随着人工智能技术的快速发展,机器学习作为其核心领域之一,也在不断探索更加高效的学习方法。半监督学习作为机器学习的一个重要分支,通过充分利用标记和未标记数据,打破了传统监督学习的限制,为数据驱动的任务带来了全新的可能性。本文将深入介绍什么是半监督学习,以及它在现实世界中的应用和意义。
半监督学习简介
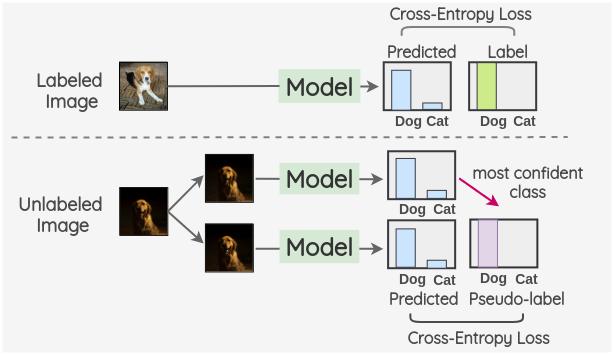
在传统的监督学习中,算法通过标记的数据样本进行训练,从而学习到模式并做出预测。然而,标记数据往往是昂贵和耗时的,限制了监督学习在实际应用中的规模和效果。半监督学习则通过引入未标记数据,将无监督学习和监督学习相结合,从而充分利用数据资源,提高了模型的性能。
半监督学习的工作原理
半监督学习的核心思想是:未标记数据包含了宝贵的信息,可以帮助模型更好地理解数据的分布和结构。在半监督学习中,算法通过利用未标记数据,学习数据的潜在特征,从而更准确地刻画数据之间的关系。这种学习方式有助于模型在面对有限标记数据时,仍能取得不错的预测效果。
半监督学习的应用领域
半监督学习在许多现实应用中发挥着重要作用。以下是一些典型的应用领域:
图像识别:在图像识别任务中,半监督学习可以利用未标记的图像数据,帮助模型识别出数据中的潜在模式,从而提高图像分类、分割等任务的性能。
自然语言处理:在自然语言处理领域,半监督学习可以通过学习文本数据的分布和语义,提高文本分类、情感分析等任务的表现。
异常检测:半监督学习在异常检测中也有广泛应用,通过利用未标记的正常数据,帮助模型更好地识别出异常样本,提高系统的安全性和稳定性。
生物信息学:在生物信息学领域,半监督学习可以帮助科研人员从大规模的未标记生物数据中挖掘出有价值的信息,加速基因组学等研究的进展。
半监督学习的优势和挑战
半监督学习的优势在于它能够在数据有限的情况下,充分利用未标记数据,提高模型性能。同时,半监督学习还可以降低人工标记数据的成本,使机器学习在实际应用中更加可行。
然而,半监督学习也面临一些挑战。首先,未标记数据的质量可能不如标记数据,这可能会对模型的性能产生影响。其次,如何有效地利用未标记数据,设计合适的学习策略也是一个挑战。研究人员正在努力解决这些问题,以推动半监督学习在实际应用中的进一步发展。
总之,半监督学习作为机器学习的一个重要分支,为解锁数据潜力、提高模型性能带来了新的可能性。通过充分利用未标记数据,半监督学习能够在各个领域中发挥重要作用,为图像识别、自然语言处理、异常检测等任务提供更智能化、更高效的解决方案。随着技术的不断进步,相信半监督学习将在未来继续发挥重要作用,推动机器学习的发展和应用。