作者:LX
一、 环境搭建
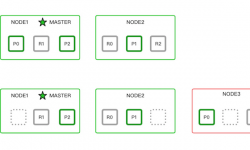
1、 启动Spark集群服务
1)启动Spark集群
2)子节点加入集群
3)查看是否加入成功
2、启动Elasticsearch数据库
1)可以启动自己安装的Elasticsearch数据库
2)也可以启动iServerDataStore,默认会启动一个Elasticsearch数据库
二、 创建流处理模型
流模型的创建有两种方式:
(一) 流处理模型编辑器
1、使用浏览器访问http://localhost:8090/iserver/manager,登陆SuperMapiServer管理页面,点击【服务】-> 【概述】 ->【配置流数据服务】。

2、添加接收器
1)接收器介绍
接收器类型(9种接收器):
-
-
SocketReceiver:Socket客户端接收器,接收Socket消息的节点。
-
MultiSocketReceiver:Socket多客户端接收器,同时接收多个Socket消息的节点,接收的消息内容必须是相同的。
-
SocketServerReceiver:Socket服务接收器,Socket服务端接收节点,用于作为服务端接收其他Socket客户的发送的消息。
-
WebSocketReceiver:WebSocket接收器,接收WebSocket消息的节点。
-
TextFileReceiver:文本文件接收器,监控指定目录,读取新增文件的内容。
-
SingleTextFileReceiver:单文本文件接收器,根据设置读取监控文件的内容,支持读取Json、GeoJSON和CSV格式的文件。
-
KafkaReceiver:Kafka接收器,接收kafka消息的节点。
-
HttpReceiver:Http接收器,接收HTTP 的消息节点,目前只支持HTTP的Get方法。
-
JMSReceiver:JMS接收器,接收JMS标准协议消息的节点,用于接收ActiveMQ、RabbitMQ等消息中间件的消息
2)添加接收器
本文以读取iServer示范数据flights.csv文件为例,所以需要将“接收器”中“单文本接收器”,用鼠标拖到“节点编辑器”中。如下图所示:
3)编辑节点信息
PS:
i.文件路径必须写绝对路径,不能写相对路径。
ii.metadata ,是接收消息的元数据,用于描述消息的格式定义。需指定以下信息:
title:元数据的名称,用于区分其他元数据。String类型
featureType:FeatureType类。接收消息转换的地理要素类型,如点POINT、线LINE、面REGION等。
epsg:int类型。元数据地理要素的投影EPSG编码。
fieldInfos:接收消息转换后的字段信息。需指定:
name:String类型。字段名称,为字段的唯一标识
source:String类型。字段在原始信息中的位置,决定了从原始信息中的什么位置去解析成为本字段的值。成为本字段的值。如果原始信息为CSV 格式,source值为 CSV 中的字段序号,如"source": "4" 代表了CSV 数据中的第5 个字段;如果原始数据为json 格式的,那么source 值为 json中键值对的键。
nType:FieldType类型。字段的类型,如:字符型TEXT、双精度浮点型DOUBLE、整型 INT等
本文元数据的配置如下:
根据CSV中字段内容:
T0000,121.465069,29.824944,1.49370399857E12,Lishe,Jiangbei,2017-09-1302:53:47
从“FieldInfo-0”到“FieldInfo-6”依次填写以下内容:
将鼠标放到“元数据”的“StreamingMetadata”标签上,可以看到上一步的详细配置信息,确认信息无误后,点击“检查并返回”按钮。

-
-
添加发送器
1)添加发送器
将“接收器”中的“Elasticsearch添加发送器”用鼠标拖到“节点编辑器”中,如下图所示:
2)编辑发送器节点信息
鼠标单击“节点编辑器”中的“Elasticsearch添加发送器”,添加如下信息:
4、连接发送器和接收器
拖拽“节点编辑器”中的“单文本文件接收器”右侧的绿色方块,将拖出的箭头指向“Elasticsearch添加发送器”(如下图),命名为“ESstreaming”,点击“发布”即可发布流处理模型。
(二)手动编写streaming文件
手动编写streaming文件相关的参数配置按照iServer帮助文档的“流处理模型配置参数说明”来进行编写,如下图:http://support.supermap.com.cn/DataWarehouse/WebDocHelp/iServer/index.htm

编写好的streaming文件如下:
{
"sparkParameter": {
"checkPointDir": "tmp",
"interval": 5000
},
"stream": {
"nodeDic": {
"CSVFileReader": {
"metadata": {
"epsg": 4326,
"fieldInfos": [
{
"name": "id",
"source": "0",
"nType": "TEXT"
},
{
"name": "x",
"source": "1",
"nType": "DOUBLE"
},
{
"name": "y",
"source": "2",
"nType": "DOUBLE"
},
{
"name": "z",
"source": "3",
"nType": "DOUBLE"
},
{
"name": "fromStation",
"source": "4",
"nType": "TEXT"
},
{
"name": "toStation",
"source": "5",
"nType": "TEXT"
},
{
"name": "datetime",
"source": "6",
"nType": "TEXT"
}
],
"dateTimeFormat": "yyyy-MM-ddHH:mm:ss",
"timeFieldName": "datetime",
"featureType": "POINT",
"title": "",
"idFieldName": "id"
},
"readInterva": 5000,
"rowsOneTime": 50,
"nextNodes": [
"EsAppendSender"
],
"reader": {
"className":"com.supermap.bdt.streaming.formatter.CSVFormatter",
"separator": ","
},
"filePath":"E:/supermap/iserver/912/supermap-iserver-9.1.2-win64-zip/samples/streamingmodels/readcsv/flights.csv",
"name": "CSVFileReader",
"prevNodes": [],
"className":"com.supermap.bdt.streaming.receiver.SingleTextFileReceiver",
"caption": "单文本文件接收器",
"description": null
},
"EsAppendSender": {
"className":"com.supermap.bdt.streaming.sender.EsAppendSender",
"caption": "Elasticsearch添加发送器",
"name": "EsAppendSender",
"nextNodes": [],
"prevNodes": [
"CSVFileReader"
],
"description": null,
"formatter": {
"className":"com.supermap.bdt.streaming.formatter.GeoJsonFormatter"
},
"url": "192.168.15.200:9200",
"queueName": "streamingdata",
"directoryPath": "streaming"
}
}
},
"version": 9000
}
三、发布流处理模型
对于用模型编辑器编辑的直接点击模型编辑器左上角的【发布】即可。
对于自己编写的streaming文件,在服务管理“首页”点击快速发布一个或一组服务,选择数据来源为"流处理模型",点击“下一步”;
指定服务名;选择配置信息来源,iServer提供了“配置信息”和“配置文件”两种方式。
配置信息:输入流处理模型中的全部内容
配置文件:输入后缀为.streaming 的流处理模型文件
是否启用Token,输入用于验证用户身份的Token(令牌)
点击“完成”按钮完成发布流程:
四、查看存储到ES的数据
发布流模型之后,ES数据库中能看到,创建索引成功
访问
http://localhost:9200/streamingdata/_search能看到,存储到ES中的数据