
#define PTRACE_SYSCALL 24
#define PTRACE_GETREGS 12
#define PTRACE_SETREGS 13
#define PTRACE_GETFPREGS 14
#define PTRACE_SETFPREGS 15
#define PTRACE_GETFPXREGS 18
#define PTRACE_SETFPXREGS 19
#define PTRACE_SETOPTIONS 21
asmlinkage int sys_ptrace(long request, long pid, long addr, long data)
{
...
if (request == PTRACE_TRACEME) {
if (current->ptrace & PT_PTRACED)
goto out;
current->ptrace |= PT_PTRACED; // 标志 PTRACE 状态
ret = 0;
goto out;
}
...
}
static int load_elf_binary(struct linux_binprm * bprm, struct pt_regs * regs)
{
...
if (current->ptrace & PT_PTRACED)
send_sig(SIGTRAP, current, 0);
...
}
int do_signal(struct pt_regs *regs, sigset_t *oldset)
{
for (;;) {
unsigned long signr;
spin_lock_irq(¤t->sigmask_lock);
signr = dequeue_signal(¤t->blocked, &info);
spin_unlock_irq(¤t->sigmask_lock);
// 如果进程被标记为 PTRACE 状态
if ((current->ptrace & PT_PTRACED) && signr != SIGKILL) {
/* 让调试器运行 */
current->exit_code = signr;
current->state = TASK_STOPPED; // 让自己进入停止运行状态
notify_parent(current, SIGCHLD); // 发送 SIGCHLD 信号给父进程
schedule(); // 让出CPU的执行权限
...
}
}
}
asmlinkage int sys_ptrace(long request, long pid, long addr, long data)
{
...
switch (request) {
case PTRACE_PEEKTEXT:
case PTRACE_PEEKDATA: {
unsigned long tmp;
int copied;
copied = access_process_vm(child, addr, &tmp, sizeof(tmp), 0);
ret = -EIO;
if (copied != sizeof(tmp))
break;
ret = put_user(tmp, (unsigned long *)data);
break;
}
...
}
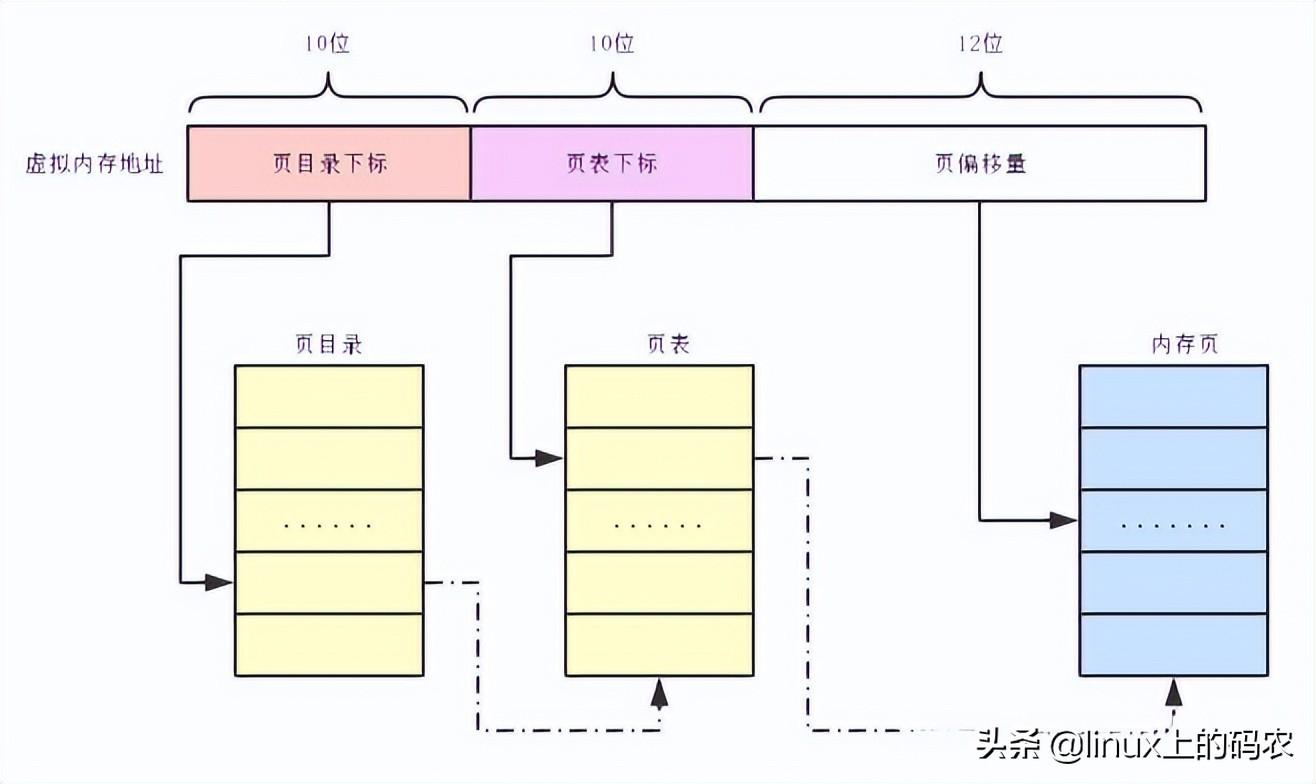
struct mm_struct {
...
pgd_t *pgd; /* 页目录指针 */
...
}
asmlinkage int sys_ptrace(long request, long pid, long addr, long data)
{
...
switch (request) {
case PTRACE_SINGLESTEP: { /* set the trap flag. */
long tmp;
...
tmp = get_stack_long(child, EFL_OFFSET) | TRAP_FLAG;
put_stack_long(child, EFL_OFFSET, tmp);
child->exit_code = data;
/* give it a chance to run. */
wake_up_process(child);
ret = 0;
break;
}
...
}
tmp = get_stack_long(child, EFL_OFFSET) | TRAP_FLAG;
put_stack_long(child, EFL_OFFSET, tmp);