作者 | Kevin Lu
译者| 弯月
出品 | CSDN(ID:CSDNnews)
自 GPT-4 发布以来,我们一直在尝试让其修改长篇的代码文件。尽管它在解决复杂问题或从零开始创建复杂系统方面表现出色,但在向一个 200 行代码的 Flask 服务器中插入日志时,它却举步维艰。然而,显然后者更为实用。
我们经常听到的一种抱怨是:“ChatGPT 可以完成这项任务,但你们的 Sweep.AI 却不能”。这是因为 GPT-4 并不能一致地编辑长篇文件,它往往会在中途写入“#Rest of the code”,或错误地复制一段代码,而使用ChatGPT的人类可以轻松解决这个算法无法解决的问题。因此,我们不能简单地通过从头开始重写文件的方式来修改文件。
以下是我们做过的所有让 GPT-4 修改文件的尝试,以及由于 GPT-4 未能正确格式化或计数而导致的成功和失败。

版本 0:简单地重写整个文件
如前所述,完全重写文件存在两个主要问题:
1、对于超过 50 行的文件,GPT-4 最终会生成类似“#Rest of the code”的内容。
2、文件太长。拥有 k 个令牌的文件将需要 k 个输入令牌和 k 个输出令牌。
3、GPT-4 会错误地复制代码。它有时会删除或添加额外的注释或空白,或更改缩进。
我们来看一个如何解决第一个问题的示例。
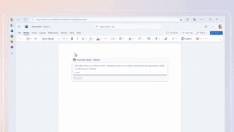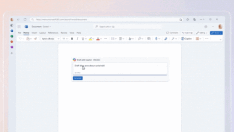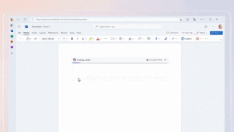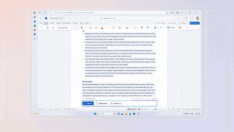
在本文中,我将使用以下简短的 Flask 服务器实现作为我们正在编辑的文件的示例。出于简洁考虑,我选择了一个简短的示例,因此对于这个特定示例,GPT-4 也许不会出现这些错误,但在较大的文件中经常会出现类似的错误。

要求 GPT-4 添加日志,我们可能会得到以下内容:

显然,我们不能仅凭这段代码创建拉取请求(PR)!我们必须撤销所有“#Rest of the code”的修改。
版本 1:使用 difflib 修复“rest of the code”救命稻草 difflib
最简单的解决方案似乎是检查两个文件的差异,并回滚所有带有“Rest of the code”、“Remaining of the code”的部分。
上面示例的差异如下所示:

现在,我们只需撤销每个删除后面带一个形如 + # Rest of test 注释的部分。具体来说,我们使用以下方法检查这些注释:
在这个示例中,它解决了问题:我们最终得到了我们所期望的结果,即在每个函数的开头有一个打印语句。
限制
不幸的是,这个差异回滚系统的能力仍然相当有限。首先,有时 GPT-4 会写下诸如“More unti tests here”,“Complete the implementation”,“...”等注释,有无限多可能。其次,有些情况下,差异算法无法找到具体应当被替换的行。
例如,让我们要求 GPT-4 添加一个删除端点,它的回应是:

但差异算法返回的内容如下:

回滚该差异只会产生:

显然,这完全不是我们所期望的。在 Sweep.AI 的最初几周中,由于这个问题,Sweep 会随机删除大段的代码。
也许我们可以编写一个更智能的差异算法来捕捉这些讨厌的“Rest of code”注释。但即使如此,从算法角度来看,也不可能确定GPT-4的意图是要删除一切并添加新的 delete_task 端点,还是要将 update_task 端点替换为 delete_task 端点。
根本的问题在于,我们无法确定# Rest of code的意思是替换直到 update_task 的所有代码,还是仅仅是替换 create_task 端点。我们需要不同的输入。我们需要让 GPT-4 指出每个替换和修改标签的覆盖范围。
版本 2:以行为单位修改或复制思路
如果可以让 GPT-4 编写一组具体的替换说明,我们就可以用新代码进行替换。最初,我们采用了以下格式:
这段指令的意思是使用新的代码替换从 i(包含)到 j(不包含)的行。
通常,我们更喜欢从 GPT-4 获得基于 XML 的响应,因为它们:
例如,向上面的 Flask API 端点添加更多示例数据,GPT-4 会给出:
而插入新的代码,比如删除端点,GPT-4 会给出:
GPT-4 无法复制行号
当然,我们在提示中添加了代码的行号,以帮助模型正确计数。然而,即便如此,GPT-4 也会复制不正确的行号。这可能导致代码缺失一行或多出一行,如下所示,缺少 return 语句:

或者产生重复的代码行,如下所示:
我们尝试了一些办法,但都无法很好地解决这个问题:
1、删除重复行:如果出现重复较小的行,我们将尝试去除重复行。不幸的是,这并不完全可的,有时会错误删除有意重复的代码。而且它无法处理缺失行的情况。
2、通过另一个模型运行以修复代码:我们将代码输入到 GPT-3.5-16k 中,以验证更改并修复应该修复的内容。不幸的是,这会导致复制中的随机错误,并偶尔出现随机的“#Rest of code”。所以这条路也行不通。
我们还尝试了其他方法,但感觉不太自然,即从文件中复制旧的代码行,然后自然地编写剩下的部分,如下所示:

但同样会受到错误行号的影响。
版本 3:aider diff
这个时候,我们碰巧看到了 aider 创建者的博客文章,aider 是类似于 Sweep 的工具,但是它在本地运行。Aider 要求 GPT-4 生成以下格式的搜索和替换对:
然后只需在代码中搜索原始代码块,并用新代码块替换。例如,为了生成更多的测试数据,它可能生成如下内容:

这种新方法在我们以前的尝试中效果明显更好,我认为主要原因是:
1、对于 LLM 来说,复制代码比选择正确的行号要容易得多。
2、一旦代码被复制到ORIGINAL代码块中,Sweep 就可以非常容易地修改代码,因为 ORIGINAL 原始代码更接近 GPT-4 编写的代码的地方,并且可以用作参考。很有可能,位置嵌入减少了 LLM 在修改代码块过程中的噪声。
这种格式与 git 合并冲突的格式相似,这可能是 GPT-4 的训练数据的一部分。
然而,我们仍然有一些问题:
○最初,我们考虑构建一个模糊匹配算法。然后,我们构建了 V4 来进一步解决这个问题。
○默认情况下,我们会匹配第一个项。
○我们还提示 Sweep 在 ORIGINAL 代码块前后多复制几行以消除歧义。
○此外,通常不建议在多个地方重复使用中等大小的代码块,而是应该使用辅助函数。
○我们提示 GPT-4 进行多个小的更改,而不是较大的更改。
○对于超过 600 行的文件,我们会要求 GPT-4 一次处理 400 行代码。由此产生了一些与上下文相关的问题,但这解决了目前的问题。有关此问题的更多信息,请参见下文。
版本 4:搜索并替换
我们目前的算法是在 Aider diff 的基础上进行了一些扩展。主要问题是,对于中等大小的文件,Sweep 经常会复制错误的行。
Aider diff 存在的问题
例如,如果要求 Sweep 向端点添加日志:

此处,ORIGINAL 代码块中的 create_task 被无意间更改为 start_task。本质上是 GPT-4 错误地复制了行,然后在错误复制的行上应用了转换。
更准确地说,GPT-4 本来想把子字符串 S 替换成 R(S),其中 R: str → str 是需要进行的变换。但是,它生成了 S',然后替换成了 R(S')。这就导致 S 被替换成了 R(S'),这经常会导致代码无法编译,或者导致不可预见的错误。
aider diff 的改进
一个解决方案是更早地开始流式传输,即使用 200 行的块而不是 400 行的块,但这会导致更多的问题,如算法缺少上下文、性能较差和成本较高。
最终我们的解决方案是分别生成 S 和 R(S)。首先让 GPT-4 生成 S',然后通过模糊匹配,在代码中用 S' 搜索 S。然后要求 GPT-4 在 S 上执行相应的变换,这样就生成了 R(S)。
具体而言,新算法执行以下操作:
1、生成一系列的小段代码:S'1, S'2, ..., S'n,供GPT-4编辑,然后使用模糊匹配算法,找到正确的行:S1, S2, ..., Sn。
a.如果模糊匹配对于某个 S'i 产生的相似度分数过低(< 50%),则抛弃。未来也可以向 GPT-4 重新提示该问题。
2、然后将真正的代码片段发给 GPT-4 进行编辑。
因此,我们会要求 GPT-4 生成类似于以下内容:
此时生成省略号(...)是允许的,因为我们的匹配算法通常可以正确匹配代码片段。然后,我们会在代码库中找到真正的代码片段,并呈现给 GPT-4 进行编辑,如下所示:
然后,我们会回复以下内容,要求 GPT-4 进行编辑:
这样可以确保不会出现意外编辑,比如将变量从 create_task 重命名为 start_task。
其他障碍
以下是我们遇到的其他不太重要的障碍:
尽管我们解决了大部分问题,但仍然存在一些文件太长的问题。我们自己的代码库中就有多个超过 1000 行的文件。
结论
让 GPT-4 正确修改代码是一场艰苦的战斗,很容易出现各种错误。自发布以来,我们一直在与这些错误作斗争,但只能缓解常见的错误。
原文链接:https://docs.sweep.dev/blogs/gpt-4-modification