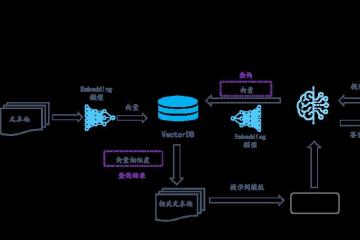
结构化数据是指可以表示成二维表格的数据,它有明确固定的字段和类型。而非结构化数据是指不能表示成二维表格的数据,例如:文本、图片、视频。抖音集团的产品矩阵每天都会产生海量的数据,其中结构化数据只占一小部分,大部分数据都是非结构化数据,业界通常认为非结构化数据会占全部数据的80%,但是对于抖音集团的业务形态,非结构化数据的占比只会更高。如何利用好这些非结构化数据对我们产品功能的完善,业务效果的提升都至关重要。

对非结构化数据的检索,以文本检索为例,传统上使用倒排索引,结合BM25,TF-IDF算法进行。这种方法有一些问题:
但是,现在有了深度学习,这产生了向量表示法,通过语言模型(如doc2vec、bert、LLM等),将文本转换为向量,从而将非结构化数据检索问题转化为向量近似检索问题。

向量检索是从一堆向量里找到和某个给定向量相似的一批向量,这里有三个问题需要明确:
通常受限于算力和响应时间,向量检索得到的是近似最优结果。常见的做法可以分为三类(三类也可结合进行):
抖音集团实践:

把向量检索的这些功能整合起来,就形成了向量数据库。
向量数据库的接口包括存储和检索向量。在功能划分上,包含存储、检索和分析。同时,作为在线服务,高可用、高性能和易用性都要具备。
完成这些后,一个具备核心向量检索功能的向量数据库就诞生了。这是一个存算一体的向量数据库。

当向量数据库推向业务场景时,我们发现,向量数据通常与结构化数据配合使用。例如,在将文档表示为向量的同时,还需要存储文档所属的部门,以方便在检索时进行权限过滤。这类需求可以抽象为使用与向量相关的结构化数据进行过滤。
业界对于这种过滤需求通常有两种解决方案:
业界通常结合两种方案,对检索任务进行编排,通过分析数据分布,来决定使用哪种方案。但是,随着数据量的增加,仍然可能会出现两种检索链路性能都不好的情况。
抖音集团实践:为解决这一问题,技术团队研发了DSL定向引擎,支持在检索过程中同时进行向量检索和DSL过滤(结构化过滤)。该引擎具有以下特点:
除了DSL定向引擎之外,我们还实现了子索引拆分、自适应精度调节和在线多路索引归并等多种定制化能力,打造了一整套向量检索工具库。

尽管功能逐渐完备,但我们向量数据库在初期是基于存算一体(存储和计算都在同一台机器上)的架构实现的,但在推广过程中,这种架构在使用上的一些问题也逐渐显现出来。比如在文档检索的场景中,一部分文档质量较高,需要高精度的召回,全局的文档作为补充,我们还需要区分部门内和部门外的文档列表来分开展示。这就要求在同一份向量数据上产生不同的可检索集、不同精度的索引以及不同的候选集。
在存算一体框架下,为了避免影响线上检索流程,我们使用少量线程异步地完成索引的重建流程。为适配数据分布的变化,这个索引还要定期重建。另外,在有些业务场景中,需要使用不同候选、不同精度的检索策略。如果为每种策略都建立一套索引,这会进一步放大索引构建的资源消耗,导致索引构建效率低、还会影响在线服务稳定性。
为此,我们逐步开展了存算分离的架构升级工作。
我们的存算分离架构,主要分成三个部分:
这种设计除了解决一份向量多个索引、支持多个场景的问题,还带来以下优势:

随着对时效性要求较高的业务接入,如何有效的提升新内容的检索效率,成为业务关注的重点。例如,在文档检索场景中,如果一篇文档刚写完,或者新授权了一个文档,用户需要等待半个小时才能检索到,这在业务上是无法接受的。为了解决这个问题,我们开发了流式更新能力。
加入了流式更新能力的索引构建过程分为两个部分。
随着抖音集团产品矩阵中的产品越来越多接入向量数据库,为每个业务都搭建一套存算分离的框架的成本较高,包括部署成本、运维成本和硬件成本。为解决这一问题,我们对存算分离的框架进行了进一步迭代。
①向量存储部分改造为向量存储集群。
②索引构建部分改造为索引构建集群。
③在线检索服务改造成支持多租户形式。
我们的资源调度模块可以自动化的去拉取数据开始索引构建任务,然后分发给在线多租户检索服务。改造后的在线检索服务支持多路索引,这能进一步降低在线服务的开销。在初期,为了保证服务稳定性,我们的在线检索服务编排是手动进行的。

随着业务增长,索引体积越来越大,为了保证多租户服务的稳定性。优化手动编排,人工选择集群不合理等问题。我们开发了自动化调度框架。
对在线检索服务编排的改造,主要采用slot化的方式。一个slot是索引的一个最小调度单元。通过索引元信息管理调度服务会根据在线检索服务配额和实时调用流量,自动调入调出slot。
为了配合自动化调度方案的上线,我们开发了很多辅助模块。例如,索引的流量感知模块,用于为调度服务提供信息,以尽快响应整个索引的流量变化。再比如索引配额管理系统,避免有的索引流量突增,影响整个在线检索集群的稳定性。
其中一个关键的模块是索引的精确计价系统。为了降低整体在线服务的计算成本,我们会将一些小内存的、低请求量的索引调度到同一个实例上。此时,如何统计和分摊成本就很关键了。我们实现了一个精确到时钟周期的开销监控,以进行服务的成本统计和分摊。

随着大语言模型的浪潮兴起,向量数据库的商业价值也慢慢凸显出来。我们决定在火山引擎上线我们的云原生向量数据库,提供和抖音集团内部向量数据库完全一致的服务,也会把内部探索和优化的成果同步到这个产品上。
它整体的产品结构如下图所示。整个产品基于火山引擎的云基础设施,提供经过我们深度打磨和优化的各个引擎,提供从多模态数据写入,到向量生成,再到在线检索,以及上线后的弹性调度和监控的一整套全链路解决方案。

用户接入时,通过我们的多语言SDK或http API写入自己的非结构化数据。然后,使用查询分析工具对数据进行管理和分析。进行简单配置后,即可自动化调度。从非结构化数据到向量生产的pipeline,都通过平台自动化调度实现。数据写入完成后,还支持在索引上线前进行自动调参,上线后进行流式更新,以及持续的自动调参以优化整体在线检索效果和资源成本。在在线检索阶段,支持整体服务的按需自适应弹性调度。从数据写入到在线检索的各个阶段,有全链路的监控和告警,以保证在线服务的稳定性。基于这套产品,我们预期会在大语言模型的智能问答、智能搜索、智能推荐广告、版权去重等场景下展开广泛应用。
这套云原生向量数据库有以下几个关键优势。

介绍完我们在云原生向量数据库上的技术和优势后,这一节对向量数据库做一些展望。
在大语言模型中,prompt是给大语言模型的输入。prompt的信息含量会影响最终回答的质量。然而,由于算法原理和计算能力的限制,prompt的长度是有限制的。无论是多轮调校,还是个性化问答的感知,还是特定领域的知识灌入,都需要更长的prompt。其次,由于训练样本的限制,大语言模型的时效性存在缺陷,只能知道训练数据截止时输入的信息,对于需要时效性回答的场景需要支持手段。对于这个问题,向量数据库可以在一定程度上解决。


大语言模型除了prompt长度限制外,另一个突出问题是数据安全问题。例如,支付行业建议大家在支付场景谨慎使用ChatGPT。而在互联网行业,很多公司也禁用了chatGPT,这都是出于安全角度考虑。
目前,在安全方面有两个关注点:
第一,用户的提问会被记录下来,这可能导致问题被泄露。
第二,A用户的提问可能被作为训练数据训练模型,导致其他用户B在使用时获得A用户提问时提供的隐私信息。这些问题预期可以通过控制问答数据的使用方式来解决。
但是,另一类问题从大语言模型的机制上就难以解决。大语言模型中包含的信息越多,回答质量就越好。理论上,我们在训练大语言模型的时候,或者优化它的时候,希望它具有全局所有的信息。然而,回归到业务场景,企业内部可能会有密级比较高的文档,或者说不同人对信息的权限是不一样的。如果大语言模型拥有了全局的信息,也就包含了高密级的信息,那么没有权限的用户就可能通过大语言模型的问答来获取自己权限以外的信息。使用向量数据库后,这一问题就可以大大缓解。我们可以通过向量数据库的管理机制,制定分层权限的知识库体系。这样,每个用户在提问时,只能从自己有权限的知识库中检索信息,并将检索到的信息作为context来优化当前这轮回答。

最后,基于向量数据库在非结构化数据检索方面的能力,我们甚至整个行业都认为,向量数据库将成为整个大模型生态的基础设施,支撑大模型在业界的推广和应用。