背景
相信大家在项目中都使用过Lombok,因为能够简化我们许多的代码,但是该有的功能一点也不少。那么lombok到底是个什么呢,lombok是一个可以通过简单的注解的形式来帮助我们简化消除一些必须有但显得很臃肿的 JAVA 代码的工具。
简单来说,比如我们新建了一个类,然后在其中写了几个字段,然后通常情况下我们需要手动去建立getter和setter方法啊,构造函数啊之类的,lombok的作用就是为了省去我们手动创建这些代码的麻烦,它能够在我们编译源码的时候自动帮我们生成这些方法。
那么Lombok到底是如何做到这些的呢?其实底层就是用到了编译时注解的功能。
Lombok如何使用
Lombok是一个开源项目,代码是在lombok中,如果是gradle项目的话直接在项目中引用如下即可。
compile ("org.projectlombok:lombok:1.16.6")
功能
那么Lombok是做什么呢?其实很简单,一个最简单的例子就是能够通过添加注解自动生成一些方法,使我们代码更加简洁易懂。
例如下面一个类。
@Data
public class TestLombok {
private String name;
private Integer age;
public static void mAIn(String[] args) {
TestLombok testLombok = new TestLombok();
testLombok.setAge(12);
testLombok.setName("zs");
}
}
我们使用Lombok提供的Data注解,在没有写get、set方法的时候也能够使用其get、set方法。我们看它编译过后的class文件,可以看到它给我们自动生成了get、set方法。
public class TestLombok {
private String name;
private Integer age;
public static void main(String[] args) {
TestLombok testLombok = new TestLombok();
testLombok.setAge(12);
testLombok.setName("zs");
}
public TestLombok() {
}
public String getName() {
return this.name;
}
public Integer getAge() {
return this.age;
}
public void setName(String name) {
this.name = name;
}
public void setAge(Integer age) {
this.age = age;
}
}
当然Lombok的功能不止如此,还有很多其他的注解帮助我们简便开发,网上有许多的关于Lombok的使用方法,这里就不再啰嗦了。正常情况下我们在项目中自定义注解,或者使用Spring框架中@Controller、@Service等等这类注解都是运行时注解,运行时注解大部分都是通过反射来实现的。而Lombok是使用编译时注解实现的。那么编译时注解是什么呢?
编译时注解
注解(也被成为元数据)为我们在代码中添加信息提供了一种形式化的方法,使我们可以在稍后某个时刻非常方便地使用这些数据。——————摘自《Thinking in Java》
Java中的注解分为运行时注解和编译时注解,运行时注解就是我们经常使用的在程序运行时通过反射得到我们注解的信息,然后再做一些操作。而编译时注解是什么呢?就是在程序在编译期间通过注解处理器进行处理。
- 编译期:Java语言的编译期是一段不确定的操作过程,因为它可能是将*.java文件转化成*.class文件的过程;也可能是指将字节码转变成机器码的过程;还可能是直接将*.java编译成本地机器代码的过程
- 运行期:从JVM加载字节码文件到内存中,到最后使用完毕以后卸载的过程都属于运行期的范畴。
注解处理工具apt
注解处理工具apt(Annotation Processing Tool),这是Sun为了帮助注解的处理过程而提供的工具,apt被设计为操作Java源文件,而不是编译后的类。
它是javac的一个工具,中文意思为编译时注解处理器。APT可以用来在编译时扫描和处理注解。通过APT可以获取到注解和被注解对象的相关信息,在拿到这些信息后我们可以根据需求来自动的生成一些代码,省去了手动编写。注意,获取注解及生成代码都是在代码编译时候完成的,相比反射在运行时处理注解大大提高了程序性能。APT的核心是AbstractProcessor类。
正常情况下使用APT工具只是能够生成一些文件(不仅仅是我们想象的class文件,还包括xml文件等等之类的),并不能修改原有的文件信息。
但是此时估计会有疑问,那么Lombok不就是在我们原有的文件中新增了一些信息吗?我在后面会有详细的解释,这里简单介绍一下,其实Lombok是修改了Java中的抽象语法树AST才做到了修改其原有类的信息。
接下来我们演示一下如何用APT工具生成一个class文件,然后我们再说Lombok是如何修改已存在的类中的属性的。
定义注解
首先当然我们需要定义自己的注解了
@Retention(RetentionPolicy.SOURCE) // 注解只在源码中保留
@Target(ElementType.TYPE) // 用于修饰类
public @interface GeneratePrint {
String value();
}
Retention注解上面有一个属性value,它是RetentionPolicy类型的枚举类,RetentionPolicy枚举类中有三个值。
public enum RetentionPolicy {
SOURCE,
CLASS,
RUNTIME
}
- SOURCE修饰的注解:修饰的注解,表示注解的信息会被编译器抛弃,不会留在class文件中,注解的信息只会留在源文件中
- CLASS修饰的注解:表示注解的信息被保留在class文件(字节码文件)中当程序编译时,但不会被虚拟机读取在运行的时候
- RUNTIME修饰的注解:表示注解的信息被保留在class文件(字节码文件)中当程序编译时,会被虚拟机保留在运行时。所以它能够通过反射调用,所以正常运行时注解都是使用的这个参数
Target注解上面也有个属性value,它是ElementType类型的枚举。是用来修饰此注解作用在哪的。
public enum ElementType {
TYPE,
FIELD,
METHOD,
PARAMETER,
CONSTRUCTOR,
LOCAL_VARIABLE,
ANNOTATION_TYPE,
PACKAGE,
TYPE_PARAMETER,
TYPE_USE
}
定义注解处理器
我们要定义注解处理器的话,那么就需要继承AbstractProcessor类。继承完以后基本的框架类型如下。
推荐一个 Spring Boot 基础教程及实战示例:
https://Github.com/javastacks/spring-boot-best-practice
@SupportedSourceVersion(SourceVersion.RELEASE_8)
@SupportedAnnotationTypes("aboutjava.annotion.MyGetter")
public class MyGetterProcessor extends AbstractProcessor {
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
}
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
return true;
}
}
我们可以看到在子类中上面有两个注解,注解描述如下
- @SupportedSourceVersion:表示所支持的Java版本
- @SupportedAnnotationTypes:表示该处理器要处理的注解
继承了父类的两个方法,方法描述如下
- init方法:主要是获得编译时期的一些环境信息
- process方法:在编译时,编译器执行的方法。也就是我们写具体逻辑的地方
我们是演示一下如何通过继承AbstractProcessor类来实现在编译时生成类,所以我们在process方法中书写我们生成类的代码。
如下所示。
@Override
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {
StringBuilder builder = new StringBuilder()
.Append("package aboutjava.annotion;nn")
.append("public class GeneratedClass {nn") // open class
.append("tpublic String getMessage() {n") // open method
.append("ttreturn "");
// for each javax.lang.model.element.Element annotated with the CustomAnnotation
for (Element element : roundEnv.getElementsAnnotatedWith(MyGetter.class)) {
String objectType = element.getSimpleName().toString();
// this is appending to the return statement
builder.append(objectType).append(" says hello!\n");
}
builder.append("";n") // end return
.append("t}n") // close method
.append("}n"); // close class
try { // write the file
JavaFileObject source = processingEnv.getFiler().createSourceFile("aboutjava.annotion.GeneratedClass");
Writer writer = source.openWriter();
writer.write(builder.toString());
writer.flush();
writer.close();
} catch (IOException e) {
// Note: calling e.printStackTrace() will print IO errors
// that occur from the file already existing after its first run, this is normal
}
return true;
}
定义使用注解的类(测试类)
上面的两个类就是基本的工具类了,一个是定义了注解,一个是定义了注解处理器,接下来我们来定义一个测试类(TestAno.java)。我们在类上面加上我们自定的注解类。
@MyGetter
public class TestAno {
public static void main(String[] args) {
System.out.printf("1");
}
}
这样我们在编译期就能生成文件了,接下来演示一下在编译时生成文件,此时不要着急直接进行javac编译,MyGetter类是注解类没错,而MyGetterProcessor是注解类的处理器,那么我们在编译TestAnoJava文件的时候就会触发处理器。因此这两个类是无法一起编译的。
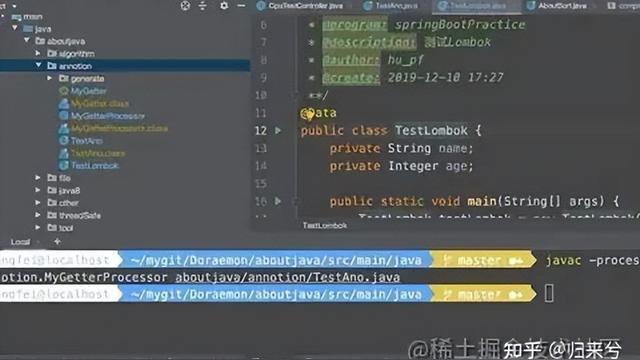
先给大家看一下我的目录结构
aboutjava
-- annotion
-- MyGetter.java
-- MyGetterProcessor.java
-- TestAno.java
所以我们先将注解类和注解处理器类进行编译
javac aboutjava/annotion/MyGett*
接下来进行编译我们的测试类,此时在编译时需要加上processor参数,用来指定相关的注解处理类。
javac -processor aboutjava.annotion.MyGetterProcessor aboutjava/annotion/TestAno.java
大家可以看到动态图中,自动生成了Java文件。