NeRF 大家都很熟悉了,但是你听说过 LERF 吗?本文中,来自 UC 伯克利的研究者将语言嵌入到 NeRF 中,并在 3D 场景中实现灵活的自然语言查询。
NeRF(Neural Radiance Fields)又称神经辐射场,自从被提出以来,火速成为最为热门的研究领域之一,效果非常惊艳。然而,NeRF 的直接输出只是一个彩色的密度场,对研究者来说可用信息很少,缺乏上下文就是需要面对的问题之一,其效果是直接影响了与 3D 场景交互界面的构建。
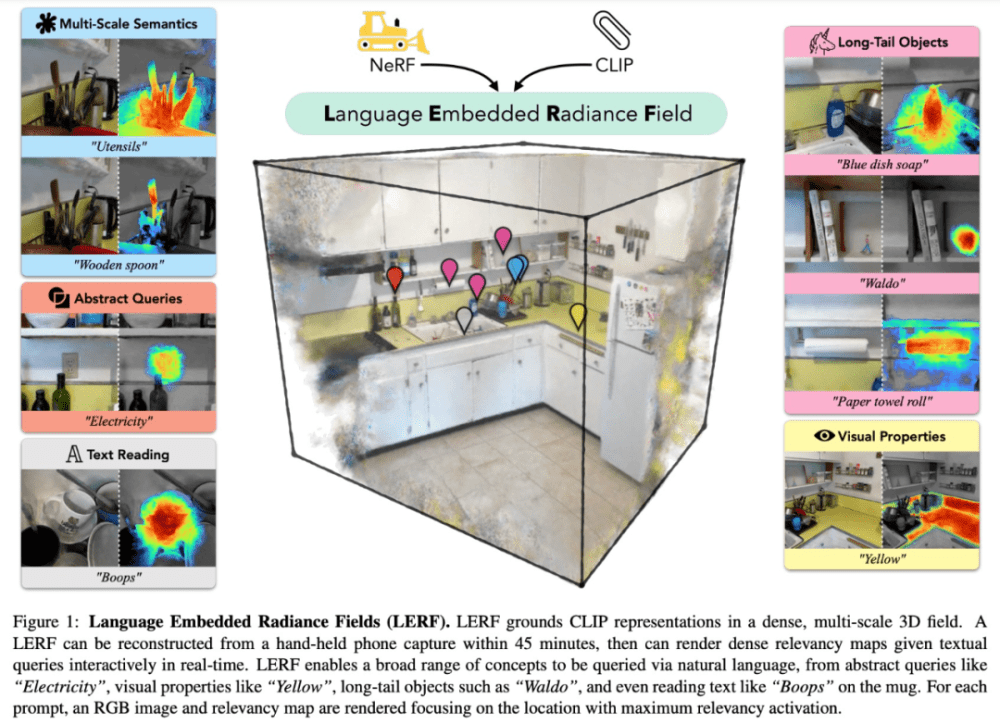
但自然语言不同,自然语言与 3D 场景交互非常直观。我们可以用图 1 中的厨房场景来解释,通过询问餐具在哪,或者询问用来搅拌的工具在哪,以这种方式就可以在厨房里找到物体。不过完成这项任务不仅需要模型的查询能力,还需要能够在多个尺度上合并语义等。
本文中,来自 UC 伯克利的研究者提出了一种新颖的方法,并命名为 LERF(Language Embedded Radiance Fields),该方法将 CLIP(Contrastive Language-Image Pre-trAIning)等模型中的语言嵌入到 NeRF 中,从而使得这些类型的 3D 开放式语言查询成为可能。LERF 直接使用 CLIP,无需通过 COCO 等数据集进行微调,也不需要依赖掩码区域建议。LERF 在多个尺度上保留了 CLIP 嵌入的完整性,还能够处理各种语言查询,包括视觉属性(如黄色)、抽象概念(如电流)、文本等,如图 1 所示。

LERF 可以实时交互地为语言提示提取 3D 相关示图。例如在一张有小羊和水杯的桌子上,输入提示小羊、或者水杯,LERF 就可以给出相关 3D 图:

对于复杂的花束,LERF 也可以精准定位:

厨房中的不同物体:

方法
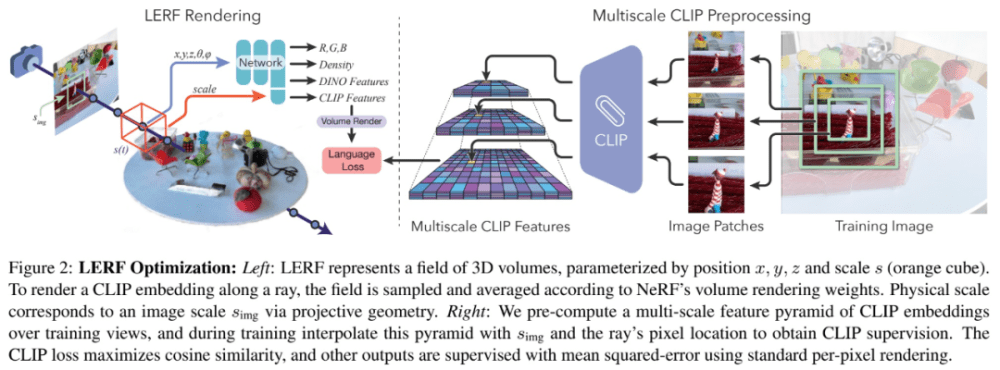
该研究通过与 NeRF 联合优化语言场构建了新方法 LERF。LERF 将位置和物理尺度作为输入并输出单个 CLIP 向量。在训练期间,场(field)使用多尺度特征金字塔(pyramid)进行监督,该金字塔包含从训练视图的图像裁剪(crop)生成的 CLIP 嵌入。这允许 CLIP 编码器捕获不同尺度的图像语境,从而将相同的 3D 位置与不同尺度的语言嵌入相关联。LERF 可以在测试期间以任意尺度查询语言场以获得 3D 相关性映射。
图1
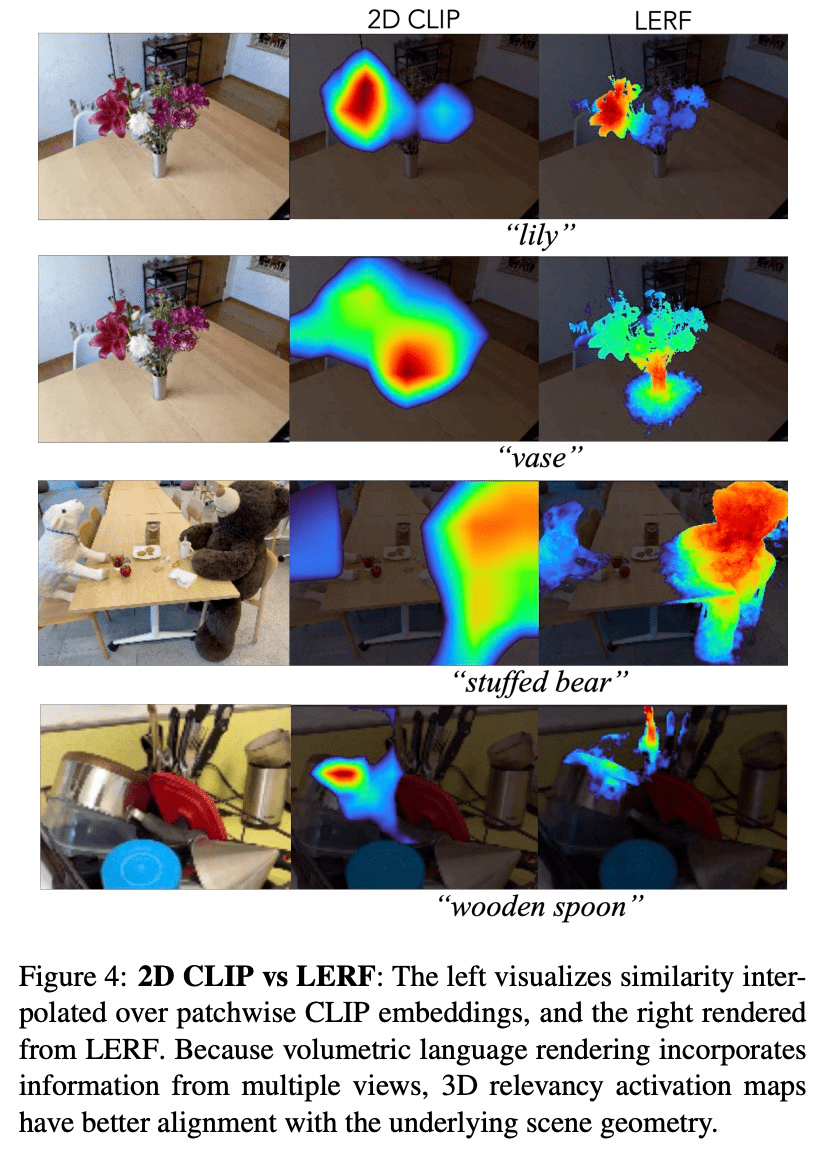
由于从多尺度的多个视图中提取 CLIP 嵌入,因此通过 LERF 的 3D CLIP 嵌入获得的文本查询的相关性映射与通过 2D CLIP 嵌入获得的相比更加本地化(localized),并且是 3D 一致的,可以直接在 3D 场中进行查询,而无需渲染多个视图。
图4
LERF 需要在以样本点为中心的体积上学习语言嵌入场。具体来说,该场的输出是包含指定体积的图像裁剪的所有训练视图的平均 CLIP 嵌入。通过将查询从点重构为体积,LERF 可以有效地从输入图像的粗略裁剪中监督密集场,这些图像可以通过在给定的体积尺度上进行调节以像素对齐的方式呈现。
图2
LERF 本身会产生连贯的结果,但生成的相关性映射有时可能是不完整的,并且包含一些异常值,如下图 5 所示。
图5
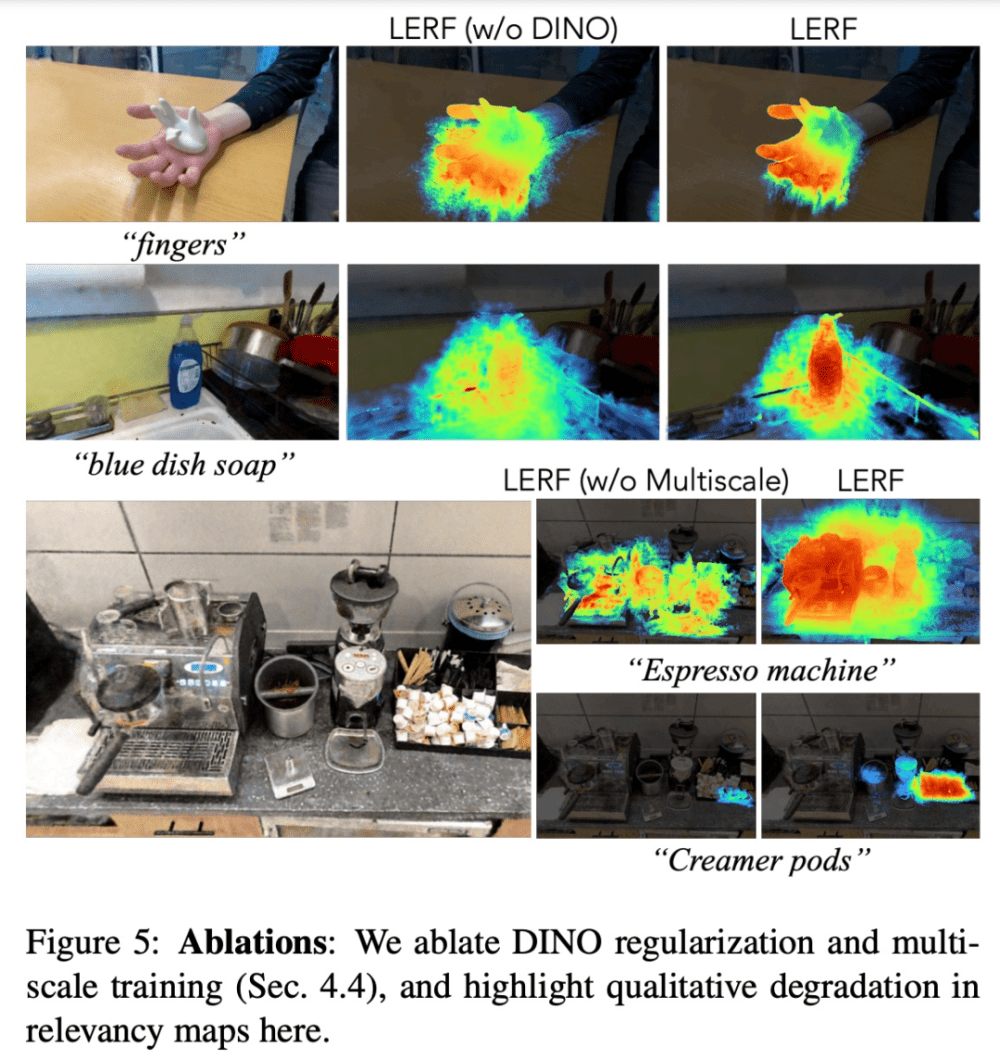
为了规范优化的语言场,该研究通过共享瓶颈引入了自监督的 DINO。
在架构方面,优化 3D 中的语言嵌入不应该影响底层场景表征中的密度分布,因此该研究通过训练两个独立的网络来捕获 LERF 中的归纳偏置(inductive bias):一个用于特征向量(DINO、CLIP),另一个用于标准 NeRF 输出(颜色、密度)。
实验
为了展示 LERF 处理真实世界数据的能力,该研究收集了 13 个场景,其中包括杂货店、厨房、书店、小雕像等场景。图 3 选择了 5 个具有代表性的场景,展示了 LERF 处理自然语言的能力。
图 3。

图 7 为 LERF 与 LSeg 的 3D 视觉对比,在标定碗里的鸡蛋中,LSeg 不如 LERF:
图7

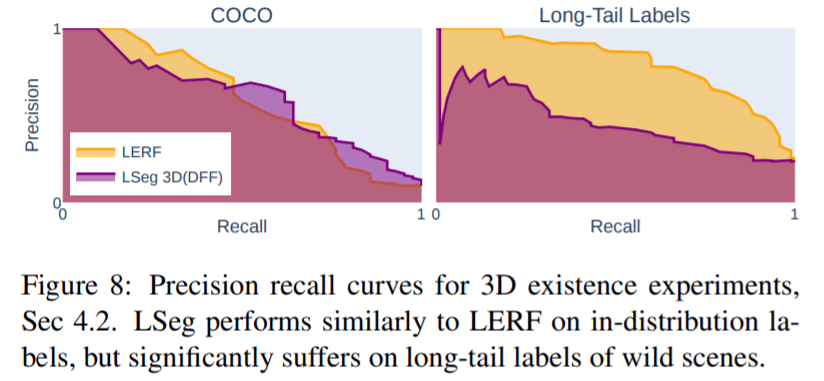
图 8 表明,在有限的分割数据集上训练的 LSeg 缺乏有效表示自然语言的能力。相反,它仅在训练集分布范围内的常见对象上表现良好,如图 7 所示。
图8
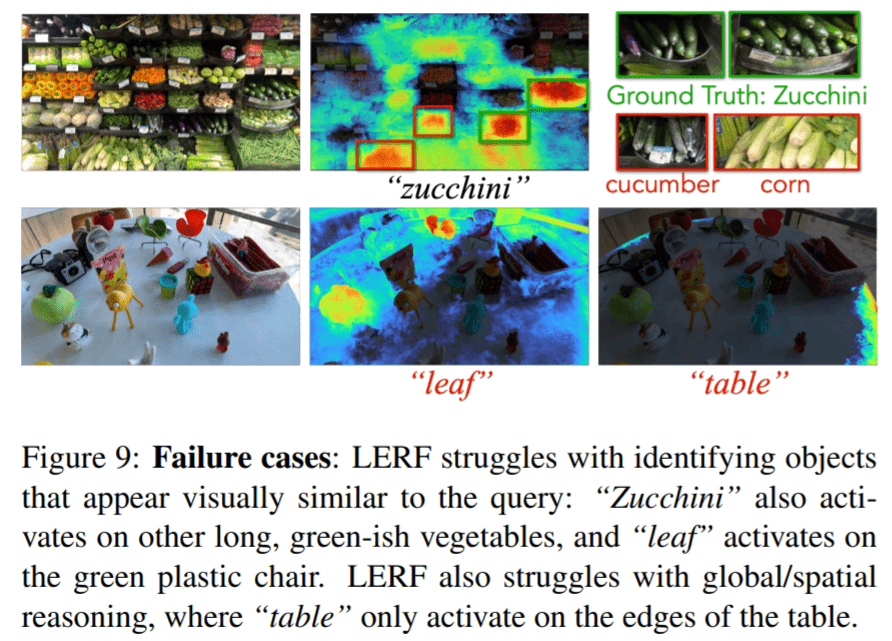
不过 LERF 方法还不算完美,下面为失败案例,例如在标定西葫芦蔬菜时,会出现其他蔬菜:
图9