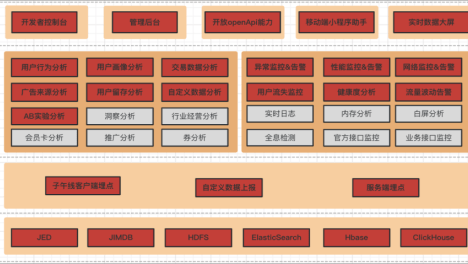
这是一个AI赋能的时代,而机器学习则是实现AI的一种重要技术手段。那么,是否存在一个通用的通用的机器学习系统架构呢?
在老码农的认知范围内,Anything is nothing,对系统架构而言尤其如此。但是,如果适用于大多数机器学习驱动的系统或用例,构建一个可扩展的、可靠的机器学习系统架构还是可能的。从机器学习生命周期的角度来看,这个所谓的通用架构涵盖了关键的机器学习阶段,从开发机器学习模型,到部署训练系统和服务系统到生产环境。我们可以尝试从10个要素的维度来描述这样的一个机器学习系统架构。

在给定的时间内提供高质量的数据,并以可伸缩和灵活的方式生成有用的机器学习特征。一般来说,数据流水线可以与特征工程流水线分离。数据流水线是指提取、转换和加载(ETL)的流水线,其中,数据工程师负责将数据传输到存储位置,比如建立在对象存储之上的数据湖,特征工程流水线侧重于将原始数据转换成可以帮助机器学习算法更快、更准确地学习的机器学习特征。
特征工程一般分为两个阶段。在第一阶段,特征工程逻辑通常由数据科学家在开发阶段通过各种实验创建,以便找到最佳的特征集合,而数据工程师或机器学习工程师则负责特征工程流水线的生产,为模型训练和在生产环境中服务提供高质量的特征数据。
存储机器学习的特征数据,进行版本管理,用于发现、共享和重用,并为模型训练和服务提供一致的数据和机器学习特征,从而提高机器学习系统的可靠性。
面对机器学习的特征数据,特征存储是特征工程流水线创建的持久化存储方案。特性存储支持模型训练和服务。因此,它是一个非常重要的部分,是端到端机器学习系统架构的一个重要组件。
对于机器学习训练运行不同的参数和超参数,以一种简单和可配置的方式进行实验,并记录这些训练所运行的各种参数和模型性能指标。自动评估、验证、选择性能最好的模型并将其记录到机器学习模型库中。
存储并记录机器学习的运行,包括参数、指标、代码、配置结果和经过培训的模型,并提供模型的生命周期管理、模型注释、模型发现和模型重用等功能。
对于一个完整的机器学习系统来说,以工程、模型训练和模型服务为特征,可以从数据中生成大量的元数据。所有这些元数据对于了解系统如何工作非常有用,可以从数据-> 特征-> 模型-> 服务端来提供可跟踪性,并在模型停止工作时提供用于调试的有用信息。
为在生产环境中使用机器学习模型提供适当的基础设施,既考虑到全程服务,也要考虑延迟。
一般来说,有三种服务模式: 批量服务、流式服务和online服务。每种服务类型都需要完全不同的基础设施。此外,基础设施应该是容错和自动扩展的,以响应请求和吞吐量波动,特别是对于关键业务的机器学习系统。
在生产环境中,在发现数据和模型漂移及异常时,提供数据收集、监控、分析、可视化和通知功能,并提供必要的信息协助系统调试。
与特定的机器学习工作流相比,机器学习流水线提供了一个可重用的框架,使数据科学家能够更快地开发和迭代,同时保持高质量的代码并减少生产时间。一些机器学习流水线框架还提供了编排和架构抽象的功能。
工作流编排是集成端到端机器学习系统的关键组件,协调和管理所有这些关键组件的依赖项。工作流编排工具还提供诸如日志记录、缓存、调试和重试等功能。
持续测试和持续集成是指持续用新数据培训新模型,在需要时升级模型性能,并以安全、敏捷和自动化的方式持续为生产环境提供服务并部署模型。
在端到端机器学习工作流的各个阶段,需要嵌入可靠的数据质量检查、模型质量检查、数据和概念漂移检测,以确保机器学习系统本身是可靠且可信的。这些质量控制的检查包括描述统计学、整体数据形状、数据缺失、数据重复、几乎恒定的特征、统计测试、距离指标和模型预测质量,等等。
以上,可以称之为机器学习系统架构的10个要素。在我们的实践中,整个工作流应该保持大致相同,但可能需要对其中某些要素进行调整和定制。
如何对机器学习的系统架构进行调整呢?
如何在产品设计之初精简架构要素呢?
如何在引入机器学习系统系统时,保持原有系统架构的持续性呢?