来源:远川研究所
今年6月,AMD发布了一款专门针对AI需求的最新款芯片:Instinct MI300。
MI300将CPU、GPU和内存封装在了一起,晶体管数量高达1460亿个,接近英伟达H100的两倍。其搭载的HBM(高带宽内存)密度也达到了H100的2.4倍。也就是说,MI300在理论上可以运行比H100更大的AI模型。
受益于AI训练的增长,GPU需求肉眼可见的从游戏市场向高性能计算领域倾斜,就连刚开启GPU产品线的英特尔,也迫不及待的PPT首发了面向高性能计算场景的Falcon Shores架构芯片。
伴随英伟达一路冲向万亿美元市值,资本市场对GPU行业老二的期待值也达到了顶峰。今年以来,AMD股价累计上涨已经超过90%。

英特尔的Falcon Shores,预计2024年推出
然而MI300发布会结束,AMD股价下跌3.6%,反倒是英伟达上涨3.9%。资本市场表达好恶,向来是这么冷酷无情。
原因可能在于,AMD没有在发布会中透露这款芯片的客户,这也是市场对英伟达以外的AI芯片最大的担心。
长期以来,AMD在GPU市场一直被英伟达按在地上反复摩擦,Instinct产品线其实已经迭代了好几年,但相比英伟达的连战连捷,AMD在高性能计算领域的存在感一直比较稀薄。
AI训练打开的市场空间,一度被市场视为AMD与英伟达拉进距离的机会,但事情似乎没那么简单。
离不开CPU,但离得开英特尔
虽说在AI训练上,更擅长大规模并行计算的GPU承担了大部分计算工作,而整个系统仍需要CPU进行调度和统筹。也就是说,尽管GPU的需求量大幅度增加,但CPU仍是必需品。
作为一家同时拥有CPU和GPU设计能力的芯片公司,AMD被看好也不意外。更何况过去几年,AMD在CPU市场连战连捷。
AMD现任CEO苏姿丰在2014年接手,时值推土机架构性能孱弱,让英特尔心安理得的挤牙膏。而在卖掉Imageon后,AMD和拒绝为苹果设计iphone芯片的英特尔一起,完美错过了智能手机的浪潮,公司一片风雨飘摇。
面临多条战线的失血,苏姿丰只能将有限的资源集中在核心的CPU业务上,从苹果请回了架构大师吉姆·凯勒,开始Zen架构处理器的研发。
2017年,Zen架构处理器横空出世,把挤牙膏上瘾的英特尔打了个措手不及。2019年,Zen处理器更换为台积电7nm工艺,此时英特尔10nm工艺姗姗来迟。
虽然英特尔还占据着大部分市场份额,但AMD的反攻速度实在太快,尤其是在服务器市场,几乎是从0杀到了接近20%的市占率。
2023年Q1,AMD的x86处理器市场份额达到了34.6%这一历史峰值[2],这也是AMD市值超过英特尔的重要背景。
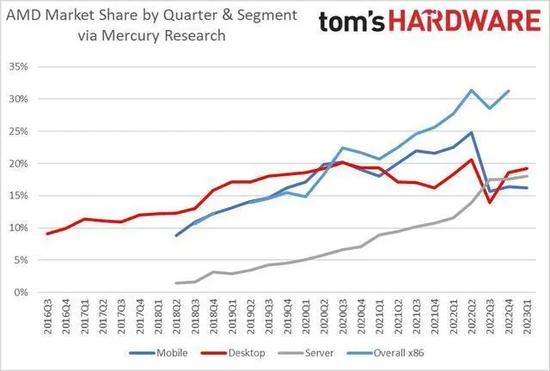
今年5月,全球超级计算机Top500强公布:前500强中,使用AMD CPU进行驱动的超算达到121台,使用英特尔CPU的超算则从2016年的454台下降至360台,虽然看着不少,但其中很多是英特尔10年前的家底——至强(Xeon)处理器[3]。
但同一时期,AMD与英伟达差距也越来越大。
难以逾越的CUDA
英伟达不仅是一流的硬件公司,更是一流的软件公司。
虽然在理论性能上,MI300的一些参数甚至领先于英伟达,但市场对英伟达对手们最大的担心往往在于,就算硬件性能可以跟英伟达比肩,但是软件解决方案仍难以与英伟达的CUDA对抗。
2006年,英伟达推出了CUDA平台,让开发者能够给予GPU进行编程和开发,最终形成了一个庞大稳固的生态。在推出CUDA之前,全球能用GPU进行编程的不足100人,目前CUDA的使用者超过400万。
每一个成功的硬件公司背后,往往都有一个更强大的软件团队,苹果和英伟达都是如此。即便是光刻机制造商ASML也不例外,他们的官方网站上有这样一段话:
您可能将ASML视为一家硬件公司,但实际上我们拥有世界上最大、最具开创性的软件社区之一。如果没有我们开发的软件,我们的客户就不可能制造出10纳米或更小的尺寸的芯片。
想要芯片真正在具体场景的满足各种需求,就需要开发者对硬件进行编程以实现各种功能。如果说硬件编程的过程相当于进行各种复杂计算,那么CUDA就是提供给使用者的一部计算器。
无论对英伟达的刀法多么怀恨在心,都不能否认黄仁勋对通用计算和人工智能的超前押注。
AMD显然深知软件和生态的重要性,但对标CUDA的ROCm在2016年推出时,就已经比英伟达晚了十年。
直到2023年4月,ROCm都仅支持linux平台;而CUDA自问世以来,就提供windows和Linux两个版本,后期还为苹果用户增设mac OS版本。
相比英伟达不遗余力的推广和洗脑,AMD在生态建设上也显得投入不足,据说早年英伟达对项目的GPU试用申请几乎是有求必应,动不动就去高校实验室发显卡。深度学习杰夫·辛顿带着学生训练Ale.NET模型,就用了三块GTX 580。
另外,AMD的软件能力也令人不安——AMD在今年6月发布了一份EPYC 7002 “Rome”服务器芯片指南,承认由于时钟倒计时器存在 BUG,导致第二代EPYC芯片运行1044天后,会出现内核卡死。如果有服务器使用这款芯片,需要每隔2.93年重新启动一次。
原因也不难理解,直到推出ROCm的2016年,AMD甚至还没摆脱亏损。在这期间,AMD只能把有限的资源都聚焦在CPU的研发上,无法为GPU部门投入太多资源,更不要说ROCm的软件团队了。
而当AMD在CPU市场收复失地,希望依靠AI卷土重来时,英伟达已经慢慢补齐了短板。
英伟达的反攻
2020年9月,英伟达宣布准备以400亿美元的价格准备收购移动CPU架构商Arm,其背后意图人尽皆知:一方面是整合移动端资源,另一方面则是入局CPU。
正如前文所说,尽管AI时代需要更多的GPU,但CPU仍不可或缺。当CPU与GPU共同在服务器中的工作时,实际场景更像是一个大学生(CPU)带领一群小学生(GPU)组队完成各种任务。这个时候,配合就显得尤为重要。
因此,英伟达之所以自己做CPU,并非完全因为英特尔或AMD,而是从自身产品需求出发,使CPU和GPU紧密耦合,以发挥最大性能。比如CPU和GPU中,需要用到尽可能相似技术的一致内存,以保证数据之间的无缝共享[8]。
虽然收购基本没有成功的可能性,但英伟达依然按部就班的招兵买马。2021年4月,黄仁勋在自家厨房里宣布,英伟达即将推出首款5nm制程工艺CPU Grace,基于Arm架构,面向超大型 AI 模型的和高性能计算。

紧接着就是具体工作的有序展开:英伟达首先选定了根据地以色列,那里有全球第三多的纳斯达克上市公司(仅次于美国和中国);然后对外招聘600名硬件工程师、软件工程师和芯片设计师,搭建CPU研发团队[7]。
最后,英伟达挖来了英特尔在以色列的CPU架构专家Rafi Marom,后者曾参与10nm制程的Tiger Lake和Alder lake芯片开发工作。
在2022年3月的GTC大会上,英伟达对外宣布Grace CPU性能:拥有144个Arm内核和1TB/s的内存带宽,性能较当前最先进的DGX A100搭载的双CPU相比高1.5倍以上。
不过,原本预计在今年上半年可以开始供货的Grace芯片,目前已推迟至下半年。
APU
Instinct MI300本质上是一颗“APU”,这是AMD早在2009年提出的一个概念——将CPU和GPU集成在一起,使得二者高速互联,实现1+1>2的效果。
在2006年收购了GPU公司ATI后,AMD成为了当时唯一同时拥有CPU和GPU设计能力的芯片公司,而且在两个市场都是行业老二——但坏消息是,市场主流玩家也就两个。
在这种局面下,AMD希望借助APU打开市场局面。2011年,第一代APU推出后,AMD持续宣传APU是“x86架构三十年来的最大革命”,并向投资者强调,这款产品存在着“强劲且被压抑”的需求。
市场最初也对APU概念充满期待,结果2012年Q3财报出炉,AMD收入下滑25%,顺便减记了1亿美元的库存——APU需求量并不高,芯片根本卖不出去[1]。紧接着,公司股价跌到1.86美元的历史性低点,苏姿丰临危受命,开始掌舵风雨飘摇中的AMD。
APU的优势在于,由于CPU和GPU集成在了一起,数据传输效率得到了大幅度提高。苹果的M1 Ultra也采用了类似的“把几个小芯片拼成一块大芯片”的思路,换来了更强的数据吞吐能力。
但在2009年,APU的理念显得过于超前。
一方面,APU涉及芯片的先进封装技术,在当时既不成熟,成本也难以控制。另一方面,APU在需求高度多元化的消费市场很难行得通。
比如10种型号的CPU和GPU,理论上有100种组合方案,这就导致做10种方案无法满足市场需求,做100种方案难以收回生产成本。
因此在很长一段时间里,APU只能在PS4游戏机这类高度标准化的产品上才能找到市场。但深度学习的大爆发改变了这一点。
相比游戏和渲染,AI训练对算力和数据吞吐效率的需求成百上千倍的增加,目前针对AI市场推出的芯片产品,除了算力的堆砌,往往都采用3D堆叠和先进封装等方式,增加数据传输的效率,这与APU的优势不谋而合。
英特尔尚未正式发布的Falcon Shores,同样采用了将CPU、GPU、内存封装在一起的思路,只不过英特尔将其称为“XPU”。
但目前来看,最接近这个目标的反而是英伟达的Grace Hopper芯片。

英伟达的Grace Hopper将CPU和GPU集成在了一起
尾声
在2009年APU的概念被提出时,AMD正经历公司历史上的最低谷,APU多少有些毕功一役的憋大招成分。
但也正是因为处于低谷,导致AMD无法拿出足够的资金与技术支持,让APU的革命性理念真正落地,最终只变成了简单的CPU+GPU的组合。
从商业角度看,最适合在2009年搞点革命性产品的反而是富可敌国的英特尔,但英特尔当时在干什么呢——心安理得的挤牙膏,同时拒绝为iPhone设计芯片。
这似乎是高科技公司常常会出现的状况——在鼎盛年代忽视新的技术浪潮,在低谷期如梦方醒仓促憋大招。
事实上,英特尔还尝试过“联A抗N”——2017年,英特尔宣布将在自家CPU上集成AMD的GPU,合作推出新的芯片。
结果没过多久,英特尔就挖走了AMD的核心技术负责人之一:图形主管Raja Koduri,为英特尔开发高端独立GPU。

参考资料
[1] AMD: $30 Million Settlement Ends Llano Lawsuit,tom's Hardware
[2] AMD and Intel CPU Market Share Report: Recovery on the Horizon (Updated),tom's Hardware
[3] AMD Now Powers 121 of the World's Fastest Supercomputers,tom's Hardware
[4] A Closer Look at Intel’s Coral Supercomputers Coming to Argonne,inside HPC
[5] Argonne’s 44-Petaflops ‘Polaris’ Supercomputer Will Be Testbed for Aurora, Exascale Era,HPC wire
[6] Top500: No Exascale, Fugaku Still Reigns, Polaris Debuts at #12,HPC wire
[7] 英伟达在以色列组芯片团队,发力CPU,半导体行业观察
[8] 它们需要基于这两种设备中尽可能相似技术的一致内存,智能计算芯世界
编辑:李墨天
视觉设计:疏睿
责任编辑:李墨天
研究支持:何律衡