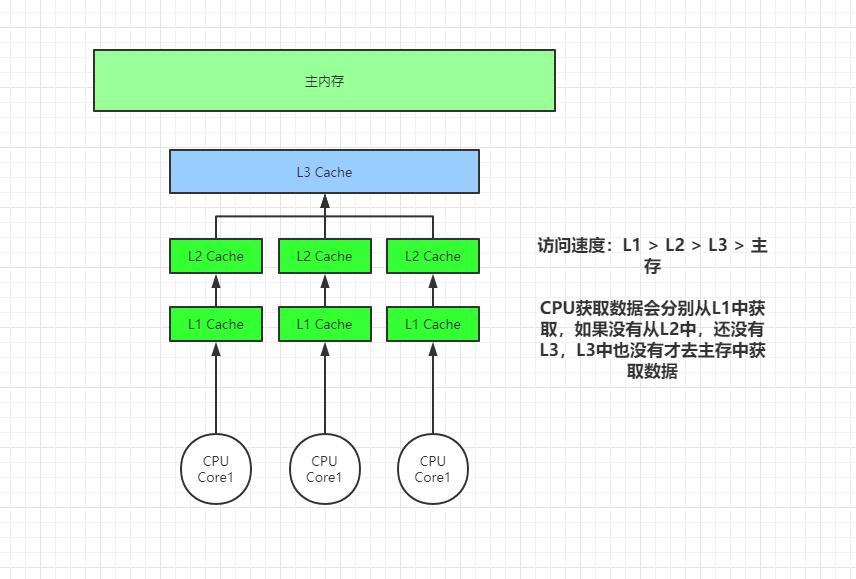
前面的文章里,我们聊到了 CPU 的高速缓存机制。由于 CPU 和内存的速度差距太大,现代计算机会在两者之间插入一块高速缓存。
然而,CPU 缓存总能提高程序性能吗,有没有什么情况 CPU 缓存反而会成为程序的性能瓶颈?这就是我们今天要讨论的伪共享(False Sharing)。
学习路线图:
由于 CPU 和内存的速度差距太大,为了拉平两者的速度差,现代计算机会在两者之间插入一块速度比内存更快的高速缓存,CPU 缓存是分级的,有 L1 / L2 / L3 三级缓存。
由于单核 CPU 的性能遇到瓶颈(主频与功耗的矛盾),芯片厂商开始在 CPU 芯片里集成多个 CPU 核心,每个核心有各自的 L1 / L2 缓存。其中 L1 / L2 缓存是核心独占的,而 L3 缓存是多核心共享的。为了保证同一份数据在内存和多个缓存副本中的一致性,现代 CPU 会使用 MESI 等缓存一致性协议保证系统的数据一致性。
缓存一致性问题
MESI 协议
现在,我们的问题是:CPU 缓存总能够提高程序性能吗?
基于局部性原理的应用,CPU Cache 在读取内存数据时,每次不会只读一个字或一个字节,而是一块块地读取,每一小块数据也叫 CPU 缓存行(CPU Cache Line)。
在并行场景中,当多个处理器核心修改同一个缓存行变量时,有 2 种情况:
事实上,多个核心修改同一个变量时,使用 MESI 机制维护数据一致性是必要且合理的。但是多个核心分别访问不同变量时,MESI 机制却会出现不符合预期的性能问题。
在高并发的场景下,核心的写入操作就会交替地把其它核心的 Cache Line 置为失效,强制对方刷新缓存数据,导致缓存行失去作用,甚至性能比串行计算还要低。
这个问题我们就称为伪共享问题。
出现伪共享问题时,有可能出现程序并行执行的耗时比串行执行的耗时还要长。耗时排序:并行执行有伪共享 > 串行执行 > 并行执行无伪共享。
伪共享性能测试
—— 数据引用自 Github · falseSharing[1] —— MJjAInam 著
那么,怎么解决伪共享问题呢?其实方法很简单 —— 缓存行填充:

下面,我们以 JAVA 为例介绍如何做缓存行填充,在不同 Java 版本上填充的实现方式不同:
通过填充 long 变量填充 Padding。网上有的资料会将前置填充和后置填充放在同一个类中, 这是不对的。例如:
错误示例
public class Data {
long a1,a2,a3,a4,a5,a6,a7; // 前置填充
volatile int value;
long b1,b2,b3,b4,b5,b6,b7; // 后置填充
}
在 《对象的内存分为哪几个部分?》[2] 这篇文章中,我们分析 Java 对象的内存布局:其中我们提到:“其中,父类声明的实例字段会放在子类实例字段之前,而字段间的并不是按照源码中的声明顺序排列的,而是相同宽度的字段会分配在一起:引用类型 > long/double > int/float > short/char > byte/boolean。”
Java 对象内存布局
因此,上面的代码中,所有填充变量都变成前置填充了,并没有起到填充的效果:
实验验证
# 使用 JOL 工具输出对象内存布局:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 43 c1 00 f8 (01000011 11000001 00000000 11111000) (-134168253)
# 填充无效
12 4 int Data.value 0
16 8 long Data.a1 0
24 8 long Data.a2 0
32 8 long Data.a3 0
40 8 long Data.a4 0
48 8 long Data.a5 0
56 8 long Data.a6 0
64 8 long Data.a7 0
72 8 long Data.b1 0
80 8 long Data.b2 0
88 8 long Data.b3 0
96 8 long Data.b4 0
104 8 long Data.b5 0
112 8 long Data.b6 0
120 8 long Data.b7 0
Instance size: 128 bytes
正确的做法是利用父子类继承来做缓存行填充:
正确示例
public abstract class SuperPadding {
long a1,a2,a3,a4,a5,a6,a7; // 前置填充
}
public abstract class DataField extends SuperPadding {
volatile int value;
}
public class Data extends DataField {
long b1,b2,b3,b4,b5,b6,b7; // 后置填充
}
实验验证
# 使用 JOL 工具输出对象内存布局:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) bf c1 00 f8 (10111111 11000001 00000000 11111000) (-134168129)
12 4 (alignment/padding gap)
16 8 long SuperPadding.a1 0
24 8 long SuperPadding.a2 0
32 8 long SuperPadding.a3 0
40 8 long SuperPadding.a4 0
48 8 long SuperPadding.a5 0
56 8 long SuperPadding.a6 0
64 8 long SuperPadding.a7 0
72 4 int DataField.value 0
76 4 (alignment/padding gap)
80 8 long Data.b1 0
88 8 long Data.b2 0
96 8 long Data.b3 0
104 8 long Data.b4 0
112 8 long Data.b5 0
120 8 long Data.b6 0
128 8 long Data.b7 0
Instance size: 136 bytes
缓存行填充
例如,Java 并发框架 Disruptor 就是使用继承的方式实现:
Disruptor · RingBuffer.java[3]
abstract class RingBufferPad {
protected long p1, p2, p3, p4, p5, p6, p7;
}
abstract class RingBufferFields<E> extends RingBufferPad {
// 前置填充:父类的 7 个 long 变量
...
private final long indexMask;
private final Object[] entries;
protected final int bufferSize;
protected final Sequencer sequencer;
...
// 后置填充:子类的 7 个 long 变量
}
public final class RingBuffer<E> extends RingBufferFields<E> implements Cursored, EventSequencer<E>, EventSink<E> {
protected long p1, p2, p3, p4, p5, p6, p7;
...
}
@sun.misc.Contended 注解是 JDK 1.8 新增的注解。如果 JVM 开启字节填充功能 -XX:-RestrictContended ,在运行时就会在变量或类前后填充 Padding。Java 8 Thread.java
/** The current seed for a ThreadLocalRandom */
@sun.misc.Contended("tlr")
long threadLocalRandomSeed;
/** Probe hash value; nonzero if threadLocalRandomSeed initialized */
@sun.misc.Contended("tlr")
int threadLocalRandomProbe;
/** Secondary seed isolated from public ThreadLocalRandom sequence */
@sun.misc.Contended("tlr")
int threadLocalRandomSecondarySeed;
Java 8 ConcurrentHashMap.java
@sun.misc.Contended static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}
1、在并行场景中,当多个处理器核心修改同一个缓存行变量时,即使两个变量没有逻辑上的数据依赖性,CPU 缓存一致性机制也会使得两个核心中的缓存交替地失效,拉低程序的性能。这种现象叫伪共享问题;
2、解决伪共享问题的方法是缓冲行填充:在变量前后填充额外的占位变量,避免变量和其他分组的被填充到同一个缓存行中,从而规避伪共享问题。