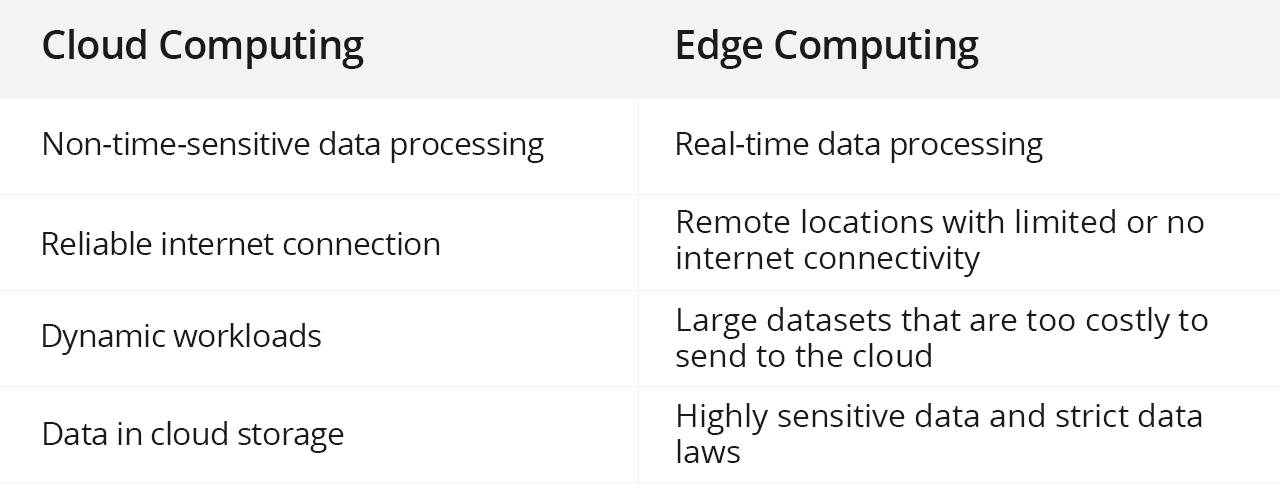
图像分割是计算机视觉领域的重要任务,其目标是将一幅图像划分成具有语义信息的不同区域。在图像分割方法中,基于传统的卷积神经网络(CNN)的方法具有广泛的应用。本文将介绍基于传统的卷积神经网络的图像分割方法的基本原理、常见模型和发展趋势。
基于传统的卷积神经网络的图像分割方法主要包括以下步骤:
数据预处理:首先,需要对输入的图像进行预处理,例如调整大小、归一化、裁剪等。这一步旨在提取图像中的有用信息,并为后续的分割任务做准备。
特征提取:接下来,使用卷积层、池化层等操作来提取图像中的特征。卷积层可以有效地捕捉图像的空间结构信息,而池化层则用于减少特征的维度并保留关键信息。
上采样与下采样:为了获得更高分辨率的分割结果,通常会使用上采样和下采样的操作。下采样通过池化或步长操作降低图像的分辨率,以便更好地捕捉全局特征。而上采样则通过反卷积或插值等方法将特征恢复到原始分辨率。
分类与分割:在特征提取后,可以使用全连接层或卷积层进行分类任务,也可以使用卷积层输出的特征图进行像素级别的分割任务。分割任务通常使用像素分类或像素回归的方式,对每个像素进行标记或预测。
基于传统的卷积神经网络的图像分割方法有许多经典的模型,其中比较常见的有:
U.NET:U-Net是一种经典的全卷积网络,其结构由对称的编码器和解码器组成。编码器用于特征提取和下采样,而解码器用于上采样和重建分割结果。U-Net的结构设计使得它在医学图像分割等领域得到广泛应用。
FCN:全卷积网络(FullyConvolutionalNetwork,FCN)是一种将全连接层替换为卷积层的网络结构。FCN通过多个卷积层和上采样操作来实现像素级别的分割任务,它能够保留图像的空间结构信息,并产生高分辨率的分割结果。
SegNet:SegNet是一种基于编码器-解码器结构的图像分割模型。它使用编码器来提取特征并进行下采样,然后使用解码器进行上采样和分割恢复。SegNet通过使用跳跃连接来保留更多的细节信息,从而提高分割的准确性。
基于传统的卷积神经网络的图像分割方法在近年来得到了长足的发展,并呈现出以下趋势:
结合注意力机制:注意力机制是一种可以自动选择感兴趣区域的技术。将注意力机制引入传统的卷积神经网络中,可以帮助模型更好地关注重要的信息,提高分割的准确性。
多尺度特征融合:多尺度特征融合是一种通过结合不同层次的特征信息来提高分割性能的方法。通过将具有不同感受野的特征进行融合,可以使模型对不同尺度的目标都有较好的适应性。
弱监督学习:传统的卷积神经网络通常需要大量的标注数据进行训练,但标注数据往往难以获取且耗时。因此,弱监督学习成为一种重要的研究方向,旨在通过较少的标注信息来训练高性能的分割模型。
综上所述,基于传统的卷积神经网络的图像分割方法在计算机视觉领域发挥着重要作用。本文介绍了基于传统的卷积神经网络的图像分割方法的基本原理、常见模型和发展趋势。随着技术的不断进步和研究的深入,我们可以期待基于传统的卷积神经网络的图像分割方法在各个领域得到更广泛的应用,并为图像分割任务带来更好的性能和效果。