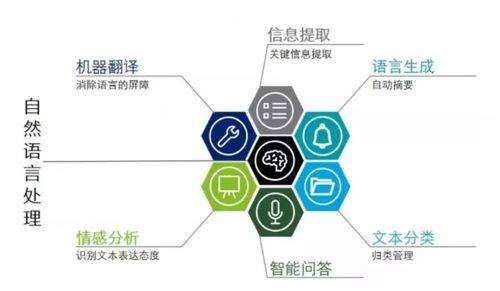
目前,ChatGPT、Llama 2、文心一言等主流大语言模型,因技术架构的问题上下文输入一直受到限制,即便是Claude 最多只支持10万token输入,这对于解读上百页报告、书籍、论文来说非常不方便。
为了解决这一难题,加州伯克利分校受操作系统的内存管理机制启发,提出了MemGPT。该模型的最大创新是模仿操作系统的多级内存管理机制,通过数据在不同的内存层级之间的传输,来打破大语言模型固定上下文的限定。
开源地址:https://Github.com/cpacker/MemGPT
论文:https://arxiv.org/abs/2310.08560

MemGPT主要包含主上下文和外部上下文两大内存类型。主上下文相当于操作系统的主内存,是大语言模型可以直接访问的固定长度上下文窗口。
外部上下文则相当于磁盘存储,保存了主上下文之外的额外信息。MemGPT还提供了丰富的功能调用,允许大语言模型主动管理自己的内存而无需人工干预。
这些功能调用可以将信息在主上下文和外部上下文之间进行导入导出。大语言模型可以根据当前任务目标,自主决定何时移动上下文信息以更好利用有限的主上下文资源。

研究人员在多个测试环境中进行了评估,结果表明,MemGPT可以有效处理远超大语言模型上下文长度限制的文本内容,例如,MemGPT可以处理长度远超过GPT-3.5和GPT-4上下文限制的文档。
当取回的文档数增加时,固定上下文模型的性能受限于取回器的质量,而MemGPT可以通过调用分页机制取回更多文档,其问答准确率也获得提升。
在新提出的多步嵌套关键词提取任务中,MemGPT通过多次调用外部上下文,成功完成了需要跨文档进行多跳查询才能得出解的任务,而GPT-3.5和GPT-4的准确率在嵌套层数增加时急剧下降到0。
主上下文
MemGPT中的主上下文相当于操作系统中的“主内存”,是大语言模型可以直接访问的固定长度上下文窗口。研究人员将主上下文分为三个部分:
系统指令:这部分保存了MemGPT的基本控制逻辑,例如,函数调用模式等,长度固定且只读。
对话上下文:这是一个先入先出的队列,保存了最近的用户交互历史,只读且会在长度超限时裁剪前段对话。
工作上下文:这是一个读写临时存储,大语言模型可以通过功能调用自主向其中写入信息。
需要注意的是,这三个部分合起来,不能超过底层大语言模型的最大上下文长度。
外部上下文
外部上下文保存了主上下文之外的额外信息,相当于操作系统中的“磁盘存储”。外部上下文需要明确的函数调用才能将信息导入主上下文供模型访问,包括以下两种类型:
回溯存储:保存完整的历史事件信息,相当于对话上下文的无压缩版本。
归档存储:通用的读写数据库,可以作为主上下文的溢出空间保存额外信息。在对话应用中,归档存储可以保存有关用户或系统角色的事实、喜好等额外信息。

回溯存储允许检索特定时间段的历史交互。在文档分析中,归档存储可以支持更大的文档集搜索。
自主编辑与检索
MemGPT通过大语言模型产生的函数调用在内存层级之间主动移动数据,实现自主的编辑与检索。例如,可以自主决定何时在上下文之间移动信息,以适应当前任务目标,无需人工参与。

创新点在于系统指令中详细描述了内存体系结构和功能调用方法,指导大语言模型学习使用这些工具管理内存。
大语言模型可以根据反馈调整调用策略。同时,当主上下文空间不足时,系统会提醒大语言模型及时保存重要信息,引导其管理内存。
链式调用
在MemGPT中,各种外部事件会触发大语言模型进行推理,这包括用户消息、系统内存警告、用户交互事件等。
功能调用可以请求获取控制权,从而实现链式调用。例如,检索结果分页浏览时,连续调用可以将不同页面的数据收集到主上下文中。

而Yield调用则会暂停大语言模型,直到下一个外部事件触发才再启动推理。这种基于事件的控制流协调了内存管理、模型推理和用户交互之间的顺畅沟通。
解析器与优化
MemGPT使用解析器验证大语言模型生成的函数调用,检查参数等是否正确。调用后会将结果反馈给模型,这样可以学习调整策略,减少错误。
此外,MemGPT的系统指令可以进行实时更新,以便在不同任务上给模型加入定制化的内存管理指导,实现持续优化。
本文素材来源加州伯克利分校MemGPT论文,如有侵权请联系删除