上一篇文章讲了高性能编程的工具,这一篇我们基于前面的一些知识点和工具来聊一下linux下的性能优化(本知识点分为两篇,当前主要介绍CPU和内存性能优化)。
 系统调用
系统调用
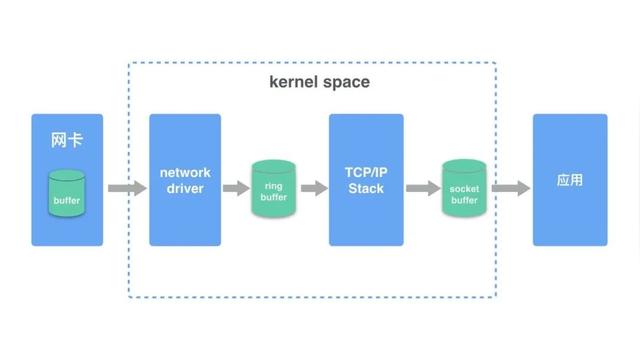
这张图阐述一个应用程序需要经过这些模块调用,对于性能每一部分都可能会有影响,那么我们先需要了解每个模块需要怎么度量?
CPU使用率是最直观描述当前服务状态的情况,如果CPU使用率过高,则表示当前遇到了性能瓶颈,其中过高的这个具体值在线上一般是70%-90%之间,要么扩容服务,要么就排查性能问题。
查看性能工具有很多,最常用的是通过top -p <进程ID>或者通过查看线程top -H -p <进程ID>观察,另外可以使用上一篇的工具:mpstat -P ALL 1 2。
用户进程消耗CPU是常见的情况,往往和业务代码或者使用的库相关,比如大量的循环,JSON解析大包等,在用户代码层有很多耗CPU的操作,都会表现CPU使用率异常,定位其问题可以通过以下方式:
消耗CPU不止用户进程,还包括内核进程,系统调用等内核消耗CPU,可能的原因有大量的内存拷贝,锁,大量的上下文切换等等,具体分析和上面类似:
CPU花费在等待上的时间,主要是看是否大量的IO导致,也可以通过top定位具体进程,然后跟踪和分析该进程或者线程的网络调用情况。
描述的是花费的re-nicing进程上时间占比,主要是更改了进程的执行顺序或者优先级。
平均负载是一个判断系统快慢的重要原因,可能往往不是某个进程引起的,主要有两个指标:
如果被阻塞,平均负载就会增加,可以通过uptime查看,往往负载增加这个时候需要优化代码或者增加机器资源。
当前运行和已经在队列中的进程数,往往进程过多会导致CPU调度繁忙,比如之前多进程的Apache Server,所以可以根据当前CPU的核数决定进程个数,一般繁忙情况下的进程不建议超过2倍CPU(当前空闲的进程也不宜过大,建议不超过10倍)。
阻塞进程是当前未达到执行条件的进程,和上面的CPU等待事件对应,一般是IO问题导致,比如写文件数据过慢,或者socket读写数据未到达等等情况,如何分析呢?可以通过strace跟踪系统调用分析。
在系统上发生上下文切换的情况,也是判断CPU负载的重要因素,大量的上下文切换可能和大量中断或者锁相关,上下文切换会导致CPU的缓存被刷新,数据需要从内存换入换出等。
排查方案是通过perf或者vmstat工具查询,比如vmstat输出(也可以通过vmstat -s查看):
[root@VM-16-16-centos ~]# vmstat 2 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 298404 96824 1189732 0 0 1 34 1 0 0 0 99 0 0
0 0 0 298284 96824 1189736 0 0 0 214 760 1315 1 0 99 1 0其中system包括:CPU在内核态运行信息,包括in中断次数,cs上下文切换次数。
中断包含硬中断和软中断,硬中断是外设处理过程中产生的,通过硬件控制器通知cpu的状态变化,而软中断是通过模拟硬中断的一种信号处理方式,中断过多会导致CPU花费一些时间相应中断,这里也会影响性能,如何排查?通过命令行mpstat -P ALL 5 2可以查看:
[root@VM-16-16-centos ~]# mpstat -P ALL 5 2
Linux 4.18.0-348.7.1.el8_5.x86_64 (VM-16-16-centos) 2023年08月19日 _x86_64_ (2 CPU)
10时02分15秒 CPU %usr %nice %sys %iowAIt %irq %soft %steal %guest %gnice %idle
10时02分20秒 all 0.70 0.00 0.80 0.50 0.00 0.00 0.00 0.00 0.00 98.00
10时02分20秒 0 0.60 0.00 0.80 0.20 0.00 0.00 0.00 0.00 0.00 98.40
10时02分20秒 1 0.80 0.00 0.80 0.80 0.00 0.00 0.00 0.00 0.00 97.60其中输出中包含的:
通过free我们能看到当前内存情况:
[root@VM-0-11-centos ~]# free
total used free shared buff/cache available
Mem: 3880192 407228 713024 872 2759940 3182872
Swap: 0 0 0从上面可以看出,free的内存越大越好,这样有剩余足够多的物理内存可以使用。
Swap如上面说的是交换空间的内存数据,是linux为了释放一部分物理内存将数据临时保存在Swap空间中,通过vmstat -s查看具体信息如下:
[root@VM-16-16-centos ~]# vmstat -s
1860492 K total memory
274936 K used memory
701576 K active memory
707432 K inactive memory
299040 K free memory
96824 K buffer memory
1189692 K swap cache
0 K total swap
0 K used swap
0 K free swap
12318019 non-nice user cpu ticks
124590 nice user cpu ticks
11848347 system cpu ticks
2844992141 idle cpu ticks
4677889 IO-wait cpu ticks
0 IRQ cpu ticks
208152 softirq cpu ticks
0 stolen cpu ticks
15879112 pages paged in
985253486 pages paged out
0 pages swApped in
0 pages swapped out
1330511648 interrupts
260667271 CPU context switches
1678004734 boot time
58996940 forks其中如果pages swapped in和pages swapped out每秒增长很多大,表示内存上遇到了瓶颈,需要升级机器的内存或者优化代码。
在Linux中,伙伴系统是以页为单位管理和分配内存,但是现实的需求却以字节为单位,假如我们需要申请20Bytes,总不能分配一页吧?那岂不是严重浪费内存。那么该如何分配呢?Slab分配器就应运而生了,专为小内存分配而生,Slab分配器分配内存以Byte为单位,但是Slab分配器并没有脱离伙伴系统,而是基于伙伴系统分配的大内存进一步细分成小内存分配,其作用如下:
如果要排查Slab的详细信息,可以通过slabtop或者cat /proc/slabinfo,输出如下(执行slabtop):
Active / Total Objects (% used) : 1074142 / 1101790 (97.5%)
Active / Total Slabs (% used) : 39843 / 39843 (100.0%)
Active / Total Caches (% used) : 100 / 130 (76.9%)
Active / Total Size (% used) : 250498.05K / 253182.16K (98.9%)
Minimum / Average / Maximum Object : 0.01K / 0.23K / 8.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
445302 445302 100% 0.10K 11418 39 45672K buffer_head
249102 249071 99% 0.19K 11862 21 47448K dentry
83616 83557 99% 1.00K 5226 16 83616K ext4_inode_cache
63240 40754 64% 0.04K 620 102 2480K ext4_extent_status
54376 54297 99% 0.57K 3884 14 31072K radix_tree_node
29547 29487 99% 0.19K 1407 21 5628K kmalloc-192
28544 28488 99% 0.06K 446 64 1784K kmalloc-64
21624 21624 100% 0.12K 636 34 2544K kernfs_node_cache
20400 20400 100% 0.05K 240 85 960K shared_policy_node
16276 15989 98% 0.58K 1252 13 10016K inode_cache
10914 10914 100% 0.04K 107 102 428K selinux_inode_security
7776 7776 100% 0.21K 432 18 1728K vm_area_struct
7232 3921 54% 0.12K 226 32 904K kmalloc-128
5376 5376 100% 0.02K 21 256 84K kmalloc-16
5376 5376 100% 0.03K 42 128 168K kmalloc-32
5120 5120 100% 0.01K 10 512 40K kmalloc-8
4344 4306 99% 0.66K 362 12 2896K proc_inode_cache
4096 4096 100% 0.03K 32 128 128K jbd2_revoke_record_s
3822 3822 100% 0.09K 91 42 364K kmalloc-96
3417 3217 94% 0.08K 67 51 268K anon_vma
3344 3344 100% 0.25K 209 16 836K kmalloc-256
3136 3136 100% 0.06K 49 64 196K ext4_free_data
2190 2190 100% 0.05K 30 73 120K avc_xperms_node
2112 2112 100% 1.00K 132 16 2112K kmalloc-1024我们可以从以上的信息中判断那些内核模块内存分配较多(比如OBJ SIZE过大),进而分析模块的性能瓶颈。
以下是我参照USE方法论整理排查性能度量指标流程,其中最大挑战点在于如何发现子模块中的问题并且分析问题?后续可以单独写一篇分析。
 方法论
方法论
#define N 2048
long timecost(clock_t t1, clock_t t2)
{
long elapsed = ((double)t2 - t1) / CLOCKS_PER_SEC * 1000;
return elapsed;
}
int main(int argc, char **argv)
{
char arr[N][N];
{
clock_t start, end;
start = clock();
for (int i = 0; i < N; i++)
{
for (int j = 0; j < N; j++)
{
arr[i][j] = 0;
}
}
end = clock();
cout << "timecost: " << timecost(start, end) << endl;
}
{
clock_t start, end;
start = clock();
for (int i = 0; i < N; i++)
{
for (int j = 0; j < N; j++)
{
arr[j][i] = 0;
}
}
end = clock();
cout << "timecost: " << timecost(start, end) << endl;
}
}先来看一下上面一段代码,有两个timecost输出,大家觉得哪个性能更高呢?运行输出:
timecost: 11
timecost: 67可见第一段代码性能比第二段代码性能高6倍,之前了解过CPU缓存的应该都知道其中的原理!先看看这张图:
 性能
性能
CPU分位多级缓存,每一级比上一级耗时都差几倍,所以如果写的代码读取数据能命令更高级缓存,那么性能自然就会提高,我们再看代码访问array[i][j]和array[j][i ]的差异,array[i][j]是顺序访问,CPU读取数据时,后面的元素已经载入缓存中了,而array[j][i]是间隔访问,可能每次都不能命中缓存,既然明白了缓存的作用,那如何判断我们代码是否由于缓存未命中而损失性能呢?使用工具perf,执行 perf stat -e cache-references -e cache-misses ./a.out,输出如下:
[root@VM-0-11-centos ~]# perf stat -e cache-references -e cache-misses ./a.out
// 第一段代码
Performance counter stats for './a.out':
6,115,254 cache-references
13,450 cache-misses
// 第二段代码
Performance counter stats for './a.out':
913,732 cache-references
17,954 cache-misses因此,遇到这种遍历访问数组的情况时,按照内存布局顺序访问将会带来很大的性能提升。
#define N 128 * 1024 * 10
int main(int argc, char **argv)
{
ofstream ofs;
unsigned char arr[N];
for (long i = 0; i < N; i++)
arr[i] = rand() % 256;
ofs.open("rand", IOS::out | ios::binary);
ofs.write((const char*)arr, N);
ofs.close();
sort(arr,arr+N);
ofs.open("sort", ios::out | ios::binary);
ofs.write((const char*)arr, N);
ofs.close();
{
unsigned char arr[N];
ifstream ifs;
ifs.open("rand");
ifs.read((char *)arr, N);
clock_t start, end;
start = clock();
for (long i = 0; i < N; i++)
{
if (arr[i] < 128)
arr[i] = 0;
}
end = clock();
cout << "timecost: " << timecost(start, end) << endl;
}
{
unsigned char arr[N];
ifstream ifs;
ifs.open("sort");
ifs.read((char *)arr, N);
clock_t start, end;
start = clock();
for (long i = 0; i < N; i++)
{
if (arr[i] < 128)
arr[i] = 0;
}
end = clock();
cout << "timecost: " << timecost(start, end) << endl;
}
}以上代码做了两个操作,:一是循环遍历数组,判断每个数字是否小于128,如果小于则把元素的值置为0;二是将数组排序。那么,先排序再遍历速度快,还是先遍历再排序速度快呢?其输出结果:
timecost: 11
timecost: 3从耗时可以看出排序后的数据性能要比未排序的性能高3倍,为什么?我们可以通过perf stat -e branch-loads,branch-load-misses ./a.out获得输出():
// 第一段代码
Performance counter stats for './a.out':
263,372,189 branch-loads
89,137,210 branch-load-misses
// 第二段代码
Performance counter stats for './a.out':
261,134,898 branch-loads
137,210 branch-load-misses可见分支预测对于性能提升有很大的影响,如果我们遇到类似的问题,可以通过优化代码提升指令缓存的命中率。
从CPU的缓存架构图可以看出,多核的CPU的L1,L2缓存是每颗核心独享的,如果启动某个线程,根据调度时间片,可能线程在某个时刻运行的核心1上,下一个调度时间片可能就在核心2上,这样L1,L2缓存存在不命中的问题,但是如果我们能让线程或者进程独立的跑在一个核心上,这样就不需要将缓存换入缓出,理论上就可以提升性能,在Linux系统中的确提供了这种能力,通过sched_setaffinity可以绑定CPU核心,然后perf查看cpu-migrations的CPU迁移次数发现会减少,这里就不展开代码了,有兴趣的可以研究一下Nginx的worker_cpu_affinity配置,设置Nginx进程与CPU进行绑定的。
SIMD全称single-instruction multiple-data(单指令多数据),在传统的计算机架构中,CPU一次只能处理一个数据元素,但是,许多任务涉及对大量数据执行相同的操作,例如对数组中的所有元素进行加法、乘法或逻辑操作等,SIMD编程通过向CPU提供专门的指令集,使得CPU能够同时对多个数据元素执行相同的操作,这种处理方式特别适合涉及向量、矩阵、图像、音频和视频等数据的计算,使用样例如下:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <emmintrin.h>
#define MAX 200000
#define COUNT 100
void mul_test1(float *buf)
{
for (int i = 0; i < MAX; ++i)
{
buf[i] = buf[i] * buf[i];
}
}
void mul_test2(float *buf)
{
for (int i = 0; i < MAX; i += 4)
{
_mm_storeu_ps(buf + i, _mm_mul_ps(_mm_loadu_ps(buf + i), _mm_loadu_ps(buf + i)));
}
}
int main()
{
float buf[MAX];
for (int i = 0; i < MAX; ++i)
{
buf[i] = (float)(rand() % 1000);
}
{
clock_t start, end;
float duration;
for (int i = 0; i < COUNT; ++i)
{
start = clock();
mul_test1(buf);
end = clock();
duration += ((double)(end - start)) / CLOCKS_PER_SEC;
}
printf("costtime =%.3fn", duration * 1000 / COUNT);
}
{
clock_t start, end;
float duration;
for (int i = 0; i < COUNT; ++i)
{
start = clock();
mul_test2(buf);
end = clock();
duration += ((double)(end - start)) / CLOCKS_PER_SEC;
}
printf("costtime =%.3fn", duration * 1000 / COUNT);
}
return 0;
}从输出来看,SIMD在性能上比通用写法要快很多,如下(这里编译时关闭优化选项g++ O1/O2/O3等,防止编译器优化可以对比出性能):
costtime =0.513
costtime =0.274通常在代码编译期间,编译器会做优化有很多,除了gcc通过-O1 -O2 -O3,内联,尾递归等优化外,现在了解比较多的是PGO和LTO:
PGO优化样例:
#include <time.h>
#include <iostream>
#include <unistd.h>
#include <stdlib.h>
using namespace std;
long m = 502000000;
char arr[4] = {'1', '2', '3', 0};
long timecost(clock_t t1, clock_t t2)
{
long elapsed = ((double)t2 - t1) / CLOCKS_PER_SEC * 1000;
return elapsed;
}
long test()
{
long sum = 0;
int a = 0;
for (a = 0; a < m; ++a)
{
sum += atoi(arr + (a % 2));
}
return sum;
}
int main(int argc, const char *argv[])
{
clock_t start, end;
start = clock();
long sum = test();
end = clock();
cout << "sum: " << sum << ", timecost: " << timecost(start, end) << endl;
return 0;
}
// 执行如下命令:
g++ test5.cc -O2 -o origin
g++ test5.cc -O2 -fprofile-generate -o trace
./trace
g++ test5.cc -O2 -fprofile-use -o optimized
./origin
./optimized
// 输出结果:
[root@VM-0-11-centos ~]# ./trace
sum: 36646000000, timecost: 4710
[root@VM-0-11-centos ~]# g++ test5.cc -O2 -fprofile-use -o optimized
[root@VM-0-11-centos ~]# ./optimized
sum: 36646000000, timecost: 4670
[root@VM-0-11-centos ~]# ./origin
sum: 36646000000, timecost: 4710从输出的结果看提升一小部分性能,如果程序更加复杂,性能提升会更多,如果有兴趣也可以了解关于微软的团队使用Profile Guided Optimization(PGO)和Link-time Optimization(LTO)来优化Linux内核和redis提升性能。
内存池或者对象池是高性能编程一种重要的优化方式,假设在实际代码开发过程中,需要频繁申请和释放内存4个字节的内存,与其把这4字节释放给操作系统,不如先缓存着放进内存池里,仍然当作用户态内存留下来,进程再次申请4字节内存时就可以直接复用,这样速度快了很多,其中ptmalloc,tcmalloc和jemalloc库都是通过类似方式实现,这里为了快速了解,我们直接tcmalloc为例剖析。
 tcmalloc
tcmalloc
从以下代码我们验证一下堆上和栈上分配内存,看看性能对比(这里取出了编译器优化):
void test_on_stack()
{
int a = 10;
}
void test_on_heap()
{
int *a = (int *)malloc(sizeof(int));
*a = 10;
free(a);
}
// 输出如下:
timecost: 258
timecost: 6664可见栈上分配内存性能更高,为什么?这里主要是栈是编译期提前分配好了,而且栈是顺序访问,再者栈的数据可以直接到寄存器映射,还有一个最大的优势是线程在栈是独立的,访问的数据是无需加锁的,所以在实际写代码过程中,对于占用空间少且频繁访问的都可以通过栈上内存分配来操作。顺便说以下,golang为了更好的性能,底层代码中很多都是通过栈分配,当分析非逃逸的变量,即使使用make分配内存也是在栈上(具体可以读读golang的源码)。
多线程情况下,为了保证临界区数据一致性,往往通过加锁解决问题,包括互斥锁,自旋锁,乐观锁等等,当然不同场景的方式不一样,那下面我们来介绍几种高性能情况下锁的使用。
互斥锁:当你无法判断锁住的代码会执行多久时,应该首选互斥锁,互斥锁是一种独占锁,但是互斥锁有对应的问题是:内核会不断尝试获取锁,如果获取不到就会休眠,只有获取到了才会执行逻辑,这里要注意的是在线程获取锁失败时,会增加两次上下文切换的成本,从运行中切换为休眠,以及锁释放时从休眠状态切换为运行中,这种频繁的上下文切换和休眠在高并发服务无法容忍的行为;
自旋锁:通常如果对于一些耗时很短的操作,可以尝试使用自旋锁,自旋锁比互斥锁快得多,因为它通过CPU提供的CAS函数(全称 Compare And Swap),在用户态代码中完成加锁与解锁操作,比如while (!(CAS(lock, 0, args))) { ... },CAS是原子操作,有三个参数(内存位置V、预期原值A、新值B),其中这段代码如果lock==0则更新lock=args,否则继续循环。但是自旋锁会面临ABA的问题(线程1读到A值,但是线程2抢占将A改为B,再修改回A,然后线程1抢占就会认为没有修改,然后继续执行),所以在为了追求高性能,同时也要考虑各个锁的缺点,从而避免BUG;
读写锁:如果业务场景能明确读写,可以选择使用读写锁,当写锁未被锁住时,读锁可以实现多线程并发,当写锁锁住后,读锁阻塞,所以读写锁真正发挥优势的场景,必然是读多写少的场景,否则读锁将很难并发持有;
什么是乐观锁?基于乐观的情况,假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测。
乐观锁常用实现方式通过版本号,每个数据记录都有一个对应的版本号,事务在更新数据时,先读取数据的当前版本号,并在提交时检查该版本号是否发生变化,如果没有变化,说明操作是安全的,可以提交,如果发生变化,就需要进行回滚或重试操作。
从乐观锁的场景可以看出,对于读多写少的情况下,乐观锁是能减少冲突,提升性能。
为了高性能,我们前面提到减少上下文切换,减少临界区冲突,其中锁是最大的障碍之一,如果能通过无锁编程,这样能提升性能。
乐观锁是一种无锁编程,上面已经介绍了,通过版本号或者CAS减少冲突,能实现不加锁;
线程局部变量,通过在GCC定义__thread变量,实现线程局部存储,存取效率可以和全局变量相比,__thread变量每一个线程有一份独立实体,各个线程的值互不干扰,某些场景下可以通过操作线程内的局部变量后,统一同步到全局变量,实现不加锁或者减少锁;
临界区Hash,之前在业务场景中遇到需要频繁操作指定全局数据,但是线程之前操作的数据却在某个时刻是独立,这种场景可以将临界区的数据Hash到各个槽中,当线程需要操作数据,可以先取槽的位置,然后到对应的槽位上操作数据即可,这样减少锁锁住的数据区域或者直接不加锁可以提升性能;
将功能设计为单线程,如果是单线程程序自然就不需要加锁了,比如Redis6.x之前的版本都是单线程处理,这样数据结构简单,避免上下文切换等。