图片
图片
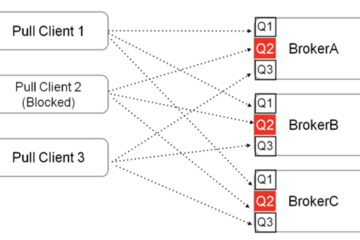
消息中间件MQ(Message Queue)是一种常用的异步通信技术,它通过将消息存储在队列中,实现生产者和消费者之间的解耦。MQ的主要作用是保证消息的可靠传输和幂等性。本质是队列,遵循FIFO先进先出原则。只不过队列中存放的内容是message而已,还是一种跨进程的通信机制,用于上下游传递消息。在互联网架构中,MQ是一种非常常见的上下游“逻辑解耦+物理解耦”的消息通信服务。使用了MQ之后,消息发送上游只需要依赖MQ,不用依赖其他服务。
主要是利用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。
 图片
图片
当前业界比较流行的开源消息中间件包括:ActiveMQ、RabbitMQ、RocketMQ、Kafka、 ZeroMQ等,其中应用最为广泛的要数RabbitMQ、RocketMQ、Kafka这三款。

RabbitMQ是一套开源(MPL)的消息队列服务软件,是由 LShift 提供的一个 Advanced Message Queuing Protocol (AMQP) 的开源实现,由以高性能、健壮以及可伸缩性出名的 Erlang 写成。

优点:
erlang语言开发,性能极其好,延时很低;
吞吐量到万级,MQ功能比较完备;
健壮、稳定、易用、跨平台、支持多种语言、文档齐全;
有消息确认机制和持久化机制,可靠性高;
高度可定制的路由;
社区活跃度高,几乎每个月都发布几个版本。
缺点:
实现了代理架构,意味着消息在发送到客户端之前可以在中央节点上排队。此特性使得RabbitMQ易于使用和部署,但是使得其运行速度较慢,因为中央节点增加了延迟,消息封装后也比较大。
erlang语言开发,很难看懂源码,无法进行源码级别的研究和定制,不利于二次维护和开发。
rabbitmq集群动态扩展比较麻烦。
RocketMQ 出自 阿里公司的开源产品,用 JAVA 语言实现,在设计时参考了 Kafka,并做出了自己的一些改进,消息可靠性上比 Kafka 更好。RocketMQ在阿里集团被广泛应用在订单,交易,充值,流计算,消息推送,日志流式处理,binglog分发等场景。
优点:
缺点:
Apache Kafka是一个分布式消息发布订阅系统。它最初由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log),,之后成为Apache项目的一部分。Kafka系统快速、可扩展并且可持久化。它的分区特性,可复制和可容错都是其不错的特性。
 图片
图片
优点:
客户端语言丰富,支持java、.NET、php、ruby、Python/ target=_blank class=infotextkey>Python、go等多种语言;
性能卓越,单机写入TPS约在百万条/秒,消息大小10个字节;
提供完全分布式架构, 并有replica机制, 拥有较高的可用性和可靠性, 理论上支持消息无限堆积;
支持批量操作;
消费者采用Pull方式获取消息, 消息有序, 通过控制能够保证所有消息被消费且仅被消费一次;
有优秀的第三方Kafka Web管理界面Kafka-Manager;
在日志领域比较成熟,被多家公司和多个开源项目使用。
缺点:
Kafka单机超过64个队列/分区,Load会发生明显的飙高现象,队列越多,load越高,发送消息响应时间变长;
使用短轮询方式,实时性取决于轮询间隔时间;
消费失败不支持重试;
支持消息顺序,但是一台代理宕机后,就会产生消息乱序;
社区更新较慢。
 图片
图片
常用于高并发场景,进行削峰。例如:现在有一个订单系统,高峰期订单量过多,而系统最多只能处理1w次/s。此时可以通过消息队列使得这些超出处理能力的下单请求处于队列中进行等待,而不至于将所有的请求全部一次性打到订单系统中,造成订单系统宕机。这就相当于将实际一秒钟内的订单拆分成多个段来进行处理,这样的处理方式虽然加长了等待时间,但是有缺点总比不能用好。这样可以缓解业务量对系统带来的冲击,避免系统宕机而造成不能使用。
redis缓存预热。缓存预热实际上是将热点数据提前缓存到Redis中进行储存,避免高峰期数据请求直接下达到数据库造成数据库崩溃。同样流量消峰,也是达到此效果,只不过一个针对的是数据库方面,一个针对的是服务层的请求。
参考案例:springBoot对接kafka,批量、并发、异步获取消息,并动态、批量插入库表
 图片
图片
若订单系统耦合调用支付系统、库存系统或者物流系统,一旦这三个系统发生故障,订单系统就会处于不可用的状态。如果转变为用消息队列处理调用请求,可以减少很多问题。当故障发生时,子系统要处理的内存会被缓存在消息队列中,而用户的下单操作还是可以正常完成;故障处理完之后,再处理用户的订单信息即可。整个过程中的故障对于用户来说是无感的,可以提高系统的可用性。
 图片
图片
当A需要调用B,B需要花很长时间来处理调用,A需要得知B何时处理完毕。可以实现的方式很多,但是很不方便。使用消息队列可以很轻松实现。只需要监听B处理完成的消息即可,当B处理完毕,将处理完毕的信息发送给消息队列,之后消息队列将消息反馈给A即可。这样的方式,A既不用循环调用B的查询API,也不需要B提供callback API(回调API),同时B也不用完成这些操作;A还能及时得到B服务处理完成的信息。
参考案例:springBoot对接kafka,批量、并发、异步获取消息,并动态、批量插入库表
 图片
图片
个人建议:对于大部分公司,可以优选选择使用RabbitMQ,其次选择Kafka,相比Kafka,RabbitMQ适合对数据一致性、稳定性和可靠性要求很高的场景,有消息确认机制和持久化机制,可靠性非常高。
 图片
图片