作者|李秋键
引言
伴随着计算机视觉的发展和在生活实践中的广泛应用,基于各种算法的行为检测和动作识别项目在实践中得到了越来越多的应用,并在相关领域得到了广泛的研究。在行为监测方面,不仅仅有通过图形、温湿度、声音等信息进行蜂群行为的监测,同时更多的应用是集中在人类行为监测上。而人体姿态识别作为行为监测重要参考依据在视频捕捉、计算机图形学等领域得到了广泛应用。其中传统的人体姿态识别方法有RMPE模型和Mask R-CNN模型,它们都是采用自顶向下的检测方法,而Openpose作为姿态识别的经典项目是采用的自底向上的检测方法,主要应用于行为监测、姿态纠正、动作分类,在智能家居、自动驾驶、智能监控等领域局具有重要的研究意义和应用价值。
在多人目标姿态识别方面,历史上常见的方法有通过自顶而下的候选关键点查找并结合空间联系优化算法匹配人物以及通过建立部分亲和字段的方法实现关键点检测到人体骨架连接等等。
本项目针对当前行为监测中的精度不足、效率较低等问题,结合了openpose的姿态识别技术通过不同肢体之间的协调关系来搭建分类算法,并通过不同的分类算法比较,选择出最优模型搭建多目标的分类方法,最终可以实现多个目标的姿态显示、目标检测和分类的实时显示。在此次的模型中通过调用轻量级的openpose模型进行人体姿态识别,其主要的方法是通过openpose获取人体各个骨骼关键点位置,然后通过欧氏距离进行匹配两个骨骼来具体检测到每一个人,对于常见检测中骨骼关键点的缺失可以通过上一帧的骨骼信息进行填充。
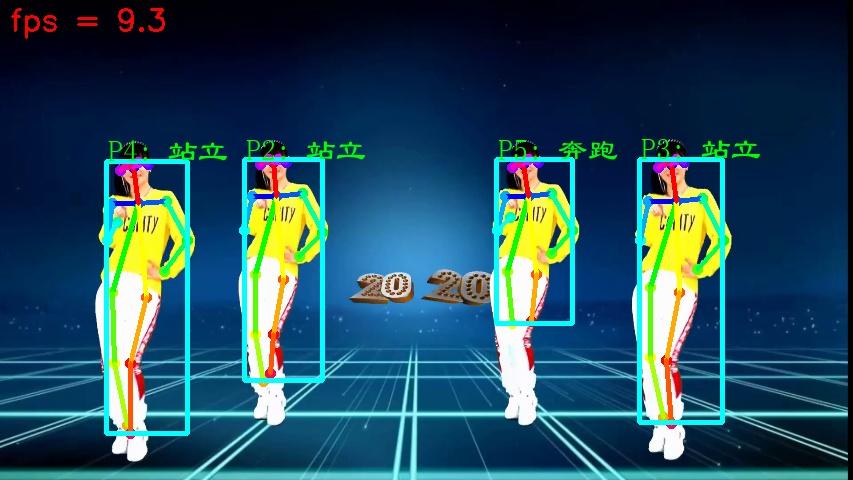
其最终实现效果如下图可见:
系统组成
系统运行的基本流程:
1、利用openpose遍历数据集下不同分类下的人物的姿态信息进行提取作为动作特征并保存为对应的TXT文档。
2、将提取的特征信息和对应的图片对应起来整合在一个TXT文件中。
3、整合TXT信息分别为输入和输出标签csv文件。
4、模型训练部分分别使用不同分类算法达到训练的效果。
1.1 Openpose环境的构建
openpose是依赖于卷积神经网络和监督学习实现人体姿态评估算法,其主要的优点在于适用于多人二维且较为精准和迅速的识别开源模型。
整个多目标动作监测系统的搭建主要是依赖于openpose的姿态识别环境。而openpose的基本环境依赖于Python/ target=_blank class=infotextkey>Python,CUDA和swig的支持,其中python是作为openpose的代码编写和运行工具,CUDA作为调用显卡训练测试的必须软件需要和python版本有一定的关系,swig目的在于给openpose编译环境。根据openpose官方提供的cmu模型、mobil.NET_thin模型、mobilenet_v2_large模型和mobilenet_v2_small模型的评价,我们选择了cmu模型作为姿态识别的调用模型,主要原因在于cmu具有更高一些的识别精度。
Openpose的调用在这里通过调用其中设定好的主函数即可,其中包括模型加载程序、调用程序以及Estimator评估等等。
本文共设定站立、行走、奔跑、跳动、坐下、下蹲、踢腿、出拳、挥手等行为标签,每类行为通过摄像头采集相关视频,并将视频分帧成多张图片,由不同的照片组合形成了不同动作,将其中的姿态特征利用openpose提取作为完整动作的基本识别特征,并将其中的信息整合到txt文件中。其中提取的部分分别包括鼻子、脖子、左右肩、左右手腕、左右膝盖等等。
1.2 数据和特征的处理
数据处理的第一步是将采集到的图片放入openpose骨架提取网络进行提取行人的关键点坐标数据,并将不同分类下的人物的姿态信息进行提取作为动作特征并保存为对应的TXT文档。然后进行特征的整合:将提取的特征信息和对应的图片对应起来整合在一个TXT文件中,同时去除无用的多余数据集。最后整合TXT信息分别作为输入和输出标签csv文件。
其中输入的特征既包含关键点的特征,同时也包括不同骨骼点连接的线特征,以及不同线之间组合形成的面特征。而这些提取的特征将通过下述设定好的分类算法进行提取和学习。
1.3 机器算法设计(简易版本)
首先是特征的提取,利用openpose遍历数据集下不同分类下的人物的姿态信息进行提取作为动作特征并保存为对应的TXT文档。然后进行特征的整合:将提取的特征信息和对应的图片对应起来整合在一个TXT文件中,同时去除无用的多余数据集。最后整合TXT信息分别作为输入和输出标签csv文件。
将从输入端csv读取的人体骨骼信息作为输入,Y标签的csv文件作为输出,按照0.3的比例划分训练集和验证集,并转为numpy矩阵参与运算。其中模型分类器的选择主要按照决策树、随机森林、神经网络和支持向量机进行测试模型效果。模型的评估则主要根据混淆矩阵、精准率、召回率和F1得分进行评估。
1、支持向量机SVM分类器:
SVM是机器学习领域常用的有监督学习模型,常用来进行分类和回归。它是基于结构风险最小化理论建立模型,而达到学习器的全局最优化结果,主要是被用来分析线性可分的情况。参数选择问题作为支持向量机中的一个复杂优化问题,主要目的是求解超参数的最优解,即计算出最佳超平面,这个超平面是将平面分成两部分,其中每一级都位于两侧,在这里通过设定核函数来达到优化参数的目的。
在这里直接调用sklearn框架中搭建好的分类器进行训练,其中设置核函数为线性核函数。惩罚系数C为10,这个惩罚系数的设定一般来说这个系数设置的越大,容错性也就相对小一些,分隔空间的硬度也就更强。
2、决策树Decision Tree分类器:
决策树作为监督学习算法中的常见算法,是属于非参数学习的算法,常常被应用于多分类和回归问题中。它主要是通过计算各种不同情况的概率,在已知概率的基础上,来求解净现值大于等于零的情况。与传统回归模型相比。决策树在识别决策方面更具有优势,同时可以检验变量之间的交互效应以解决多重共线性问题。
这里通过调用sklearn模块下的DecisionTreeClassifier函数进行搭建决策树分类模型,并设置一定的树的深度以进行模型的训练。
3、随机森林RandomForestClassifier分类器:
随机森林是由多个决策树组成的分类器,通过分裂训练数据集进行加载入多个决策树的训练。其随机性主要体现在数据选择的随机性和特征选择的随机性,它使用随机维度选择和抽样,使得决策树更具有随机性,从而保证了算法的准确度和鲁棒性。
这里设置树的数目为100,深度为10,max_features取值为“auto”,即取为n_features的平方根值。
4、神经网络MLPClassifier分类器:
MLPClassifier分类器又被称为多层感知器和人工神经网络。其是输入的特征输入到隐层的神经元,然后隐藏层通过全连接的方式连接输入层,相邻的两层通过RELU激活函数对上一层进行非线性变换,通过反向传播进行调整不同神经元之间的w和b参数来达到训练的目的。而在反向传播的过程中通过随机梯度下降的方法进行模型的收敛。
在这里通过从X端CSV文件数据读入作为输入层,设置隐藏层节点数分别为20,30和40,Y标签数作为输出进行分类建立分类器模型。
2.1 深度算法设计(GUI附加二次检测)
利用keras搭建RNN网络模型,并加入了二次检测,以防止对坐下、摔倒误判。二次检测主要对人体高度和宽度的比例进行对比以判断是否为跌倒动作。部分代码如下:
myfont = ImageFont.truetype(r'C:/windows/SIMLI.TTF', 20)
parser = argparse.ArgumentParser(description='tf-pose-estimation run')
parser.add_argument('--image', type=str, default='Standard/1.jpg')
parser.add_argument('--model', type=str, default='cmu',
help='cmu / mobilenet_thin / mobilenet_v2_large / mobilenet_v2_small')
parser.add_argument('--resize', type=str, default='0x0',
help='if provided, resize images before they are processed. '
'default=0x0, Recommends : 432x368 or 656x368 or 1312x736 ')
parser.add_argument('--resize-out-ratio', type=float, default=4.0,
help='if provided, resize heatmaps before they are post-processed. default=1.0')
args = parser.parse_args()
update_a = ["", "", "", "", "", "", "", "", "", ""]
w, h = model_wh(args.resize)
if w == 0 or h == 0:
e = TfPoseEstimator(get_graph_path(args.model), target_size=(432, 368))
else:
e = TfPoseEstimator(get_graph_path(args.model), target_size=(w, h))
cap=cv2.VideoCapture("shuaidao.mp4")
conditions=[5,6]
num=0
image3 = np.zeros([600, 480, 3])
image3.fill(255)
cv2.imwrite("iimg3.jpg", image3)
image3 = cv2.imread("iimg3.jpg")
image_web4=cv2.resize(image3,(800,480))
image3 = Image.fromarray(cv2.cvtColor(image3, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image3)
dates = str(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'))
draw.text((10, 10), "系统日志:" + dates, font=myfont, fill=(255, 0, 0))
image3 = cv2.cvtColor(np.asarray(image3), cv2.COLOR_RGB2BGR)
简易版本代码:
链接:链接
:https://pan.baidu.com/s/15XFVaF1-K37Awpxc5C4bog
密码:hu1f
GUI二次检测代码:
https://download.csdn.net/download/qq_42279468/22009054