
在不断发展的大型语言模型(LLMs)领域中,用于支持这些模型的工具和技术正以与模型本身一样快的速度进步。在这篇文章中,我们将总结5种搭建开源大语言模型服务的方法,每种都附带详细的操作步骤,以及各自的优缺点。

我们首先介绍门槛最低的入门级方法,因为这个方法不需要GPU,基本上只要有一个还不错的CPU和足够RAM就可以运行。
这里我们使用llama.cpp及其Python/ target=_blank class=infotextkey>Python绑定llama-cpp-python
pip install llama-cpp-python[server]
--extra-index-url https://abetlen.Github.io/llama-cpp-python/whl/cpu创建一个名为models/7B的目录来存储下载的模型。然后使用命令下载GGUF格式的量化模型:
mkdir -p models/7B
wget -O models/7B/llama-2-7b-chat.Q5_K_M.gguf https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGUF/resolve/mAIn/llama-2-7b-chat.Q5_K_M.gguf?download=true然后就可以运行以下命令启动服务器:
python3 -m llama_cpp.server --model models/7B/llama-2-7b-chat.Q5_K_M.gguf将环境变量MODEL设置为下载模型的路径。然后运行OpenAI_client.py脚本就可以访问我们的查询服务器。openai_client.py使用OpenAI库调用LLM服务器并打印响应。
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": "What are the names of the four main characters of South Park?",
},
]因为这个方法是门槛最低的,所以他的速度也是最慢的,基于Intel®Core™i9-10900F CPU @ 2.80GHz的系统的处理时间大概是13秒左右,所以这个方法一般用作我们的本地测试服务(如果你GPU不够的话)。
前面的CPU方法是非常慢的,为了加快速度我们将使用vllm,这是一个专门为有效利用gpu而设计的工具。
pip install vllm执行以下命令来启动服务器:
python -m vllm.entrypoints.openai.api_server --model TheBloke/Llama-2-7B-Chat-AWQ --api-key DEFAULT --quantization awq --enforce-eager这将下载AWK量化模型并启动一个OpenAI兼容服务器,我们可以像使用llama.cpp一样进行查询。
“— enforce-eager”是费差个重要的,因为它允许模型在我的10G VRAM GPU中运行,没有内存不足的错误。
在Nvidia RTX 3080 GPU和Intel®Core™i9-10900F CPU的系统下处理时间只有0.79s。CPU快20倍左右,这就是为什么GPU现在都那么贵的一个原因。
这种方式可以用做我们测试服务器或者在线上的小规模部署,如果要求不高,也可以当作生产环境来使用,当然维护起来非常麻烦。
vllm有很多依赖,如果要批量的安装是一件非常耗时的事情。好在vllm还提供了一个预构建的docker映像,它已经包含了所需的所有库。
对于ubuntu,我们首先安装Nvidia CUDA Toolkit,如果安装了则跳过
sudo apt install nvidia-cuda-toolkit然后添加Nvidia Docker存储库并安装Nvidia Container Toolkit:
distributinotallow=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
sudo systemctl restart docker配置Docker使用Nvidia runtime:
sudo tee /etc/docker/daemon.json <<EOF
{
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
EOF
sudo pkill -SIGHUP dockerd然后就可以运行我们的模型了
docker run --runtime nvidia --gpus all
-v ~/.cache/huggingface:/root/.cache/huggingface
-p 8000:8000
--ipc=host
vllm/vllm-openai:latest
--model TheBloke/Llama-2-7B-Chat-AWQ
--quantization awq --enforce-eager这里我们使用-v参数将本地的磁盘映射到容器中,这样所有的容器都可以使用huggingface的模型缓存,避免了重复下载。
docker的部署方式处理一个查询的时间在0.8s左右与使用相同硬件在Anaconda上运行vllm相似。
使用docker可以大大简化我们服务器的环境配置,配合集群管理脚本可以适用于大规模的服务部署。
上面的方式都适用于本地和有GPU主机/集群的方式,下面我们介绍2个比较简单的云GPU的方案,这两个方案都是按需付费的。
Modal可以简化无服务器应用程序的部署,特别是那些利用GPU资源的应用程序。它的一个突出的特点是它的计费模式,它确保用户只在他们的应用程序使用GPU资源的持续时间内收费。这意味着当你的应用程序不被使用时则不会收费。
Modal还提供每月30美元的优惠,为用户提供了充分的机会来探索和试验部署gpu加速的应用程序,而无需支付前期费用,这也是我们介绍他的一个原因,因为每月目前还能白嫖30美元,哈。
首先安装:
pip install modal然后配置modal的运行环境,这一步需要登陆了
modal setup我们这里的vllm_modal_deploy.py改编Modal的官方教程。这个脚本最重要的一点是定义GPU。这里我选择了nvidia T4,因为量化模型非常小:
# https://modal.com/docs/examples/vllm_mixtral
import os
import time
from modal import Image, Stub, enter, exit, gpu, method
App_NAME = "example-vllm-llama-chat"
MODEL_DIR = "/model"
BASE_MODEL = "TheBloke/Llama-2-7B-Chat-AWQ"
GPU_CONFIG = gpu.T4(count=1)然后定义运行代码的docker镜像:
vllm_image = ( # https://modal.com/docs/examples/vllm_mixtral
Image.from_registry("nvidia/cuda:12.1.1-devel-ubuntu22.04", add_pythnotallow="3.10")
.pip_install(
"vllm==0.3.2",
"huggingface_hub==0.19.4",
"hf-transfer==0.1.4",
"torch==2.1.2",
)
.env({"HF_HUB_ENABLE_HF_TRANSFER": "1"})
.run_function(download_model_to_folder, timeout=60 * 20)
)定义App:
stub = Stub(APP_NAME)最后编写预测的类:
class Model:
@enter() # Lifecycle functions
def start_engine(self):
import time
from vllm.engine.arg_utils import AsyncEngineArgs
from vllm.engine.async_llm_engine import AsyncLLMEngine
print("
声明:本站部分内容及图片来自互联网,转载是出于传递更多信息之目的,内容观点仅代表作者本人,不构成投资建议。投资者据此操作,风险自担。如有任何标注错误或版权侵犯请与我们联系,我们将及时更正、删除。
▌相关推荐
在不断发展的大型语言模型(LLMs)领域中,用于支持这些模型的工具和技术正以与模型本身一样快的速度进步。在这篇文章中,我们将总结5种搭建开源大语言模型服务的方法,每种都附带详...【详细内容】
2024-04-23 Search:
LLM
 Hello folks,我是 Luga,今天我们继续来聊一下人工智能(AI)生态领域相关的技术 - LangChain ,本文将继续聚焦在针对 LangChain 的技术进行剖析,使得大家能够了解 LangChain 实现...【详细内容】
2024-03-07 Search:
LLM
Hello folks,我是 Luga,今天我们继续来聊一下人工智能(AI)生态领域相关的技术 - LangChain ,本文将继续聚焦在针对 LangChain 的技术进行剖析,使得大家能够了解 LangChain 实现...【详细内容】
2024-03-07 Search:
LLM
 编译 | 言征 出品 | 51CTO技术栈(微信号:blog51cto)生成式人工智能是否会取代人类程序员?可能不会。但使用生成式人工智能的人类可能会,可惜的是,现在还不是时候。目前,我们正在见...【详细内容】
2024-03-07 Search:
LLM
编译 | 言征 出品 | 51CTO技术栈(微信号:blog51cto)生成式人工智能是否会取代人类程序员?可能不会。但使用生成式人工智能的人类可能会,可惜的是,现在还不是时候。目前,我们正在见...【详细内容】
2024-03-07 Search:
LLM
 在当今的技术世界中,人工智能正以前所未有的速度发展和演变。这一领域的快速发展得益于先进的机器学习算法、海量数据的可用性以及计算能力的显著提升。特别是,在自然语言处理...【详细内容】
2024-01-02 Search:
LLM
在当今的技术世界中,人工智能正以前所未有的速度发展和演变。这一领域的快速发展得益于先进的机器学习算法、海量数据的可用性以及计算能力的显著提升。特别是,在自然语言处理...【详细内容】
2024-01-02 Search:
LLM
 译者 | 朱先忠审校 | 重楼我相信你听说过SQL,甚至已经掌握了它。SQL(结构化查询语言)是一种广泛用于处理数据库数据的声明性语言。根据StackOverflow的年度调查,SQL仍然是世界上...【详细内容】
2023-12-27 Search:
LLM
译者 | 朱先忠审校 | 重楼我相信你听说过SQL,甚至已经掌握了它。SQL(结构化查询语言)是一种广泛用于处理数据库数据的声明性语言。根据StackOverflow的年度调查,SQL仍然是世界上...【详细内容】
2023-12-27 Search:
LLM
 译者 | 李睿审校 | 重楼生成式人工智能最近的爆发标志着机器学习模型的能力发生了翻天覆地的变化。像DALL-E 2、GPT-3和Codex这样的人工智能系统表明,人工智能系统在未来可以...【详细内容】
2023-12-18 Search:
LLM
译者 | 李睿审校 | 重楼生成式人工智能最近的爆发标志着机器学习模型的能力发生了翻天覆地的变化。像DALL-E 2、GPT-3和Codex这样的人工智能系统表明,人工智能系统在未来可以...【详细内容】
2023-12-18 Search:
LLM
 作者 | Adrien Treuille译者 | 布加迪自从OpenAI发布首个ChatGPT模型以来,人们对生成式AI的兴趣激增。基于大语言模型(LLM)的应用程序现处于企业思考生产力和效率的最前沿,用于...【详细内容】
2023-12-13 Search:
LLM
作者 | Adrien Treuille译者 | 布加迪自从OpenAI发布首个ChatGPT模型以来,人们对生成式AI的兴趣激增。基于大语言模型(LLM)的应用程序现处于企业思考生产力和效率的最前沿,用于...【详细内容】
2023-12-13 Search:
LLM
 大语言模型 (LLM) 压缩一直备受关注,后训练量化(Post-training Quantization) 是其中一种常用算法,但是现有 PTQ 方法大多数都是 integer 量化,且当比特数低于 8 时,量化后模型的...【详细内容】
2023-11-17 Search:
LLM
大语言模型 (LLM) 压缩一直备受关注,后训练量化(Post-training Quantization) 是其中一种常用算法,但是现有 PTQ 方法大多数都是 integer 量化,且当比特数低于 8 时,量化后模型的...【详细内容】
2023-11-17 Search:
LLM
 随着科技的发展和金融市场的变化,投资者们在寻求更有效的投资策略时,开始关注量化投资。LLM量化包作为一种先进的量化投资工具,与传统投资策略相比,具有许多独特的优势。本文将...【详细内容】
2023-11-17 Search:
LLM
随着科技的发展和金融市场的变化,投资者们在寻求更有效的投资策略时,开始关注量化投资。LLM量化包作为一种先进的量化投资工具,与传统投资策略相比,具有许多独特的优势。本文将...【详细内容】
2023-11-17 Search:
LLM
 在当今数字化时代,语言处理技术的重要性日益凸显。大语言模型(LLMs)作为其中的重要分支,已经在多个领域取得了显著的进展。然而,如何将这些模型应用到实际场景中,实现端到端的自动...【详细内容】
2023-11-16 Search:
LLM
▌简易百科推荐
在不断发展的大型语言模型(LLMs)领域中,用于支持这些模型的工具和技术正以与模型本身一样快的速度进步。在这篇文章中,我们将总结5种搭建开源大语言模型服务的方法,每种都附带详...【详细内容】
2024-04-23 DeepHub IMBA Tags:LLM
在当今数字化时代,语言处理技术的重要性日益凸显。大语言模型(LLMs)作为其中的重要分支,已经在多个领域取得了显著的进展。然而,如何将这些模型应用到实际场景中,实现端到端的自动...【详细内容】
2023-11-16 Search:
LLM
▌简易百科推荐
在不断发展的大型语言模型(LLMs)领域中,用于支持这些模型的工具和技术正以与模型本身一样快的速度进步。在这篇文章中,我们将总结5种搭建开源大语言模型服务的方法,每种都附带详...【详细内容】
2024-04-23 DeepHub IMBA Tags:LLM
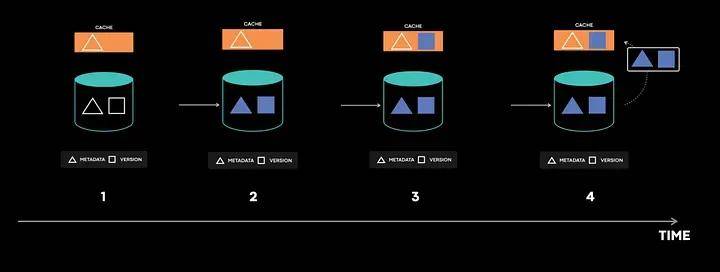 介绍缓存是一种强大的技术,广泛应用于计算机系统的各个方面,从硬件缓存到操作系统、网络浏览器,尤其是后端开发。对于Meta这样的公司来说,缓存尤为重要,因为它有助于减少延迟、扩...【详细内容】
2024-04-15 dbaplus社群 Tags:Meta
介绍缓存是一种强大的技术,广泛应用于计算机系统的各个方面,从硬件缓存到操作系统、网络浏览器,尤其是后端开发。对于Meta这样的公司来说,缓存尤为重要,因为它有助于减少延迟、扩...【详细内容】
2024-04-15 dbaplus社群 Tags:Meta
 前言SELECT COUNT(*)会不会导致全表扫描引起慢查询呢?SELECT COUNT(*) FROM SomeTable网上有一种说法,针对无 where_clause 的 COUNT(*),MySQL 是有优化的,优化器会选择成本最小...【详细内容】
2024-04-11 dbaplus社群 Tags:SELECT
前言SELECT COUNT(*)会不会导致全表扫描引起慢查询呢?SELECT COUNT(*) FROM SomeTable网上有一种说法,针对无 where_clause 的 COUNT(*),MySQL 是有优化的,优化器会选择成本最小...【详细内容】
2024-04-11 dbaplus社群 Tags:SELECT
 这些感悟并非来自于具体的技术实现,而是关于我在架构设计和实施过程中所体会到的一些软性经验和领悟。我希望通过这些分享,能够激发大家对于架构设计和技术实践的思考,帮助大家...【详细内容】
2024-04-11 dbaplus社群 Tags:架构师
这些感悟并非来自于具体的技术实现,而是关于我在架构设计和实施过程中所体会到的一些软性经验和领悟。我希望通过这些分享,能够激发大家对于架构设计和技术实践的思考,帮助大家...【详细内容】
2024-04-11 dbaplus社群 Tags:架构师
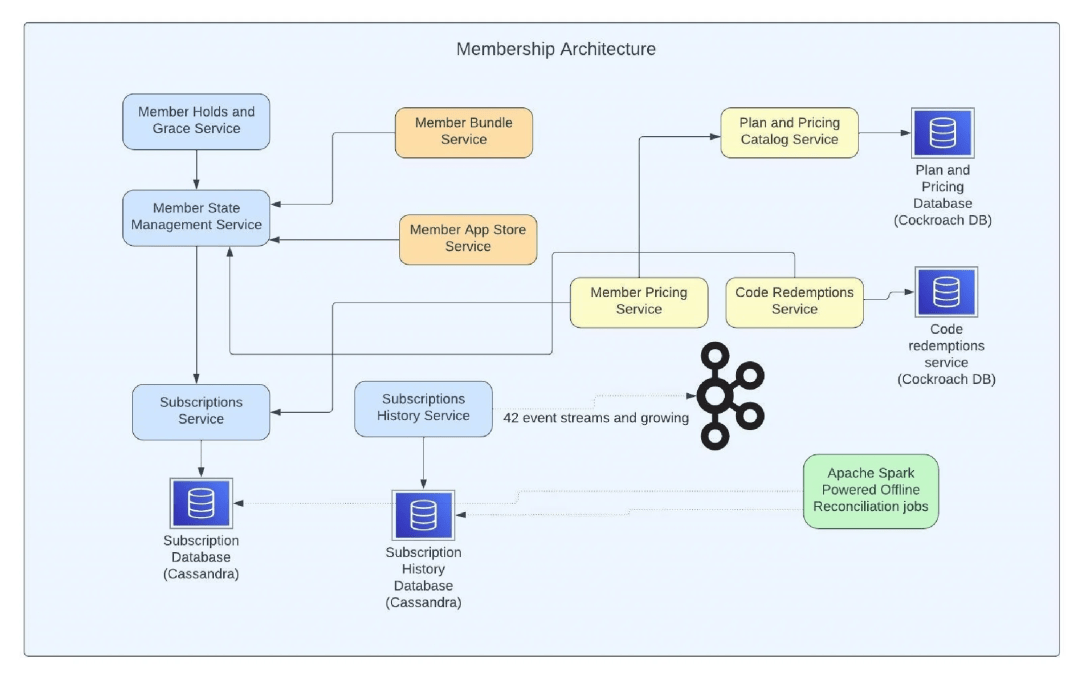 作者 | Surabhi Diwan译者 | 明知山策划 | TinaNetflix 高级软件工程师 Surabhi Diwan 在 2023 年旧金山 QCon 大会上发表了题为管理 Netflix 的 2.38 亿会员 的演讲。她在...【详细内容】
2024-04-08 InfoQ Tags:Netflix
作者 | Surabhi Diwan译者 | 明知山策划 | TinaNetflix 高级软件工程师 Surabhi Diwan 在 2023 年旧金山 QCon 大会上发表了题为管理 Netflix 的 2.38 亿会员 的演讲。她在...【详细内容】
2024-04-08 InfoQ Tags:Netflix
 作者 | Eran Yahav编译 | 言征出品 | 51CTO技术栈(微信号:blog51cto) 时至今日,AI编码工具已经进化到足够强大了吗?这未必好回答,但从2023 年 Stack Overflow 上的调查数据来看,44%...【详细内容】
2024-04-03 51CTO Tags:软件开发
作者 | Eran Yahav编译 | 言征出品 | 51CTO技术栈(微信号:blog51cto) 时至今日,AI编码工具已经进化到足够强大了吗?这未必好回答,但从2023 年 Stack Overflow 上的调查数据来看,44%...【详细内容】
2024-04-03 51CTO Tags:软件开发
 在网页开发中,跳转链接是一项常见的功能。然而,对于非技术人员来说,编写跳转链接代码可能会显得有些困难。不用担心!我们可以借助外链平台来简化操作,即使没有编程经验,也能轻松实...【详细内容】
2024-03-27 蓝色天纪 Tags:跳转链接
在网页开发中,跳转链接是一项常见的功能。然而,对于非技术人员来说,编写跳转链接代码可能会显得有些困难。不用担心!我们可以借助外链平台来简化操作,即使没有编程经验,也能轻松实...【详细内容】
2024-03-27 蓝色天纪 Tags:跳转链接
 曾几何时,中台一度被当做“变革灵药”,嫁接在“前台作战单元”和“后台资源部门”之间,实现企业各业务线的“打通”和全域业务能力集成,提高开发和服务效率。但在中台如火如荼之...【详细内容】
2024-03-27 dbaplus社群 Tags:中台
曾几何时,中台一度被当做“变革灵药”,嫁接在“前台作战单元”和“后台资源部门”之间,实现企业各业务线的“打通”和全域业务能力集成,提高开发和服务效率。但在中台如火如荼之...【详细内容】
2024-03-27 dbaplus社群 Tags:中台
 想必大家都听说过删库跑路吧,我之前一直把它当一个段子来看。可万万没想到,就在昨天,我们公司的某位员工,竟然写了一个比删库更可怕的 Bug!给大家分享一下(不是公开处刑),希望朋友们...【详细内容】
2024-03-26 dbaplus社群 Tags:Bug
想必大家都听说过删库跑路吧,我之前一直把它当一个段子来看。可万万没想到,就在昨天,我们公司的某位员工,竟然写了一个比删库更可怕的 Bug!给大家分享一下(不是公开处刑),希望朋友们...【详细内容】
2024-03-26 dbaplus社群 Tags:Bug
 从字面意思上看,代理就是代替处理的意思,一个对象有能力代替另一个对象处理某一件事。代理,这个词在我们的日常生活中也不陌生,比如在购物、旅游等场景中,我们经常会委托别人代替...【详细内容】
2024-03-26 萤火架构 微信公众号 Tags:正向代理
从字面意思上看,代理就是代替处理的意思,一个对象有能力代替另一个对象处理某一件事。代理,这个词在我们的日常生活中也不陌生,比如在购物、旅游等场景中,我们经常会委托别人代替...【详细内容】
2024-03-26 萤火架构 微信公众号 Tags:正向代理
推荐资讯
相关文章
- 一文解析如何基于 LangChain 构建 LLM 应用
- 有了LLM,所有程序员都将转变为架构师?
- 一文读懂大型语言模型LLM
- SQL应用于LLM的程序开发利器——开源LMQL
- 生成式人工智能潜力的释放:软件工程师的MLOp
- 构建更好的基于LLM的应用程序的四大秘诀
- 解决LLaMA、BERT等部署难题:首个4-bit浮点量
- LLM量化包与传统投资策略的对比分析
- LLMs应用框架:LangChain端到端语言模型
- 什么是 LLM (大型语言模型)以及如何构建LLM?
- 大型语言模型(LLM)技术精要,不看亏了
- 解读大模型(LLM)的token
- StreamingLLM 框架问世,号称“可让大模型处
- LLM的工程实践思考
- RLHF何以成LLM训练关键?AI大牛盘点五款平替
- OpenAI:LLM能感知自己在被测试,为了通过会隐
- 「不要回答」,数据集来当监听员,评估LLM安全
- 当前大语言模型LLM研究的10大挑战
- Open LLM榜单再次刷新,比Llama 2更强的「鸭
- 大模型速度狂飙2.39倍!清华联手微软首提SoT,
站内最新
栏目相关
· 五种搭建LLM服务的方法和代码示例
· Meta如何将缓存一致性提高到99.99999999%
· SELECT COUNT(*) 会造成全表扫描?回去等通知吧
· 10年架构师感悟:从问题出发,而非技术
· Netflix 是如何管理 2.38 亿会员的
· 即将过时的 5 种软件开发技能!
· 跳转链接代码怎么写?
· 中台亡了,问题到底出在哪里?
· 员工写了个比删库更可怕的Bug!
· 我们一起聊聊什么是正向代理和反向代理
· 看一遍就理解:IO模型详解
· 为什么都说 HashMap 是线程不安全的?
· 如何从头开始编写LoRA代码,这有一份教程
· 这样搭建日志中心,传统的ELK就扔了吧!
· Kubernetes 究竟有没有 LTS?
· 三分钟学会负载均衡的重要性与Ribbon集成
· 手把手教你解决推荐系统中的位置偏差问题
· 有了这五个方法,轻松处理异步任务
· Elasticsearch 性能优化详解
· 有了LLM,所有程序员都将转变为架构师?
站内热门
- 从零开始教你安装Oracle数据库
- 一文看懂HMS Core到底是什么
- 什么是VPN
- 做网站渗透测试,可以从哪方面入手?
- 五胡十六国
- 国家划分的艰苦边远地区范围和类别,最全版,终
- SpringBoot事物Transaction实战讲解教程
- 行程码的创始人马晓东
- 电脑键盘不能打字了按哪个键恢复?
- 12306购票时,静、复、智 是什么意思?
- 最全的VPN远程访问内网服务器的设置教程来
- 什么是古法手镯,与普通手镯有什么区别,值得花
- 5款电视上安装的浏览器,你家是哪款?
- 5种方法,教你如何在手机和电脑之间传输文件
- 通过26个实例彻底掌握 linux find 命令的使
- 主板红色的usb接口是干嘛的?
- 教你4种方法检验黄金的纯度,建议收藏
- 天道酬勤、地道酬德、人道酬诚、商道酬信
- 关于警衔你了解多少?人民警察99式警衔详解
- Tik Tok国际版抖音,如何免翻墙、免拔卡使用?
相关头条
· 如何防止被恶意刷接口?
· 主流编程语言哪个更容易学?
· 2024年的后端和Web开发趋势
· GPT-4写代码不如ChatGPT,误用率高达62%!加州大学两位华人开源代码可靠性基准RobustAPI
· 低代码的六大隐患
· 揭穿DevOps的5个谣言!
· 一文搞定高性能API设计
· 开源免费Api软件,你知道几个?
· 最强API调用模型来了!基于LLaMA微调,性能超过GPT-4
· 编程的未来 - 还有未来么?
· 深入了解次世代游戏建模
· ChatGPT的打字回复效果,原理是什么?我带你们实现!
· 推荐九个优秀的 Github 开源项目
· 秒杀自动编码Copilot!「动嘴编程」神器StarChat开源,码农狂喜
· 为什么程序能操控硬件?软件和硬件之间的桥梁是什么?一篇就够
· 纯代码比低代码差在哪里?
· ChatGPT 会“杀死”编程吗?
· 邮件采集筛选:快速找到所需内容的技巧
· 结对编程的十个场景
· 从Lisp到Vue、React再到 Qwit:响应式编程的发展历程
站内头条
- 简易百科财经之CPI跟我们到底有啥关系?
- 简易百科财经:什么是CPI?
- 美联储加息对黄金价格的影响有多大?
- 简易百科之什么是掼蛋?
- 简易百科之什么是站群?
- 简易百科SEO之什么是文章洗稿?
- 简易百科:让百度快速收录文章的排版技巧
- 简易百科是个什么网站?
- 如何避免和女性聊天时尴尬?
- 减少隐私泄露微信需要关闭的功能
- 简易百科:怎样使用手机才能减少隐私泄露?
- 抖音小店店铺主体怎么变更?抖音店铺的营业执
- 简易百科:什么是虚拟现实与增强现实?
- 腾讯QQ浏览器工具权益卡上线PC端,每月最低6
- 拼手气分5亿!支付宝2024年“五福节”活动开
- 美国硅谷历史简介
- 广州放开120平方米以上户型限购 进一步支持
- 证监会今起全面暂停限售股出借 转融券市场
- 融券两新规如何影响A股?融券T+0可用改为T+1
- 中小主播"困"在合同里: 9万粉抖音主播签约M






