这篇文章,我们聊聊如何应对 RocketMQ 消息堆积。
 图片
图片
消费者在消费的过程中,消费的速度跟不上服务端的发送速度,未处理的消息会越来越多,消息出现堆积进而会造成消息消费延迟。
虽然笔者经常讲:RocketMQ 、Kafka 具备堆积的能力,但是以下场景需要重点关注消息堆积和延迟的问题:
 图片
图片
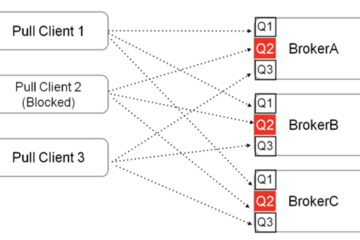
客户端使用 Push 模式 启动后,消费消息时,分为以下两个阶段:
通过以上客户端消费原理可以看出,消息堆积的主要瓶颈在于本地客户端的消费能力,即消费耗时和消费并发度。
想要避免和解决消息堆积问题,必须合理的控制消费耗时和消息并发度,其中消费耗时的优先级高于消费并发度,必须先保证消费耗时的合理性,再考虑消费并发度问题。
影响消费耗时的消费逻辑主要分为 CPU 内存计算和外部 I/O 操作,通常情况下代码中如果没有复杂的递归和循环的话,内部计算耗时相对外部 I/O 操作来说几乎可以忽略。
外部 I/O 操作通常包括如下业务逻辑:
这类外部调用的逻辑和系统容量需要提前梳理,掌握每个调用操作预期的耗时,这样才能判断消费逻辑中I/O操作的耗时是否合理。
通常消费堆积都是由于这些下游系统出现了服务异常、容量限制导致的消费耗时增加。
例如:某业务消费逻辑中需要调用下游 Dubbo 接口 ,单次消费耗时为 20 ms,平时消息量小未出现异常。业务侧进行大促活动时,下游 Dubbo 服务未进行优化,消费单条消息的耗时增加到 200 ms,业务侧可以明显感受到消费速度大幅下跌。此时,通过提升消费并行度并不能解决问题,需要大幅提高下游 Dubbo 服务性能才行。
绝大部分消息消费行为都属于 IO 密集型,即可能是操作数据库,或者调用 RPC,这类消费行为的消费速度在于后端数据库或者外系统的吞吐量,通过增加消费并行度,可以提高总的消费吞吐量,但是并行度增加到一定程度,反而会下降。
所以,应用必须要设置合理的并行度。如下有几种修改消费并行度的方法:
当面对消息堆积问题时,我们需要明确到底哪个环节出现问题了,不要慌张,也不要贸然动手。
首先,我们需要查看消费耗时,确认消息的消费耗时是否合理。查看消费耗时一般来讲有两种方式:
1、打印日志
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
try {
for (MessageExt messageExt : msgs) {
long start = System.currentTimeMillis();
// TODO 业务逻辑
logger.info("MessageId:" + messageExt.getMsgId() + " costTime:" + (System.currentTimeMillis() - start));
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} catch (Exception e) {
logger.error("consumeMessage error:", e);
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}2、查看消息轨迹
 图片
图片
当确定好消费耗时后,可以根据耗时大小,采取不同的措施。
假如消费耗时非常高,需要查看 Consumer 实例 JVM 的堆栈 。
cat stack.log | grep ConsumeMessageThread -A 10 --color常见的异常堆栈信息如下:
 图片
图片
 图片
图片
 图片
图片
客户端使用 Push模式 启动后,消费消息时,分为以下两个阶段:拉取消息和消费消息。
客户端消费原理可以看出,消息堆积的主要瓶颈在于本地客户端的消费能力,即消费耗时和消费并发度。
首先分析消费耗时,然后根据耗时大小,采取不同的措施。
参考文档:
阿里云官方文档:
https://help.aliyun.com/zh/apsaramq-for-rocketmq/cloud-message-queue-rocketmq-4-x-series/use-cases/message-accumulation-and-latency#concept-2004064