什么是Selenium
01
模拟浏览器:Selenium
我们知道,网页会使用JAVA加载数据,对应于这种模式,可以通过分析数据接口来进行直接抓取,这种方式需要对网页的内容、格式和Java代码有所研究才能顺利完成。但有时还会碰到另外一些页面,这些页面同样使用AJAX技术,但是其页面结构比较复杂,很多网页中的关键数据由AJAX获得,而页面元素本身也使用Java来添加或修改,甚至于人们感兴趣的内容在原始页面中并不出现,需要进行一定的用户交互(如不断下拉滚动条)才会显示。对于这种情况,为了方便,就会考虑使用模拟浏览器的方法来进行抓取,而不是通过“逆向工程”去分析AJAX接口,使用模拟浏览器的方法,特点是普适性强,开发耗时短,抓取耗时长(模拟浏览器的性能问题始终令人忧虑),使用分析AJAX的方法,特点则刚好与模拟浏览器相反,甚至在同一个网站、同一个类别中的不同网页上,AJAX数据的具体访问信息都有差别,因此开发过程投入的时间和精力成本是比较大的。如果碰到页面结构相对复杂或者AJAX数据分析比较困难(如数据经过加密)的情况,就需要考虑使用浏览器模拟的方式了。
在Python/ target=_blank class=infotextkey>Python模拟浏览器进行数据抓取方面,Selenium永远是绕不过去的一个坎。Selenium(意为化学元素“硒”)是浏览器自动化工具,在设计之初是为了进行浏览器的功能测试。Selenium的作用,直观地说,就是使得操纵浏览器进行一些类似普通用户的操作成为可能,如访问某个地址、判断网页状态、单击网页中的某个元素(按钮)等。使用Selenium来操控浏览器进行的数据抓取其实已经不能算是一种“爬虫”程序,一般谈到爬虫,自然想到的是独立于浏览器之外的程序,但无论如何,这种方法有助于解决一些比较复杂的网页抓取任务,由于直接使用了浏览器,麻烦的AJAX数据和Java动态页面一般都已经渲染完成,利用一些函数,完全可以做到随心所欲地抓取,加之开发流程也比较简单,因此有必要进行基本的介绍。
Selenium本身只是个工具,而不是一个具体的浏览器,但是Selenium支持包括Chrome和Firefox在内的主流浏览器。为了在Python中使用Selenium,需要安装selenium库(仍然通过pip install selenium的方式进行安装)。完成安装后,为了使用特定的浏览器,可能需要下载对应的驱动。将下载到的文件放在某个路径下。并在程序中指明该路径即可。如果想避免每次配置路径的麻烦,可以将该路径设置为环境变量,这里就不再赘述了。
通过一个访问百度新闻站点的例子来引入selenium库,代码如下:

运行上面的代码,会看到Chrome程序被打开,浏览器访问了百度首页,然后跳转到了百度新闻页面,之后又选择了该页面的第一个头条新闻,从而打开了新的新闻页。一段时间后,浏览器关闭并退出。控制台会输出“百度一下,你就知道”(对应browser.title)和http://news.bAIdu.com/(对应browser.current_url)。这无疑是一个好消息,如果能获取对浏览器的控制权,那么爬取某一部分的内容会变得如臂使指。
另外,selenium库能够提供实时网页源码,这使得通过结合Selenium和BeautifulSoup(以及其他上文所述的网页元素解析方法)成为可能,如果对selenium库自带的元素定位API不甚满意,那么这会是一个非常好的选择。总的来说,使用selenium库的主要步骤如下。
① 创建浏览器对象,即使用类似下面的语句:
② 访问页面,主要使用browser.get方法,传入目标网页地址。
③ 定位网页元素,可以使用selenium自带的元素查找API,即
还可以使用browser.page_source获取当前网页源码并使用BeautifulSoup等网页解析工具定位:

④ 网页交互,对元素进行输入、选择等操作。如访问豆瓣并搜索某一关键字(效果见图1-9)的代码如下。

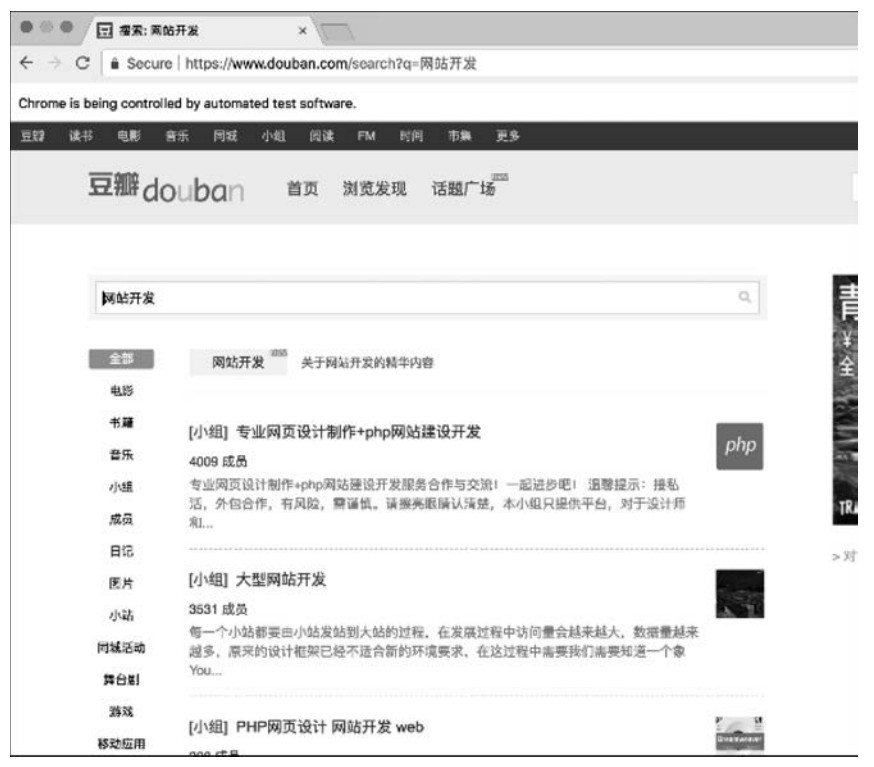
■ 图1-9使用Selenium操作Chrome进行豆瓣搜索的结果
在导航(窗口中的前进与后退)方面,主要使用browser.back和browser.forward两个函数。
⑤ 获取元素属性。可供使用的函数方法很多,例如:
之前曾对Selenium的基本使用做过简单的说明,有了网站交互(而不是典型爬虫程序避开浏览器界面的策略)还能够完成很多测试工作,如找出异常表单、html排版错误、页面交互问题。